1. 引言
催化裂化作为一种重要的石油炼制方法,在石油化工厂中有着举足轻重的地位,仍然是炼油业务的核心关键技术 [1] 。催化裂化装置的建模方法主要可分为两类:机理建模和数据驱动模型。机理建模,也称为机理驱动模型或知识驱动模型,依赖于数学、物理和化学的公式与定理,通过分析工业系统的内部机制来构建模型。Bollas [2] 等在模拟流体催化裂化(Fluid Catalytic Cracking, FCC)操作时,对反应动力学、流体力学和催化剂失活等因素进行深入理解的重要性,并基于实验数据开发了聚合模型,通过考虑选择性催化剂失活,提高了对FCC产品分布的预测准确性,证明了该方法的有效性。John [3] 等将催化裂化装置的瓦斯油裂化成柴油、汽油、液化石油气、干气和焦炭的六类建立了一套六集总动力学模型,以与工业数据相比较低的误差预测催化裂化装置的提升管分布。Nazarova [4] 等开发了一个涉及C13-C40烃、汽油组、气体单个烃和焦炭形成反应等高分子量的新动力学模型,通过使用具有较高沸点的油馏分来预测原料碱膨胀下的催化裂化装置,有效的改进和预测石油燃料生产的不稳定过程。Yang [5] 等人提出了一种结合动态模型与深度学习的催化裂化装置混合预测策略。首先,他们构建了一个综合的动态模型,该模型由8个子模型构成。随后,他们利用原料油的数据作为主要输入到神经网络中,并将动态模型的预测输出作为额外输入。通过比较仅使用同等结构神经网络的情况,发现预测误差减少了9%,这验证了所提方法的优越性。
与机理建模相比,数据驱动建模(Data-driven Model) 通过模型的结构和参数通常是通过对大量现有数据进行分析、学习和统计推断来确定的,而无需基于物理原理或先验知识的建模。模型预测控制(Model Predict Control, MPC)自从上世纪80年代起在石油化工领域得到应用,是一种多变量的进阶过程控制方式,通过减少预测结果和期望输出的差距,从而寻找到最优的输入输出映射方程 [6] 。Abou-Jeyab等通过线性规划(Linear Programming, LP) [7] 方式使得催化裂化装置模型预测控制的约束问题无需分解,提高了传统优化问题中模型预测控制性能。Jerez等提出了一种可以处理具有输入、输入速率和软状态约束的线性二次模型预测控制(Model predictive control, MPC) [8] 问题的快速MPC算法,相比于之前模型预测算法在性能上有了提升。近年来随着机器学习的发展,催化裂化装置建模中出现了越来越多与机器学习算法相结合的方法。Chen等将智能特征选择策略与随机森林(Random Forest, RF) [9] 相结合用于对催化裂化装置进行建模,用来预测产品收率,通过在轻柴油、重柴油、汽油以及干燥气体四种场景下AIGA-RF模型均方误差和相关系数R2优于其他模型,证明这种方式能够消除过程扰动变量并且适用于不同场景。肖强 [10] 等使用(Radial Basis Function, RBF)网络来预测催化裂化装置中重汽油馏分加氢产品硫含量,该方法预测的平均相对误差达到1.32%,证明了模型的准确性。陈延展 [11] 等利用极度梯度提升树(eXtreme Gradient Boosting—XGBoost)和改进灰狼优化算法预测辛烷值损失,准确率达到了99.81%。因此,证明了基于数据驱动的机器学习和神经网络算法对催化裂化装置的建模方式是有效的。
在实际工业过程中,过程监控变量通常是高维、非线性的时间序列,监控的变量往往受到多种因素的影响,并且这些因素之间可能存在复杂的相互作用 [12] 。但是过程特征和跨系列相关性可以通过特征提取技术捕获,并将它们转化为可用于建模和预测的形式 [13] 。这样的特征提取过程可以为时序预测提供有价值的信息 [14] 。近年来,基于深度学习的方法在这方面取得了显著进展 [15] 。同时,催化裂化装置面向产品质量或收率的过程数学建模分析一直是石油加工领域的关注焦点和挑战 [16] 。
