1. 引言
我国成为全球最大的机动车消费市场,并实施了2020年的车险综改,这促使车险市场潜力巨大,同时也增加了车险欺诈问题。据报道,我国车险欺诈占据了保险欺诈总案件的80%,每年约有200亿元的案件涉及金额。截至2022年第一季度,银保监会及其派出机构收到并转交了2.65万件涉及保险公司的投诉,其中机动车辆保险和普通人寿保险的投诉数量最多。车险欺诈不仅给保险公司带来了经营压力和损失,还违反了公平、诚信、正义的社会价值观念,损害了合法消费者的权益。因此,随着机器学习技术在保险领域的应用不断深入,它被认为是最有前景的欺诈识别工具之一 [1] [2] [3] [4] 。
自2000年以来,随着机器学习在各行各业的应用不断增加,它也开始在保险欺诈识别领域得到应用。Stijn Viaene等人(2002)使用了1993年的马萨诸塞州的人身伤害保护索赔数据集,评估了多种算法,包括Logistic回归、C4.5决策树、KNN等。结果显示C4.5决策树的效果较差 [5] 。Clifton Phua等人(2004)采用了反向传播(BP)、朴素贝叶斯(NB)和决策树模型进行预测,通过bagging技术将这些基础分类器组合,结果显示bagging后的模型略优于最佳分类器决策树模型 [6] 。Javier Muguerza等人(2005)分析了分类树在解决汽车保险公司欺诈检测问题时的表现,并比较了合并树和C4.5树,同时对误差进行了更广泛的分析 [7] 。搨思杰(2016)比较了AAAG模型、BP神经网络、EXPERT SYSTEM等多种欺诈识别模型的优缺点,并从保险公司理赔系统的13个指标中筛选出了8个与保单欺诈显著相关的变量 [8] 。李亚琪(2018)通过蜂群算法优化了极限学习机和随机森林模型,并在索赔数据上验证了这种优化对模型预测准确度的提升 [9] 。而杜小雨(2019)则使用了APriori和FP-growth算法进行了车险理赔样本的关联分析,证实了关联分析的有效性 [10] 。
本文分别构建随机森林、XGboost、LightGBM模型的保险欺诈识别模型,并分别进行调参以求获得更好性能。
2. 数据来源及预处理
2.1. 数据来源
本文使用了来自Kaggle数据平台的美国某保险公司的车险索赔数据集。由于国内保险公司用户信息不公开,因此选择了国外数据。该平台数据已经通过官方验证,数据可靠有保障。数据集包含不同区域的车险索赔信息,共有15,420条记录,32个特征,该数据主要描述了车辆保险用户的基本信息和事故相关情况。因变量为是否欺诈,取值为0或1。示例数据见表1,数据集变量特征见表2。

Table 2. Variable features of the dataset
表2. 数据集各变量特征
FraudFound_P为记录是否欺诈的标签,其余的32个特征本数据集将其分为五个方面进行描述,其中与人相关共9项变量,与车相关共5项变量,与时间相关7项变量,其他项2项变量,其中RepNumber代表处理保单人员的编号,为1~16间的重复数值,Policy Number为记录用户的标签。
2.2. 数据清洗
数据清洗是为了使数据适合分析和建模,包括去除重复数据、填补缺失值、处理异常值和转换数据格式等。在本文中,经检查发现数据集无缺失值。因此,首先对数据进行了纵向无效变量的剔除以减少冗余,然后横向分析了各变量的异常值并进行了处理。
首先,我们的研究目的是对该保单是否为诈骗进行判断,而诸如保单号码、事故发生的星期、月份等对保单起标记作用的变量对判断目标变量毫无作用,因此直接将其删除。其次,变量Policy Type取值为“Base Policy”与“Vehicle Category”两变量取值的组合,变量冗余,因此剔除Policy Type变量。另外,由于数据中包含两种关于年龄的变量:一种是离散型的,另一种是类别型的。为了简化模型并提高效率,我们决定移除离散型的年龄特征,仅保留类别型的年龄信息。最后汽车品牌“Make”这个变量虽对该模型有一定的影响,但因其取值过多(19个),且不便于对其进行具体的分组,故将此变量删除,也便于后续的模型构建,缩短数据运行的时间。因此,我们总结得出了21个对车险欺诈具有显著影响的特征。
