1. 引言
从多视角图像中重建三维物体是计算机视觉的一个重要研究热点。传统的运动恢复结构或多视角立体匹配方法做三维重建,需要从多视角图像中恢复出稀疏点云,再到点云配准,恢复稠密点云,异常点处理,点云重建等一系列步骤。整体的流程非常长,每一步都会受到误差的影响。近年来,随着神经辐射场(NeuralRadiance Field, NeRF) [1] 一系列工作的扩展,许多方法通过建立神经隐式表面与神经辐射场中的概率密度函数或累积密度函数的联系,利用体渲染管线和反向传播完成了神经隐式表面的拟合。
NeuS [2] 通过建立符号距离场(Signed Distance Fields)与神经辐射场(NeRF)中权重函数的关系,实现了不同于传统方法管线的多视角表面重建,同期工作还有volSDF [3] ,UniSurf [4] 等。NeuS的采样策略与神经辐射场的策略类似,都是分层采样策略。当进行光线步进时,先在光线上进行均匀采样,再根据计算得到的概率分布函数进行重要性采样。然而,由于NeuS使用了8层的多层感知机(Multi-Layer Perception, MLP),单个采样点的符号距离查询计算消耗较大,所以难以进行非常多的采样。Instant-NGP [5] 利用了占据栅格(Occupancy Grid),通过在每个格子中计算占据概率,以二值化数组表示空间是否有物体表面占据,使得在光线步进时可以跳过空白区域,让采样更集中在有效占据的格子中。虽然,Instant-NGP采用参数化数据结构结合单层MLP的方案使得采样点的符号距离查询计算消耗较小,并且占据网格可以辅助采样使得采样点更有效落在有占据的格子中,但占据的格子中采样策略为均匀采样,分辨率较小,采样数量也少时,会导致整体的拟合质量下降。针对上述问题,本文提出了一种新的混合采样策略。通过结合占据网格让采样更好地在有表面占据的区域进行采样,并采用一种分段指数函数来指导采样点在有效区域更好的靠近表面,使得整体的采样更加有效。
2. 相关工作
2.1. 神经隐式表面
隐式表面(Implicit Surface)是一种传统的三维表示方法。随着深度学习的发展,DeepSDF [6] 、Occupancy Network [7] 等利用神经网络来表达隐式表面的工作开始出现,但多数工作都需要三维监督,通过不同的方式将点云的三维坐标映射到重建的标量场,而本文的工作主要以多视角图像为输入并作为监督信息。DVR [8] 、IDR [9] 使用基于表面的渲染方法(Surface-based Rendering Method),通过多视角图像作为输入,输出高质量的几何与外观。受到神经辐射场(NeRF)的启发,NeuS [2] 、volSDF [3] 等工作,通过建立符号距离场(SDF)与体渲染公式中的概率密度函数或累积密度函数的关系,成功使用基于体渲染的方法进行了隐式表面的估计。为了进一步提高几何估计的质量,PET-NeuS [10] 、HF-NeuS [11] 等工作相继提出,提高了几何质量的同时也增加了训练的所需时长,一般需要将近一到两天的时间。对于训练效率的考虑,NeuS2 [12] 从Instant-NGP [5] 中得到了启发,通过结合多分辨率哈希编码到NeuS中,利用轻量的二阶计算使得输出的几何更加平滑,并且训练速度非常快,仅为分钟级。Voxurf [13] 的训练同样高效,通过扩展基于栅格的三维表达,并引入了多层级的几何特征加强了几何细节的表达。但这些工作的高效都是源于参数化的离散数据结构与少层数的多层感知机混合的思想,单个样本基于栅格、基于哈希等结构的查询复杂度仅为O (1),配合单层的感知机网络,其大大降低了对每个样本计算符号距离值的消耗。本文通过探讨采样策略与离散数据结构的配合,既减小单个样本的计算开销,又减少不必要采样的计算浪费。
2.2.高效采样的神经辐射场