目前,通过基于过程工业中测量和存储的大量数据构建预测模型,这种数据驱动方式已成为研究热点 [17] 。Michalopoulos等人提出一种用于流体催化裂化(FCC)装置的前馈神经网络模型,利用人工神经网络技术成功地对FCC过程的高度非线性行为进行建模 [18] 。Yang等人考虑到各种变量的收集特征,使用神经网络结构来处理不同时间尺度的输入变量,通过堆叠不同时间尺度的LSTM进行以提取时间和空间特征 [19] 。
工业时间序列变量大多存在空间维度以及时间维度的特征,仅考虑一方面的情况可能会导致预测效果不理想,而且大多数是高维和非线性的时间序列。针对这一问题本文提出一种采用并行结构的多头注意力机制(Parallel structure Multi-Head Attention mechanism, PMHA) CNN-BiLSTM-XGBoost神经网络模型对于催化裂化装置产率预测的方法。首先,通过多头注意力机制加强对数据的时间信息的处理能力。其次,利用CNN-BiLSTM对多维时间序列数据进行预处理,能够有效捕获空间信息特征;然后,通过并行结构PMHA-CNN-BiLSTM模型进一步提高了模型增强了对于高维和非线性数据的处理能力;最后,使用XGBoost模型对预测结果进行微调,提高了预测性能。
2. 工作原理
2.1. 预测问题的表述
在催化裂化(FCC)工艺中,对生产数据和中间变量的实时监测对于维持生产过程的效率和安全性至关重要。因此,传统机理建模方法的研究对于催化裂化工业实践具有重大意义。然而,FCCU反应再生系统机理模型是一个复杂的多变量模型,具有非线性和强耦合的特征。在先进控制领域,研究人员在短期内难以掌握化工过程复杂的偏微分方程和代数方程。因此,越来越多的先进控制领域研究人员采用神经网络技术构建了简化的FCCU反应再生系统模型。这种方法能够利用大量生产数据快速学习复杂的非线性关系,从而为控制方案的验证提供了模型。为验证PMHA-CNN-BiLSTM-XGBoost催化裂化装置在产品产率预测方向的应用。我们将FCC单元视为一个整体,并将其定义为多输入多输出(Multiple Input Multiple Output, MIMO)系统如图1所示。输入变量主要包括三大类:原料、温度和压力,这是影响产品收率的主要因素。输出变量产品流量主要包括汽油(Gasoline, GSL)、液化气(Liquefied Petroleum Gas, LPG)、干气(Gas, GS)以及柴油(Diesel Oil, DO),以此构建FCCU反应再生系统简化模型。

Figure 1. Multiple input multiple output system structure
图1. 多输入多输出系统结构
本章提出一种基于Seq2Seq (Sequential to Sequential)框架,构建CNN-BiLSTM混合神经网络模型,如图2整体框架流程图所示。首先对产品产率进行数据预处理,同时输入进料量、温度以及压力等变量之后得到特征矩阵。然后,对特征矩阵进行数据集的划分以及归一化处理。其次,将预处理后的数据传入Sep2Sep框架中并通过XGBoost进行微调。最后,通过反归一化得到预测输出值。通过相关试验,证明了本文所建立的FCC反再系统的预测模型是可行的,并在催化裂化反应再生系统仿真上进行了应用。
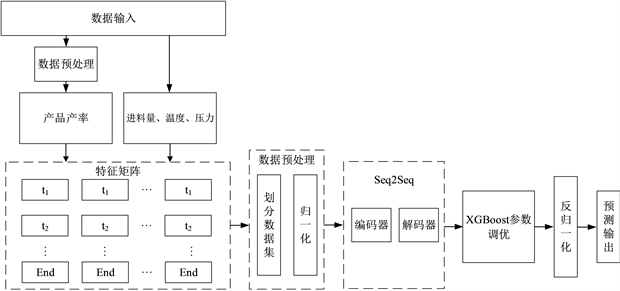
Figure 2. PMHA-CNN-BiLSTM overall framework flow chart
图2. PMHA-CNN-BiLSTM整体框架流程图
2.2. Seq2Seq + Fine Tuning框架
Seq2Seq是一种将序列数据转化为序列数据的神经网络结构,最初是用于进行文本翻译和对话生成等工作。由于Seq2Seq解决序列转序列问题的特性,后Seq2Seq也被逐渐应用于时序数据预测的领域。Seq2Seq + Fine tuning的结构如图3所示。