在本数据集中,客户年龄的最小值是0,客户最大年龄达到86。年龄的箱线图如下图1所示。对于年龄最小最小值为0,毫无疑问是异常数据,考虑到查证的困难性,以及数据集1万多条记录的情况,本文将年龄为0的记录直接删除;对于年龄超过80岁的客户,经查证,在美国驾驶证不设年龄上限。如根据伊利诺伊州法律规定,75至80岁的老人每4年需要进行一次路考来延长驾照,而81至86岁的老人每两年需要路考一次,87岁以上的老人则每年需路考一次。因此,本文不对年龄上限进行调整。
2.3. 数据均衡化
在反欺诈问题中,由于欺诈案例较少,导致数据集不平衡。传统机器学习模型通常要求各类别样本数量均衡,因此需要不均衡样本进行处理。
该数据集包含15,420条索赔记录,其中94%为正常索赔,6%为欺诈索赔,呈现明显的不平衡情况。
机器学习常使用重采样技术来平衡样本,解决不平衡的二分类问题。重采样技术通过利用已有数据和技术手段,在不收集其他数据的情况下生成新的数据分布,以实现样本的均衡。SMOTE算法是改进的随机过采样算法,有效地解决了模型过拟合的问题。它的基本思想是对少数类样本进行分析,并根据这些样本生成新样本,从而使数据集更加均衡。因此,本文采用SMOTE过采样技术对数据集进行采样,以达到平衡数据集的目的,数据采样之后的训练集数据分布如表3所示。
Table 3. SMOTE oversampling algorithm.
表3. 数据SMOTE过采样后的训练数据分布
3. Stacking模型建立
Stacking是一种从模型本身出发的更为先进的模型融合方法,其核心思想是在第一层利用多个基学习器学习原始数据,然后将这几个基学习器的输出按照列的方式进行堆叠,构成新数据,再将新的样本交给第二层的模型进行拟合,从而得到最终预测结果。这个流程以一种有效的方式组合了多个算法,从而提高了模型的准确性和泛化能力。下图2为模型建立流程图:
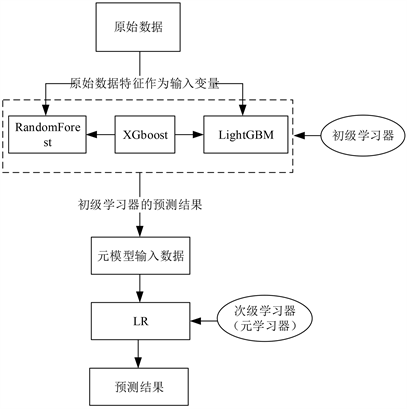
Figure 2. Diagram of model building process
图2. 模型建立的流程图
3.1. 随机森林模型
3.1.1. 随机森林算法
随机森林(RF)是Bagging的一种扩展,将决策树作为基学习器,并引入了随机属性选择。通过在全样本数据集中进行有放回抽样来训练多棵随机决策树,然后通过投票决定最终预测结果。本文选用了CART决策树算法,利用基尼指数来判断数据的纯度。RF在减少模型方差的同时提高了泛化能力,尤其适用于处理高维和大规模数据。
按A属性分裂的前后增益值,增益值最大作为特征选取原则。方法为
(1)
式中
。c表示不同类别,
表示类别i占整体的比例大小,即数据越混乱,相应Gini系数值越大。
为选取属性A,分裂后数据集D的系数值,计算公式为
(2)
3.1.2. 随机森林建模
本文采用Python3.7环境下的机器学习库sklearn中的ensemble模块来建立Random Forest模型,以下详细介绍模型建立的过程与超参数优化的结果。
本文实验调参过程中主要对如下表4中参数进行试验与调整,参数列表及取也见表4。
Table 4. Random forest network search parameter list
表4. 随机森林网络搜索参数列表
随机森林模型的混淆矩阵,如表5所示。
Table 5. Confusion matrix for random forest model
表5. 随机森林模型混淆矩阵
由混淆矩阵得出的其他指标如表6所示。
Table 6. Random forest model classification metrics
表6. 随机森林模型的分类指标
根据上述评估指标,我们发现模型对于非欺诈情况有更强的预测能力,Precision较高。Recall指标表明在欺诈样本中被正确识别的比例达到了0.91,而欺诈检测的核心是准确识别欺诈样本,因此该模型是可接受的。整体而言,该模型对数据集的预测准确率为0.82,预测能力一般。
3.2. XGBoost模型
3.2.1. XGBoost算法
XGBoost (Extreme Gradient Boosting)算法是梯度提升树(GBDT)的改进版本,通过在目标函数中引入叶子权重和L2正则化,有效降低模型复杂度,减少方差,从而优化模型性能。通过权衡预测误差和复杂度,XGBoost能够迭代构建多棵树,逐步提高预测能力,使其在各种预测建模任务中表现优异。
目标函数为
(3)
其中,结构风险项
又由两部分组成
(4)
其中T参数为第j棵树叶子节点的个数,