由于神经辐射场(NeRF)的训练输入需要从光线步进中进行采样,而采样的数量和质量一定程度上影响模型训练和推理的速度和质量。所以,高效的采样策略是非常重要。NeRF [1] 和NeuS [2] 采用了从粗到细的分层采样策略,先对每条光线进行均匀采样,并计算出累积密度函数,然后在精细阶段采用逆变换采样方法(Inverse Transform Sampling)来进行重要性采样。但这种采样策略会引入很多无用的采样,导致计算的浪费。Instant-NGP [5] 受到了空间划分的启发,通过引入占据栅格来划分空间,以一个二值化数组来标记每个空间是否与物体表面相交,使得在光线步进的过程中,可以跳过一些无物体区域,减少了采样的浪费。NeuS2 [12] 、Neuralangelo [14] 沿用了这种方法,使得整体的采样更加有效。但这些工作在占据格子中的采样方法依然为均匀采样,当使用的占据栅格分辨率较低时,依然会引入非常多无用样本导致计算的浪费。DoNeRF [15] 等方法分析了多种采样策略,如均匀采样、非线性采样、NDC空间采样等的有效性,并引入了一种深度遮挡预测网络来指引采样位置的选择,从而减少无效采样的计算浪费。但其输入需要RGBD图像,本文工作仅需要RGB图像。还有很多工作 [16] [17] 通过单目深度估计网络来指引采样,但这既增加了整体模型的参数量,又受限于深度估计骨架网络的性能。本文工作,通过利用占据栅格配合一种分段指数函数来指引采样,在较低的计算开销下使得整体的采样效率增加,既避免了在无效区域的采样,又引导了有效区域采样点更加靠近物体表面。
3. 方法
本文工作建立在神经辐射场(NeRF) [1] 和NeuS [2] 之上。首先,本章会先回顾NeRF和NeuS两个工作。然后,我们会介绍本工作的整体网络架构,包括几何网络、外观网络、法向量的计算等。其次,对于光线上的采样,我们会分析NeuS的分层采样和占据栅格采样,并提出二阶段采样的方法。最后,我们会介绍训练过程的正则化项。
3.1. 预备知识
神经辐射场(NeRF)将三维场景表示为一种连续函数,其利用体渲染可以从任何相机位置渲染出对应视角的图像。给定N张不同角度拍摄的图像
,并给定相机的内外参数
,从不同视角图像的像素上投射光线,然后在光线上进行采样。对于第i个采样点
,NeRF使用神经网络估计出该点的体积密度
和采样点颜色
,即
,这里的d为光线的方向,使用相机内外参数计算得到。然后,通过经典的体渲染(Volume Rendering) [1] 方案对整条光线所有采样点估计的颜色进行积分得到该视角图像的像素颜色
,其数值积分的近似表达为:
(1)
这里的
为累积透射率,
为第i段间距的不透明度(Opacity),
为相邻采样点的间距,
为从相机原点o出发到
的相对深度值。对于整个工作的优化,损失函数定义为渲染图像与给定视角图像的颜色损失,定义为:
(2)
NeuS [2] 通过建立符号距离场(SDF)与不透明度
的联系,使得其可以通过NeRF的体渲染管线来优化SDF,从而实现多视角图像重建隐式表面的任务。SDF为一种较为常用的隐式表面,其通过零水平集来表示物体表面S,即
,这里的
为预测的符号距离值,使用神经网络来表示。给定采样点
和符号距离值
,其与不透明度
建立的表示为:
(3)
这里的
为Sigmoid函数。由于NeRF和NeuS都采用了较深的多层感知机(MLP)对每一个采样点进行估计,其计算消耗非常大,训练速度较慢。Instant-NGP引入了一种占据栅格(Occupancy Grid)来对空间进行划分,采用二值化数组来标记每个格子是否与物体表面相交,从而使得整个过程不需要再无效区域采样,减少了采样数。同时,其引入了多分辨率的哈希编码器,使得对每个采样点的计算消耗大大降低。虽然,Instant-NGP在新视角合成取得了较好的效果,但由于其直接对体积密度进行Marching Cube [18] 而得到三角网格,使得恢复的几何表面存在很多噪声。