在预训练模式Sep2Sep中,输入顺序和输出顺序数据表示输入序列数据,编码器(Encoder)表示编码器,C (编码器)表示隐态,Decoder表示译码器。Seq2Seq典型地由编码器和解码器两部分构成。编码器是一种基于属性的卷积神经网络,它能高效地捕获序列间的内在联系,它是一个或几个以上的神经网络叠加而成的。Decoder是一个双线性短时记忆模型,它的输出是一系列编码器所学到的特征集合。由于在某些特定的任务或领域,通用的预训练模型可能无法获得最佳性能。Fine-tuning是一种迁移学习技术,本文通过使用XGBoost在预训练模型的基础上对特定任务进行微调,以提高模型在该任务上的性能。该框架结合了Seq2Seq模型的序列建模能力和Fine-tuning技术的迁移学习优势,通过灵活调整模型结构和微调策略,可以在催化裂化装置产品产率预测任务上取得较好的效果。
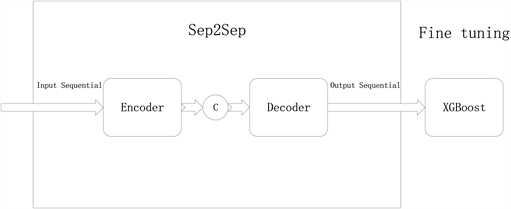
Figure 3. Seq2Seq + Fine tuning framework structure
图3. Seq2Seq + Fine tuning框架结构
2.3. PMHA-CNN-BiLSTM
基于常规网络在预测时出现的问题,本文提出了一种基于Seq2Seq的催化裂化装置的预测模型 PMHA-CNN-BiLSTM,其结构如图4所示。
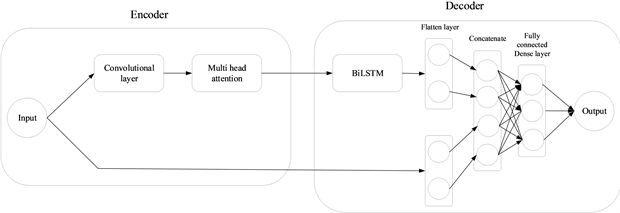
Figure 4. PMHA-CNN-BiLSTM structure
图4. PMHA-CNN-BiLSTM结构
其中输入部分是一段时间序列数据,编码器由Multi Head Attention based CNN构成,解码器为BiLSTM网络组成。为了解决基于单向结构实现的多变量预测时,模型预测结果不理想的问题。Multi Head Attention based CNN主要对整体的结构进行了改进。由于整体网络模型采用一个并行结构(Parallel Structure)的方式,加入原始数据的输入,进而由编码器传入的隐藏层状态,将两部分的信息整合至一个全连接网络,最后将输入数据的最终表示形式传入到密集层以产生预测输出。这种结构保留原始数据的端对端形式可以有助于模型可以更好地理解输入数据的多样性和复杂性,从而提高模型预测处理高维非线性数据的能力。
3. 实验设计与结果分析
3.1. 评价指标
回归算法的模型评价指标主要有均方误差(Mean Square Error, MSE)、平均绝对误差(Mean Absolute Arror, MAE)、均方根误差(RMS Error, RMSE)以及决定系数R2。
3.1.1. 决定系数
R2即决定系数,是衡量预测值对真实值拟合好坏的程度。R2的范围在(0~1)之间,越接近1,说明模型拟合的越好。
3.1.2. 均方误差
均方误差MSE是真实值与预测值的差值的平方然后求和平均,范围[0, +∞),当预测值与真实值完全相同时为0,误差越大,该值越大。如公式(1)所示:
(1)
3.1.3. 平均绝对误差
平均绝对误差MAE是预测值与真实值之差的绝对值的平均值。与MSE不同,MAE不受异常值的影响,更能反映模型的预测准确性。如公式(2)所示:
(2)
3.1.4. 均方根误差
均方根误差RMSE,实际上就是真实值与模型预测值之差的平方求均值后的算术平方根,其取值范围也是[0, +∞),RMSE值越小,说明模型的预测产品产率与催化裂化装置中真实产品产率越接近,具体计算公式(3)如下:
(3)
3.2. 数据集预处理
1) 产品产率定义
产品流量直接从催化裂化装置的实时数据库中获取,但最终需要的是产品收率。产品流量和产品产量之间的关系如公式(4)所示:
(4)
其中,表示第i个产品的产率,
表示第i个产品经过催化裂化反应转化后的物料量,F表示原始物料量。
的数值越大代表该产品的收益率越好。