是叶子节点值的L2范数,
、
分别为惩罚系数、权重惩罚系数。
3.2.2. XGBoost建模
构建最优模型的通常方法是通过最小化训练数据的损失函数,而XGBoost采用了结构风险最小化的损失函数。这个损失函数包含两个主要部分:一是衡量预测值与真实值之间差距的部分,二是正则化项,用于控制模型的复杂度,其中包括叶子节点的数量和分数。在生成树时,XGBoost会考虑树的复杂度,从而提高模型的泛化能力。此外,XGBoost还利用多线程技术选择最佳切分点,以提高模型的训练速度。
本文实验调参过程中主要对如下表7中参数进行试验与调整,参数列表及取值也见表7。
Table 7. Random forest network search parameter list
表7. XGBoost网格搜索参数列表
XGBoost模型的混淆矩阵,如下表8所示。
Table 8. Confusion matrix for XGBoost model
表8. XGBoost模型混淆矩阵
由混淆矩阵得出的其他指标如表9所示。
Table 9. XGBoost model classification metrics
表9. XGboost模型的分类指标
根据上述评估指标,由Precision可看出我们发现模型对于欺诈情况的识别力稍逊于非欺诈。Recall指标表明在欺诈样本中被正确识别的比例达到了0.95。F1_score整体而言都比较高。该模型对数据集的预测准确率为0.9080。
3.3. LightGBM算法
3.3.1. LightGBM算法介绍
LightGBM算法使用了梯度提升树的单边采样技术(GOSS)和互斥特征捆绑技术(EFB)。GOSS根据样本梯度对样本进行采样,减少了计算所需的样本数,提高了训练速度和内存效率。而EFB将互斥的特征捆绑成一个单独的特征,降低了训练样本的特征数量,进一步提高了训练效率和精度,尤其适用于处理高维稀疏数据。这些创新技术使得LightGBM在大规模数据训练中表现出色,成为了许多实际应用场景中的首选算法。
3.3.2. LightGBM建模
下面应用LightGBM算法进行建模。本文采用Python3.7环境下的机器学习库sklearn中的en-semble模块来建立LightGBM模型,以下详细介绍模型建立的过程与超参数优化的结果。
本文实验调参过程中主要对如下表10中参数进行试验与调整。
Table 10. LightGBM search parameter list
表10. LightGBM网格搜索参数列表
LightGBM模型的混淆矩阵,如下表11所示。
Table 11. Confusion matrix for LightGBM model
表11. LightGBMt模型混淆矩阵
由混淆矩阵得出的其他指标如表12所示。
Table 12. LightGBM model classification metrics
表12. LightGBMt模型的分类指标
根据上述评估指标,由Precision可看出我们发现模型对于欺诈情况的识别力逊于非欺诈。Recall指标表明在欺诈样本中被正确识别的比例达到了0.96。F1_score整体而言都比较高。该模型对数据集的预测准确率为0.9149。
3.4. Stacking模型融合
Stacking模型建立过程首先将上述三种算法作为初级学习器,并引入Logistic Regression作为次级学习器,利用上述三种算法的输出作为其输入,最终,完成Stacking模型的构建。
下面是三个单一模型指标与Stacking融合模型指标的对比(表13)。
Table 13. Comparison of classification metrics for various models
表13. 各模型的分类指标对比
各单一模型及Stacking融合模型的ROC曲线如图3所示。
4. 结论
本文首先对保险欺诈识别的研究意义及研究现状进行了阐述;简要介绍了本文所用的三个模型的相关理论;将原始数据集经过数据清洗、SMOTE经过采样等数据预处理后作为车险欺诈识别模型的输入。通过实证分析分别构建了随机森林、XGBoost、LightGBM三种模型,并对它们的训练效果及拟合情况进行了对比分析;最后基于这三种模型利用Stacking法建立了融合模型,得到分类效果更好、更加稳定的模型。该融合模型对整体的预测能力比较好。