Figure 1. Diagram of the network architecture
图1. 网络架构图
3.2. 网络结构
我们提出一种结合NeuS [2] 和Instant-NGP [5] 的神经隐式表面重建算法,通过给定一组环绕物体拍摄的图像和相机的内外参数,可以高效地重建出静态三维物体表面。整体的方法架构如图1,通过从给定视角的图像像素进行光线投射,然后从光线中进行采样。与NeRF [1] 、NeuS和Instant-NGP不同,我们通过结合占据栅格(Occupancy Grid)和一种分段指数函数来指导采样,具体细节在章节3.3。对于每一个采样点,会先通过多分辨率哈希编码
对采样点进行插值,并对不同尺度插值好的特征进行整合操作,然后直接送到单层MLP中进行符号距离的预测。这里隐式表面的表示为符号距离场(SDF),表示为:
(4)
为层数为1的MLP。除了输出符号距离值外,还会输出几何特征,这里记为enc。对于每个采样点颜色的估计,具体表示如下:
(5)
这里的d为使用球面谐波(Spherical Harmonics, SH)对视角方向向量d编码后的特征,与Instant-NGP的做法一致,目的是为了使采样点的颜色是视角相关的,即同一个点,在不同视角方向上的颜色值不同。n为采样点的法向量,与NeuS [2] 的法向量求解形式不同,NeuS对采样点的法向量是使用SDF的解析梯度(Analytic Gradient),而本工作使用一种数值方法,为基于有限差分的SDF近似梯度,主要目的是提供一种更为平滑的法向量。
(6)
这里
,
为哈希网格的大小。引入n作为估计采样点颜色的输入还有一个好处,就是提供一种几何和外观的解耦 [9] 。实际上,NeuS2 [12] 和Neuralangelo [14] 也是类似的做法,利用Instant-NGP中的多分辨率哈希编码和较少层数的MLP对SDF进行估计,由于哈希编码的查询速度快,加上MLP层数较少(1层),相对与NeuS 8层MLP的计算消耗,NeuS2和Neuralangelo的SDF计算快了几个量级。然而,NeuS2和Neuralangelo的采样策略与Instant-NGP一致,都为一阶段占据栅格(Occupancy Grid)引导的采样方式,其在每个占据的格子中依然为均匀采样,当占据栅格的分辨率较低时,实际上依然会引入很多无效采样。
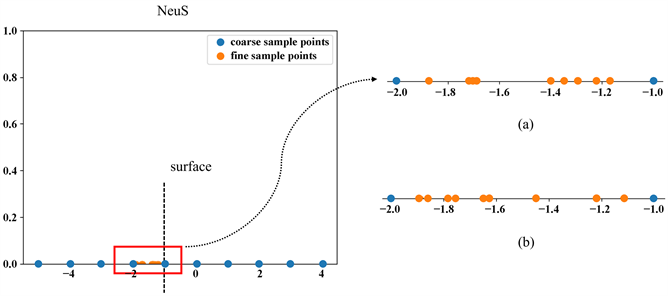
Figure 2. Diagram of the hierarchical sampling strategy of NeuS
图2. NeuS分层采样策略图
3.3. 两阶段采样
在公式(1)中,
可以看作整个求和公式中对于采样点颜色
的权重,用于衡量光线上每个采样点的贡献程度,记
。对于一个不透明物体,实际上只有靠近物体表面的采样点才有贡献,即当采样点靠近物体表面时,权重w的值会趋向于无穷大,远离物体表面时,权重w的值为0。
由图2所示,假设对一个单位球(Unit Sphere)进行光线步进,图的横轴为一维的坐标值,值为−1和值为1是单位球的表面边界。以NeuS的采样策略,先对整个空间进行均匀采样,如蓝色点。然后,对所有均匀采样点计算w,并通过累积权重w得到累积密度函数。通过逆向变换采样,NeuS会做符合w分布的随机采样,具体如图2(a)。可以看到,NeuS在精细采样阶段的采样点会随机散落在w峰值所在的区间
,但并没有对物体表面的偏向性,即采样点没有偏向于−1的位置。并且,由于随机采样的特性,每次做逆向变换采样,精细采样的采样点落实的位置都比较随机,如图2(b)。对于Instant-NGP的采样策略,其通过占据栅格(Occupancy Grid)的二值化数组辨别出哪些区域需要跳过,从而减少像NeuS粗阶段均匀采样的计算浪费。但对于一个有占据区域,依然是均匀采样策略,无法很好指导采样做得更高效,如图3(b-2)。
