1. 引言
时间序列预测是基于过去时间序列值对数据集进行建模,这些数据集用于预测未来值。时间序列预测方法在商业、金融、计算机科学、工程、医学、物理、化学等许多跨学科领域都有广泛的应用。经典的时间序列分析评估在很大程度上是基于精确的信息。然而,在现实世界中,关于底层系统的一些信息可能是不精确的,并且以模糊量的形式表示。因此,有必要将经典方法推广到模糊环境中来研究和分析利益系统。对于这种情况,模糊时间序列模型在过去几十年中由于其在统计学和工程学中的广泛应用而获得了相当大的关注,例如招生 [1] ,股票指数价格 [2] ,温度 [3] ,财务预测 [4] 和农产品 [5] 等。
Song and Chissom [6] 最早提出了模糊时间序列的概念,并针对精确数据给出了模糊时间序列模型求解方法。模糊时间序列模型的求解主要由模糊化、模糊关系的建立和去模糊化等步骤组成。模糊逻辑关系的识别技术是求解模糊时间序列模型的重要一环,引起了许多研究者的兴趣,并得到了广泛的研究。模糊逻辑关系识别技术主要包括模糊逻辑关系群和模糊逻辑关系矩阵 [7] 、软计算技术 [8] 以及采用模糊逻辑的统计技术等 [9] 。
在许多实际问题中,模糊时间序列数据之间除了具有线性关系,一般还具有非线性关系。神经网络作为非线性映射的逼近器具有很高的能力 [10] 。因此,许多研究人员将神经网络与模糊时间序列结合起来,以达到更好的预测效果。Huarng和Yu [8] 提出了一种混合模型,结合反向传播神经网络与简单方法,实现了已知模式与未知模式分开预测,提高了预测精度。Khashei et al. [11] 将人工神经网络和模糊回归模型结合,提出了一种新的混合模型用于不完全数据条件下的时间序列预测。Egrioglu et al. [12] 提出了一种新的混合模糊时间序列方法,利用模糊c均值(FCM)方法和人工神经网络分别进行模糊化和去模糊化。Gu et al. [13] 提出了一种将信息颗粒划分方法与反向传播神经网络(BPNN)相结合的时间序列预测模型。
非参数技术在模糊时间序列预测中也被广泛应用。Hesamian和Akbari [14] 提出并讨论了一种基于非参数核的统计方法,对LR-型模糊时间序列数据进行了预测。然而,作为一种完全非参数的方法,它通常会导致一些缺点,如维数诅咒、解释困难和缺乏外推能力。模糊半参数回归模型通常比相应的模糊非参数回归模型更具优势和灵活性。Hesamian和Akbari [15] 提出了一个具有模糊数据、非模糊系数和模糊平滑函数的半参数时间序列模型。Zarei et al. [16] 对Hesamian和Akbari [15] 模型进行了拓展,对模糊数据采用了不同的距离度量。
本文结合非参数核方法、加权最小二乘法和BP神经网络,引入了基于BP神经网络的自适应模糊半参数时间序列模型。本文使用了半参数统计推断和加权最小二乘法,与使用最小二乘法的参数和非参数方法相比,通常会产生稳健性和灵活性的结果。此外,在不确定条件下,BP神经网络可以获得更丰富的信息和更高的预测精度。然后通过比较一些常见的拟合优度标准的结果来检验所提出方法的有效性和优点。为了进行比较研究,将所提出的模型与现有的一些模糊时间序列模型进行了仿真例子的比较。数值和比较结果表明,所提出的模型可以在模糊时间序列分析中提供足够准确的结果,并且可以抵消估计过程中可能出现的模糊异常值的破坏性影响。
本文的其余部分组织如下:第2节回顾了模糊数和模糊时间序列、模糊自回归分布滞后模型和模糊半参数时间序列模型的基本概念,这些概念对本文提出的方法至关重要。在第3节中,提出了一种基于BP神经网络的自适应模糊半参数时间序列模型。然后,给出了本文提出的迭代算法步骤,同时介绍了一些常见的拟合指标,来评估所提出模型的拟合效果。第4节利用模拟仿真的例子进行了一些比较研究,以验证所提出模型的可行性和有效性,并在最后一节给出了一些结论。
2. 预备知识
在本节中,我们将介绍模糊数和模糊时间序列、模糊自回归分布滞后模型、模糊半参数时间序列模型的基本概念。
2.1. 模糊数和模糊时间序列
给定论域
,模糊集
由其隶属函数
定义,对于
,
称为模糊集
的
-水平集,并记作
,区间表示为
