1. 引言
接收机工作特性(Receiver Operating Characteristic,简称ROC)分析起源于二战时期的雷达探测理论,最初主要用于评估雷达探测性能 [1] 。如今,这一工具已广泛应用于医学、心理学、生物信息学、信号处理以及机器学习等诸多科学与工程研究领域。上世纪90年代,学者们将ROC曲线引入至机器学习领域 [2] ,用以评判二类分类器的性能。自此以后,ROC曲线在机器学习、计算机视觉等领域的算法评估与优化工作中发挥了重要作用。
ROC分析是根据样本隶属类别的先验知识,可以根据不同的阈值设置绘制出假阳性率和真阳性率的二维曲线图,通过计算曲线下方的面积(AUC)来评价二元分类器的总体性能,首先它是非参数的,不需要预先知道样本的分布,同时具对数据中类别分布和误分类代价不敏感的优良特性,若正负分类比例发生变化,ROC曲线不受影响 [3] 。
原来的ROC分析框架只适用于两类的情况,随着人工智能等领域的迅猛发展,研究者们的关注点已不再局限于两类问题,而是逐渐转向解决三类甚至多分类问题。Alonz等人提出ROC曲面下体积VUS,将ROC分析拓展到三类背景下 [4] ,LIU等人提出了基于动态规划的VUS的快速算法 [5] [6] 。Nakas等人对多类问题进行了研究,并提出了多类ROC超曲面下面积VUHS的无偏估计量 [7] ,ZHU等人在这个基础上提出了连续样本下VUHS的快速算法 [8] 。尽管学者提出了VUHS概念以应对多类问题,并进行了一系列相关研究,但目前大部分研究主要集中在连续样本条件下对VUHS的估算上;相比之下,针对离散样本条件下VUHS的无偏估计研究则相对较少。同时现有对此类问题的算法存在计算复杂度高、偏差较大的问题。为此,本文提出了一种线性算法,用于对多个有序连续或离散测量的VUHS进行均值的无偏估计。
2. 利用动态规划计算VUHS的无偏估计量
2.1. VUHS的概率解释
令
是r类问题中的r个随机变量。假设
是分别取自累积分布函数为
的离散分布的独立同分布样本集。如Nakas等人 [7] 的论文中所示,以下概率的线性组合
(1)
可以解释为在单位r立方体内的r类ROC超曲面(VUHS)下的体积,当样本母体分布为连续时,式(1)自动退化成连续样本下的VHUS形式
。以三分类离散样本情况下为例,可获得以下概率公式:
(2)
从式(2)中不难发现,当
时,
,这说明统计模型采用了随机预测的策略,是一个随机选择分类器;而当
时,则意味着从左到右
是完全可分的。因此,可以从式(2)中得出,VUHS可以表征多类样本的分离程度。
2.2. VUHS的无偏估计量
为了方便起见,首先引入一些符号。设
为
的下标序列,
为序列R的递增子序列的集合,其元素个数为
,
表示
中的第j个元素,使用
标记有序序列
内等号开始的下标位置,设
序列共有k个连续子序列,每个子序列的长度分别为
(3)
其中
,
,
。由式(1)可以构造出VUHS的非参数估计量,即:
(4)
其中,
表示
对应的事件的权重,根据
序列内连续子序列区块的长度求得:
(5)
对于式(3)定义的标记序列,若满足
则
的值等于1,否则为0,例如,当
时,
,对应的权重
依次为1,1/2,1/2,1/6。当满足
时,
等于1,否则为0;当满足
时,
等于1,否则为0;当符合
时,
,为1,否则为0。当符合
时,
等于1,否则为0。
2.3. VUHS估计量的快速算法
直接基于式(4)计算
十分低效,例如,当所有的样本量相等时,即
,则时间复杂度为
,然而我们可以采用动态规划的方法进行快速实现。首先需要对
括号内的事件进行分类,每个标记序列
对应一个事件,符合事件条件的事件数量为:
(6)
例如,当
时,其全部事件如下表所示,结合式(4)和式(6)便可以计算出4类的VUHS的估计量
:(表1)
(7)