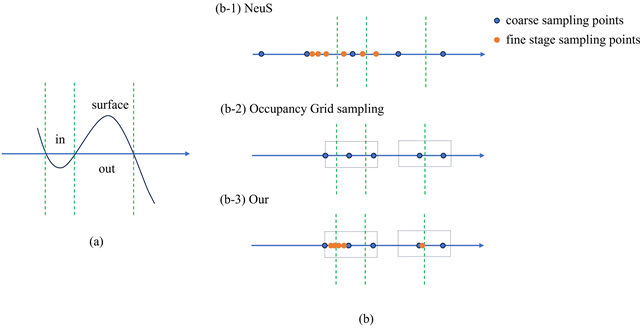
Figure 3. Diagram of the hierarchical sampling strategy comparison
图3. 采样策略对比图
本文工作采用一种两阶段的采样策略,如图3(b-3)。整体步骤为:1)粗阶段使用基于占据栅格的方式,使得可以跳过空区域进行采样,避免采样的无效;2)精细阶段使用一种非线性函数指引采样的策略,使得在占据区域的采样点可以更加靠近物体表面。对于精细阶段的非线性函数,受 [19] 的启发,引入一种变换权重函数
,公式如下:
(7)
(8)
公式(7)中,
且
,
且
。这里的w为粗阶段对采样点计算的权重,与NeuS一致,即
,a和b为采样间隔端点的权重值。
但与NeuS不同的是,通过引入
,可以对采样区间进行插值处理,而不是分段常数。换而言之,对于一个采样间隔
,NeuS在间隔内的点的权重均为固定值,而我们引入的
可以实现在间隔内插值。对于离散形式的体渲染,进一步细化整体的概率分布。同时,公式(7)可以看作通过a和b的比值自适应地控制区间内点的权重,当a的值远小于b值,
随着采样深度s的增大,整体的增大趋势会越来越剧烈,即越靠近b权重值端点的采样点,其权重越大。当a值远大于b时,
整体的趋势会往b值的端点迅速递减。从而使得,越靠近大权重值的采样点,其权重值也相对较大,越远离越小。进而使得在逆向变换采样的过程中,可以使精细采样点更靠近表面。
3.4. 正则化
如图1,本工作通过从提出的两阶段采样策略从光线上进行采样。每一个采样点输入到网络中预测出符号距离场(SDF)和采样点颜色,通过损失函数来最小化。总的损失函数
如下:
(9)
这里的
为渲染损失(Rendering Loss),为采样点渲染颜色
与真实颜色
的L2损失,并对光线上全部采样点的L2损失进行求和 [2] 。
(10)
为Eikonal正则化项,用于保证
的演化符合符号距离场(SDF)的性质 [2] 。
为SDF的梯度,使用公式(6)近似求得,并非使用自动微分求解。
(11)
除此之外,我们还使用了NeuS [2] 提供的掩膜损失(Mask Loss),其定义为每条光线的采样点权重和与数据集提供的掩膜图像的二值交叉熵(Binary Cross-Entropy, BCE),如公式(12)。
(12)
(13)
公式(12)中的
为0或1值的掩膜,
为光线采样点权重和,k表示第k个像素,i表示第i个采样点。最后,损失函数公式(9)的超参数
和
在实验中均设置为0.1。
4. 实验
4.1. 实验设置
4.1.1. 数据集
为了评估本文方法的有效性,我们采用了两种不同类型的数据集,分别为合成数据集和真实拍摄的数据集。对于合成数据集,我们使用NeRF [1] 提供了合成数据集,其包含6个不同的物体,每个物体里包含不同视角的图像和对应视角的相机参数,图像分辨率为800 × 800。对于真实数据集,我们选择了DTU数据集。DTU中包含15个场景,每个场景中有不同视角拍摄的RGB图像、对应的物体掩膜(Object Mask)和相机参数,涵盖了各种不同的材质,不同拓扑结构的物体。
4.1.2. 基准模型
本文工作选择了三个基准模型进行对比,分别为NeuS、Neus-acc和Neus-facto。Neus-acc主要了为体现占据栅格(Occupancy Grid)在表面重建任务中引导采样的作用,即NeuS与Instant-NGP的结合。其实现与NeuS2 [12] 类似,使用多分辨率哈希编码和1层MLP来估计SDF。在光线步进时,会使用占据栅格的二值化数组对无物体相交区域进行跳跃,从而达到减少无效采样的目的。不使用NeuS2的原因是为了排除过多GPU优化技巧的影响,更专注在比较采样手段上。Neus-facto [20] 使用了Mip-NeRF360 [21] 提出了Proposal Network来学习采样分布,其是一种高效的采样手段。