,其中,
,
。如果对于
,
是有限闭区间,则实数域
上的模糊集
称为
上的一个模糊数 [17] 。
定义1 [17] LR-型模糊数
由其隶属函数定义,通常表示为
:
(1)
由上式可知,LR-型模糊数由中心值
,左展形和右展形
,严格递减的形状函数
,且
组成。当
时,LR型模糊数退化为清晰值
。
当
且
时,LR-型模糊数为对称模糊数,记为
。当形状函数
时,LR-型模糊数为三角模糊数,记作
,若
,LR-型模糊数为对称三角模糊数,记作
。
定义2 [1] 设
的子集
是定义在模糊集
的论域,
是
的集合,则
称为
上的模糊时间序列。
定义3 [18] 假设
和
是LR-型模糊数,则
与
之间偏差平方距离定义如下:
(2)
其中,
。
当
和
是对称模糊数时,即
且
,
,距离定义为:
(3)
特别地,当
和
是对称三角模糊数时,即
,距离定义为:
(4)
2.2. 模糊自回归分布滞后模型
考虑模糊时间序列
,
,其中
是响应变量,
是解释变量,那么模糊自回归分布滞后模型具体如下 [19] :
(5)
其中,
是自变量向量,
是
滞后
阶的值,
是未知模糊系数向量,表示为对称三角模糊数,记作
,其中
为中心值,
为展形,
是随机模糊误差项。
2.3. 模糊半参数时间序列模型
考虑模糊时间序列
,则模糊半参数时间序列模型具体如下 [15] :
(6)
其中,
是待估计的实值系数,
是
滞后
阶的值,
是未知的模糊光滑函数,且
,
是协变量,
是随机模糊误差。
3. 建立模型
在本节中,我们结合神经网络和半参技术提出了自适应模糊时间序列模型,并给出了模型的算法步骤和拟合指标。
3.1. 基于BPNN的自适应模糊半参数时间序列模型
考虑一组模糊时间序列数据
,其中
。我们考虑以下自适应模糊半参数时间序列模型:
(7)
其中,
是模型中的未知实值系数,
分别是中心,左展形,右展形的随机误差,
是
的估计值,
是未知的光滑函数,
是协变量。该模型基于三个子模型。第一个子模型结合非参,考虑了中心和其滞后阶之间的线性关系和标量
之间的非线性关系,其他两个子模型在第一个模型的基础上分别考虑了左展形和右展形与其滞后阶和中心估计值
之间的线性关系。
根据Wang et al. [20] ,我们可以估计未知的光滑函数
:
(8)
其中,
且
为核函数
的带宽。
将(6)式代入(5)对应的第一个子模型中,得到中心,左展形和右展形的估计值,记作
:
(9)
其次,采用加权最小二乘法,我们可以估计未知的实值系数
,具体如下:
(10)
其中,
是
和
之间偏差平方距离,
是第t个残差对应的权重,残差越大的时间序列数据,权重越小,这样可以减弱异常数据对模型的干扰。
实际的模糊时间序列数据除了具有线性特征,还一般具有非线性特征。神经网络模型具有较强的学习能力和数据处理能力,能够挖掘数据背后复杂的甚至难用数学形式描述的非线性关系 [10] 。神经网络模型种类很多,其中基于误差反向传播算法的多层前馈神经网络,即BP神经网络,是应用最广的一种神经网络模型。
因此,本文针对残差序列中隐含的原始序列中的非线性关系,考虑了一个三层BP神经网络来逼近这种非线性关系,其中包含输入层,隐藏层,和输出层。假设BP神经网络有n个输入,则这个残差序列关系可写成:
(11)
其中,
,
,
分别是自适应模糊半参数时间序列预测模型得到的中心、左展形和右展形的残差,
,
,
是由神经网络决定的非线性函数,一般为logistic函数,即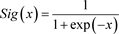 ,
,
和
分别是中心、左展形和右展形的随机误差。BP神经网络具体结构如图1所示:
,
,
和
分别是中心、左展形和右展形的随机误差。BP神经网络具体结构如图1所示:
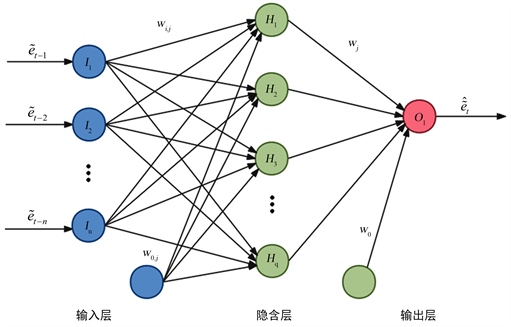
Figure 1. Structure of three-layer BP neural network
图1. 三层BP神经网络结构
通过BP神经网络估计的中心、左展形和右展形的残差
,
和
预测值分别记为
,
和
,那么将基于半参技术和加权最小二乘的结果