Table 1. The quantities required fbr quickly estimating the Variance of the estimator of VUHS
表1. 四类样本情况下计算VUHS估计值所需事件及对应参数
接下来将介绍如何通过动态规划获得所需要的基础事件的实际数量。
2.3.1. DP计算矩阵
令
是由集合
合并组成的联合序列。对这个序列进行升序排列,得到该序列的统计量:
(8)
假设区块
中的所有元素的值都等于
。令
为当
时,样本集
中分别等于
的元素的数量。那么对于r类向量集可得到r个计数向量,分别表示为
,向量长度均为K。将这些向量按序号自上而下堆叠,便得到了用于动态规划的计算矩阵。
2.3.2. 4类问题
下面首先探讨当
情况下,标记序列
时,
的计算过程,进一步解释动态规划的计算结构。由上表可得:
(9)
式(9)可以通过动态规划计算结构实现,首先将之前介绍的计数向量
自下而上进行堆叠,构成计数矩阵
,然后进一步把
初始化为0,如图1所示:

Figure 1. Diagram for computing
defined in (9), where
in order to facilitate visualization
图1. 计算式(9)中定义的
流程图,其中
为了方便可视化
规划路径在线性时间(
)内就可以从计数矩阵的左下角更新到右上角,其中的更新规则为:
(10)
最后当路径移动到右上角后,我们想要得到的
的值将会存储在矩阵元素
中。其他的事件均可以由该DP计算矩阵获得,进而由式(7)得到
的值。
2.3.3. r类问题
为了将动态规划方法推广到类问题,需要把以上算法的更新规则进行进一步的处理,首先将更新规则,分为累乘计算与累加计算,再根据标记序列与索引关系选择不同的更新规则,具体算法的伪代码如下:
Algorithm 1. Calculating the number of events S
算法1. 计算各事件的个数S

3. 实验及分析
为了验证本文所介绍方法的无偏性和快速性,首先将基于动态规划的VUHS算法(用
表示)与基于式(4)的估计算法(用
表示)以及基于图论(用
表示)的方法进行比较。我们生成了基于泊松分布的r个独立同分布连续样本集,
,在进行无偏性实验时,利用均值相对误差(REM)作为指标来评估算法的无偏性:
(11)
其中,
,实验设置了
两组样本进行比较,为了使得到的结果更加稳定,实验中每个算法运行1000次再取其平均值。我们实验结果如下图所示。
从图2中我们可以看到,由于
算法中需要对数据进行预处理,
的运算时间要略慢于同样是线性对数量级的
,但由于差别实在太小,可以认为这两个算法在计算效率上是一致的。反观
在样本类别及样本量增加时,其运算时间均会出现飞速的增长,因为它的算法时间复杂度是
。
如图3所示,在无偏性上显然
的表现优于
,
的均值相对误差完全拟合
的直线,而
是VUHS的无偏估计,因此证明了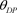 算法的无偏性。另一方面,
的均值相对误差,随着样本数量的增加,在某个固定值附近波动,当样本类别增加时,误差会进一步增大,说明了
在处理离散样本时是有偏的。
算法的无偏性。另一方面,
的均值相对误差,随着样本数量的增加,在某个固定值附近波动,当样本类别增加时,误差会进一步增大,说明了
在处理离散样本时是有偏的。
Figure 2. Comparison of CPU running time when calculating VUHS point estimation by three algorithms
图2. 三种算法计算VUHS点估计时CPU运行时间对比结果

Figure 3. The unbiased comparison between the algorithm based on DP and the method based on GRA
图3. 基于动态规划的估计算法与基于图论的方法的无偏性比较结果
4. 结论
本文基于动态规划提出了一种VUHS的快速无偏估计算法,首先对VUHS的估计值表示方法进行优化,并通过建立动态计算矩阵,将算法时间复杂度降低至线性对数级,其次将VUHS点估计快速算法拓展到连续及离散样本下,并设计了蒙特卡洛实验进行了检验。实验结果表明,本文设计的DP算法矩阵可以有效的提升VUHS的计算效率,该算法相较于基于图论的方法有更好的无偏性,相较于SOLW算法有更好的快速性,特别是在应对类别多和样本量大的机器学习模型的应用背景下。因此,本文的方法在VUHS的研究上有一定的理论意义及技术价值。
基金项目
本文研究工作由国家自然科学基金项目(62171141, 61771148)资助。
NOTES
*通讯作者。