4.1.3.实现细节
我们使用的多分辨率哈希编码的分辨率一共分16级,从25到216,每个级别的哈希特征大小设置为2。几何部分的MLP层数为1层,隐含层(Hidden Layer)大小为64。外观部分的网络MLP层数为2层,隐含层大小为64。我们使用一种混合优化的方法来进行训练,前5000次迭代采用常数因子的学习率衰减,之后采用指数衰减的方式。优化器使用AdamW,对于几何网络(Geometry Network)
的学习率为0.001,外观网络(Appearance Network)
的学习率为0.001,betas参数为0.9和0.99。实验所用的GPU为单张V100 32G。
我们采用了一种渐进式的训练方式,使得模型可以在学习到高频信息的同时,又减少噪声的产生。通过设定一个更新步数,这里设定为1000,每迭代1000次时,多分辨率哈希编码
的层级会更新,并激活对应的层级哈希特征,使得整体的学习为从粗到细的优化,从而更好地重建出几何表面。
4.2. 实验结果
本文主要在真实数据集(DTU)和合成数据集(NeRF Synthetic)上的检验表面重建的质量和新视角合成的质量。主要的定量评价标准为倒角距离(Chamfer Distance, CD)和峰值信噪比(Peak Singal-to-Noise Ratio, PSNR)。CD用于评价模型重建的几何质量,PSNR用于评价模型多视角合成的图像质量。CD越低,重建的几何越好。PSNR越高,合成的视角质量越好。与先前工作一致 [2] ,网络估计出的SDF会使用Marching Cube算法 [19] 在1024 × 1024 × 1024分辨率下提取出三角网格进行CD的评估。
4.2.1. 真实数据集
对于DTU数据集,倒角距离(CD)的定量评估如表1,我们选取了DTU数据集中的14个场景进行CD的评价,通过控制模型(Neus-acc, Neus-facto, Our)迭代次数为20,000次,可以看出,我们的方法在大部分物体上取得了较好的结果。从图4可以看出,我们的方法在几何细节上的重建有更好的效果,这得益于渐进式的训练和两阶段的采样策略。

Table 1. Chamfer Distance experiment results of DTU dataset
表1. DTU数据集倒角距离(Chamfer Distance, CD)实验结果
对于新视角合成(Novel View Synthesis)任务,从表2可以看出,我们的方法比NeuS、volSDF、Neus-acc有显著的提升,并在大部分场景中比Neus-facto的结果好,表中最好的结果使用下划线标记。总的来说,我们的方法对于几何细节的恢复和新视角合成都有一定程度的提高。

Figure 4. Diagram of the mesh quality comparison on DTU datasets
图4. DTU数据集几何质量对比图
Table 2. PSNR experiment results of DTU dataset
表2. DTU数据集峰值信噪比(PSNR)实验结果
4.2.2. 合成数据集
对于合成数据集(NeRF Synthetic),我们选取了6个场景进行几何重建和新视角合成任务的质量评估。从图5可以看出,通过控制迭代次数为30,000次,我们的方法与Neus-facto的基于Proposal Network采样的方法相比,无论是生成的三角网格还是新视角合成的质量,我们的方法都明显优于Neus-facto。增加迭代次数,Neus-facto和我们的方法均能在两个任务上得到提升,但本实验主要为了验证采样策略的有效性,我们选择了控制在30,000次迭代,训练时长都在2小时内。