2) 标准化处理
由于FCC系统结构复杂,在实际生产中所获得的有关数据往往维度不一。如果不对不同维度的特性进行转换,则会使大尺度特性在模型学习中占据主导地位,而对小尺度特性则有可能被忽视。所以,在数据预处理过程中,为了消除维数的影响,提高模型的性能,减小离群点对模型的影响,还必须对其进行归一化处理。数据可以在统一的尺度上变化,使得不同特征之间的比较更加合理和可靠,同时提高模型的鲁棒性和稳定性。本文选择了利用标准化来预处理数据,按照公式(5)对数据进行缩放:
(5)
其中,Xnorm表示为经过归一化后的数据,Xmin表示为特征的最小值,Xmax表示为特征的最大值,X表示为原始数据。
3.3. 实验设计
由于支持向量回归(SVR)、多层感知器(MLP)、决策树(DT)等是最先进的回归模型,而单层LSTM (SL-LSTM)、多层LSTM (ML-LSTM)和双向循环神经网络(BiLSTM)是常见的循环模型,因此选择它们与所提出的PMHA-CNN-BiLSTM-XGBoost进行产量预测的比较,并且通过对比自注意力机制、多头注意力机制等是常见的注意力机制验证PMHA-CNN结构提升预测模型性能的有效性。
本文的数据主要为某炼油厂的流体催化裂化装置反应再生系统共3681条数据。通过采样间隔为1分钟为了横向对比PMHA-CNN-BiLSTM-XGBoost在不同数据间的效果,均采用各指标前3500条数据作为训练集,最后181条数据作为测试数据集。本文在PMHA-CNN-BiLSTM-XGBoost网络中选择催化裂化装置温度、压力、原物料量为输入变量对相关产品产率数据进行分析。此外,在后续的实验中,进一步分析和研究了选择每个模块间对时间序列预测以及对模型整体预测性能的影响。PMHA-CNN-BiLSTM模型训练过程中,迭代次数为50次,均方差MSE作为损失函数,采用Adam作为优化算法,学习率为0.001,训练集中有3500个样本数据,以9:1的比例划分,其中使用Dropout层,通过在训练过程中随机丢弃一部分神经元的输出,降低模型对训练数据的过度依赖,减少过拟合的风险。其中XGBoost的主要参数,如表1所示。

Table 1. XGBoost main parameter settings
表1. XGBoost主要参数设置
3.4. 结果分析
经50次迭代训练后的PMHA-CNN-BiLSTM-XGBoost的对各产品产率的预测结果分别如下图所示。
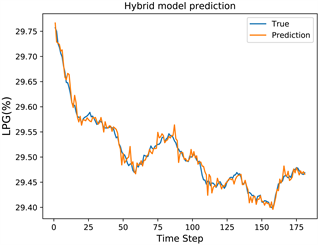
Figure 5. LPG product yield prediction
图5. LPG产品产率预测
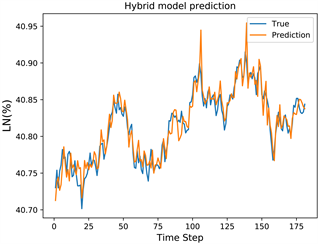
Figure 6. GSL product yield prediction
图6. GSL产品产率预测
从图5、图6、图7以及图8中,我们可以看到PMHA-CNN-BiLSTM-XGBoost的预测精度很高,大部分情况下,该模型都能对目标进行比较精确的预报,误差只有5%,也就是95%,与行业要求的精度基本一致。其中,PMHA-CNN-BiLSTM-XGBoost应用于GSL FCC柴油合成组分输入输出数据的预测精度明显低于其它数据,这主要是由于FCC反应类型复杂,单一的投入产出数据不能很好地刻画关联变量与目标变量间的联系,但95%的精度已经足够为我国FCC汽油产品的研发提供数据支持。通过试验,验证了PMHA- CNN-BiLSTM-XGBoost模型对FCC逆再系统产率进行预测的可行性与有效性。在此基础上,通过与其它回归分析的比较,验证了PMHA-CNN-BiLSTM-XGBoost模型在预测精度上的优越性。