与BP神经网络所得残差估计值结合,则可以得到基于BP神经网络的自适应模糊半参数时间序列模型的最终估计值
:
(12)
3.2. 估计未知参数的算法
为了估计模型中的未知系数和未知光滑函数,本文提出了以下迭代算法过程:
步骤1:选择一个核函数,选择一个滞后阶数
,
,
,其中,中心,左展形和右展形的滞后阶数的上限由样本自相关系数决定;
步骤2:假定初始带宽
;
步骤3:利用初始带宽
和式(8)计算此时未知系数
;
步骤4:计算CV值,当CV值达到下确界时,此时
即为最优带宽
,否则,令
,回到步骤3,重复以上步骤;
(13)
其中,
是中心,左展形和右展形滞后阶数为
,带宽为
时的
的估计值。
步骤5:计算自适应模糊半参数时间序列模型的残差
,然后基于BP神经网络得到
,并根据式(12)计算得出
;
步骤6:选择另一组滞后阶数
,其中
其中
且
回到步骤2,并重复以上步骤,模型的拟合优度达到最大时就得了最优的系数估计值。
3.3. 模型评价
本文采用以下三个拟合指标来评价模糊时间序列模型的性能 [21] [22] :
(14)
其中,
,
越大,说明模糊时间序列模型的观测值与估计值越接近。
(15)
其中,
,
是[0, 1]的任意分区,
和
是
的
-水平截集的左端点和右端点。MD越大,说明模糊时间序列模型的观测值与估计值的拟合效果越差。
(16)
其中,
,
和
分别表示模糊数空间中的交集算子和并算子,
表示
的基数。贴近度S越大,说明模糊时间序列模型的观测值与估计值更接近,模型拟合效果越好。
4. 实证分析
在本节中,我们通过模拟仿真的例子来验证本文模型的可行性和有效性。考虑以下自适应模糊半参数时间序列模型生成的模拟模糊数据集样本,样本量为100:
(17)
其中,
,
和
分别是中心、左展形和右展形的初始值,并且
,
和
是来自
的随机样本,误差项
,
和
是来自
的随机样本,光滑函数
,其中
。
为了排除偶然性,我们将模型(18)拟合了1000次,以验证所提出模型具有可行性和有效性。同时,本文与Ozawa et al. [23] ,Li et al. [24] ,Hesamianand Akbari (2018) [15] 和Hesamianand Akbari (2022) [25] 提出的模型进行了比较。拟合优度均值比较结果见表1。从表1可以看出,本文提出的模型获得很好的拟合效果,具有可行性和明显的拟合优势。
图2描述了模糊预测值与模糊时间序列观测值的差异,模糊预测值与模糊时间序列观测值越接近,说明模型拟合效果越好。从图2可以看出,与其他四个模型相比,本文模型得到的模糊预测值与模糊时间序列的观测值最接近,偏差最小。

Table 1. The performances of various fuzzy time series models in example analysis
表1. 算例分析中各模糊时间序列模型的拟合指标
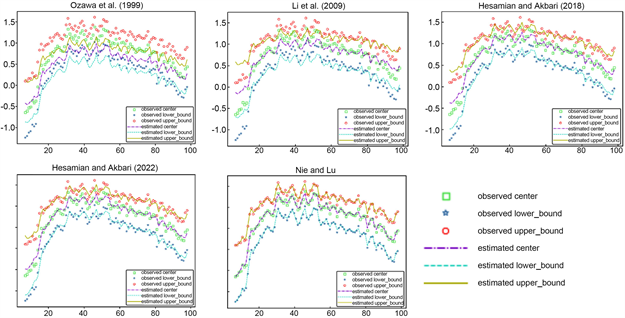
Figure 2. The observed and predicted values of each fuzzy time series model in example analysis
图2. 算例分析中各模糊时间序列模型输出的观测值和预测值
5. 结论
在许多时间序列建模中,与参数或非参数统计推断相比,半参数统计推断可能会产生稳健和灵活的结果。本文提出一种基于BP神经网络的自适应模糊时间序列半参数预测模型。该模型分别考虑了模糊数中心与其滞后阶之间的线性关系以及协变量之间的非线性关系,左展形和右展形和其滞后阶与中心估计值之间的关系。本文首次利用半参数技术建立了自适应回归模型中各元素之间的模糊关系。此外,基于非线性残差序列建立了BP神经网络,通过神经网络的运算得到了新的残差估计值,使得在模糊不确定条件下获得了更多的数据信息,提高了模型的预测精度。然后,本文采用一些常见的拟合优度准则,通过与现有模型的比较,验证了本文模型的可行性和有效性。最后,考虑多个异常值的组合存在的情况下,本文模型是否仍具有稳健性,将是以后研究的课题。
致谢
在此,我要感谢陆老师对这篇论文的指导。
NOTES
*通讯作者。