实际上,虽然NeuS在几何重建任务上取得了一定的效果,同时也牺牲了其新视角合成任务的性能。如表3,NeuS在合成数据集NeRF Synthetic上,新视角合成任务的峰值信噪比(PSNR)明显低于NeRF。但是,我们的方法不仅在几何质量方面得到了一定的提升,同时在新视角合成任务中也有很好的效果,在大部分场景中,我们的方法都超过了NeRF。

Figure 5. Diagram of the mesh quality comparison on NeRF Synthetic dataset
图5. NeRF Synthetic数据集几何质量对比图
Table 3. PSNR experiment results of NeRF Synthetic dataset
表3. NeRF Synthetic数据集峰值信噪比(PSNR)实验结果
Table 4. PSNR experiment sampling strategy ablation results of DTU dataset
表4. DTU数据集采样策略消融实验的峰值信噪比(PSNR)实验结果
4.2.3. 消融实验
为了更好地评估我们的方法,这里对提出的两阶段采样策略和渐进式训练进行消融实验。本次消融实验分别对两种采样数进行实验,分别为128个采样点和1024个采样点。
针对DTU数据集中选取的10个场景,表4为每条光线128个采样点进行对比的PSNR结果。我们把去掉渐进式训练(Progressive Training, PT)和提出的采样策略标记为Model。Model的采样策略为基于占据栅格(Occupancy Grid)的采样。表中的(+PT)表示为Model添加了渐进式训练。(+PTS)表示Model添加渐进式训练和提出的采样策略,即本文提出的方法。表中每个方法的训练迭代次数为30,000次,最好的结果均用下划线标记,可以看出,当每条光线采样的点数为128时,渐进式的训练方式结合本文提出的两阶段采样策略对于新视角合成任务有显著的提升。从图7可以看到,对于128次采样,结合渐进式训练和我们的采样策略(Model + PTS)对于纹理细节、高光反射等恢复有更好的效果。
如图6所示,当对每条光线进行1024次采样,使用两阶段采样策略的标记为(w our sampling),仅采用占据栅格的采样标记为(w/o our sampling)。可以看出,当对光线采样点足够多时,我们的方法对于几何重建依然有一定程度的提升。

Figure 6. Diagram of the 1024 sampledpoints strategy ablation comparison
图6. 1024采样点消融实验对比图

Figure 7. Diagram of the 128 sampledpoints ablation comparison
图7. 128采样点消融实验对比图
综合上述,我们通过两种采样数的消融实验表明,当对光线进行较少的采样,我们的二阶段采样策略可以很好地指引采样,在几何表面重建和新视角合成任务上均取得很好的提升。当对光线进行较多数量的采样,我们的策略相比与纯占据栅格指引的采样,在几何表面重建任务上仍有微小的提升。
5. 结论
本次工作,我们引入了一种两阶段的采样策略,并结合渐进式训练的方式,使得可以从多视角图像中重建出高质量的物体表面,同时保持新视角合成任务的出色性能。我们的方案扩展了NeuS分层采样和基于占据栅格的采样策略,通过引入一种非线性函数指引采样,使得采样点更好地落在靠近物体表面的位置,从而能更好地建模光线上的概率分布。这种结合既减少了在空白区域采样的浪费,又在占据的栅格中指引了采样,是一种更细粒度的采样方式。渐进式的训练可以使得模型在训练初期不过多关注物体的高频细节从而引入噪声,通过渐进式激活哈希特征的方式使得符号距离场的拟合更加鲁棒,并且很好地恢复出几何细节。但是,本文的方法仍然存在不足,如针对高光表面拟合不稳定、受Nyquist采样定理的限制等,我们将其作为未来工作的探索。