根据表2所示,随机森林(RF)和基于PMHA-CNN-BiLSTM-XGBoost的模型在所有指标中表现最佳,具有较低的MSE、较低的RMSE、较低的MAE以及较高的决定系数(R2)值,显示出更高的预测准确性和解释能力。支持向量回归(Support Vector Regression, SVR)和多层感知器(Multi Layer Perceptron, MLP)模型的性能略逊于决策树(Decision Tree, DT)和AdaBoost模型,但仍然具有一定的预测能力,尤其是在较高的R2值方面表现较好。DT和AdaBoost模型相对于SVR和MLP模型具有更高的预测准确性和解释能力,但仍然不及随机森林和基于PMHA-CNN-BiLSTM-XGBoost的模型。基于PMHA-CNN-BiLSTM- XGBoost的模型在所有指标中表现最佳,具有最低的预测误差和最高的决定系数,显示出在不同回归模型中对催化裂化装置产率预测任务的出色适应性和优越性能。
根据表3所示,SL-LSTM模型的MSE为0.00089,相对较高,而其RMSE为0.02985,MAE为0.02319,决定系数R2为0.69979,表现相对较低。ML-LSTM (Multi Layer-LSTM)模型的性能略优于SL-LSTM (Single Layer-LSTM)模型,但仍然不够理想,其MSE为0.00075,RMSE为0.02740,MAE为0.02274,R2为0.75342。BiLSTM模型表现更好,其MSE为0.00062,RMSE为0.02486,MAE为0.01933,R2为0.80153,显示出更高的预测准确性和解释能力。进一步,采用注意力机制的SA-CNN-BiLSTM (Self-attention-CNN-BiLSTM)、MHA-CNN-BiLSTM (Multi-Head-Attention-CNN-BiLSTM)和PMHA-CNN- BiLSTM模型在各项指标中均有显著改进,分别达到了较低的MSE、RMSE和MAE,以及较高的R2值。特别是PMHA-CNN-BiLSTM模型,其MSE仅为0.00177,RMSE为0.04202,MAE为0.03467,R2为0.97645,表现最为优秀。最后,基于PMHA-CNN-BiLSTM-XGBoost的模型在所有指标中表现最佳,其MSE仅为0.00010,RMSE为0.01002,MAE为0.00728,R2为0.98009,表现出色,显示出对不同循环神经网络情况下催化裂化装置产率预测任务的出色适应性和优越性能。
Table 2. Comparison of prediction results of different recurrent neural network models
表2. 不同循环神经网络模型预测结果比较
Table 3. Comparison of prediction results of different regression models
表3. 不同回归模型预测结果比较
4. 结论
本文提出了一种对催化裂化装置有效处理时序数据中的空间和时间信息的预测模型PMHA-CNN- BiLSTM-XGBoost。PMHA-CNN-BiLSTM-XGBoost主要结构为PMHA-CNN模块和BiLSTM模块,PMHA-CNN模块负责在建模过程中提取序列数据的多尺度特征和增强局部感知野,BiLSTM模块负责捕捉序列数据中的时序依赖关系,并减轻梯度消失问题。通过并行加入原始数据的方式,提高了模型对于处理高维和非线性数据的能力。最终通过XGBoost对PMHA-CNN-BiLSTM模型的微调能够进一步优化模型的性能,提高预测的准确性。本文实验结果将为FCC生产工艺优化提供新的思路和方法,为FCC生产工艺优化提供理论依据,也为FCC产品收率的综合、立体的预测奠定基础。PMHA-CNN-BiLSTM- XGBoost与各种机器学习模型的比较试验结果表明,PMHA-CNN-BiLSTM-XGBoost方法用于FCC产品收率的预测具有较高的可靠性。未来将需要不断优化网络结构以及数据集的扩充来提升模型的预测准确率,继续探索更优的时序数据预测方式、神经网络等深度学习模型对FCC产品产率进行预测。