1. 引言
智能运维是将人工智能应用于运维领域,是以人工智能作为主导地位,由AI托管运维全程,通过机器学习从而发现和解决传统的自动化运维无法解决的问题。在智能运维中,异常检测、异常预测、趋势预测这三个问题的解决与否,是智能运维 [1] 能否正常进行的关键。
在29天内,对58个小区的运营商基站71个KPI的性能指标每一小时采样一次总共29 * 58 * 24 = 40,368条数据。
1) 选取小区内的平均用户数、小区PDCP流量、平局激活用户数作为三项核心指标。以这三项指标为关键指标检测出29日内全部小区所有的异常数据。
2) 预测未来三天上述三项核心指标的取值。
3) 利用(1)中得到的异常数值,建立预测模型,跟据模型输入时间跨度及输出时间跨度分析模型准确率,预测未来是否会出现异常数值。
2. 基本理论
2.1. Hampel滤波
Hampel滤波算法 [2] 是决策滤波器的一种,用于寻找信号序列中的异常值,并以较为合适的值代替异常值。该滤波器假设给定的数据集服从一个分布和概率模型,然后依据假设采用不一致检验处理信号序列。本质上是一种基于中值和MAD (median absolute deviation)尺度估计器的离群值检测程序。
具体来说,对输入序列D, Hampel滤波器的输出响应如下:
(1)
式(1)中的
是样本及其前
个样本组成的滑动窗口的中值,定义为
(2)
式(2)中,median是求给定数值的中值的函数。K是一个正整数,称为窗口宽度。
是MAD尺度估计,定义为
(3)
式(3)中,“1.4826”是一个工程经验值,它使MAD尺度估计成为高斯数据标准偏差的无偏估计。T是一个动态阈值调优参数设置为3,即查找与中位数相差超过3个标准偏差的样本,则认为该值为异常值。
2.2. BP神经网络
BP网络(Back-ProPagation Network) [3] 又称反向传播神经网络,通过样本数据的训练,不断修正网络权值和阈值使误差函数沿负梯度方向下降,逼近期望输出。它是一种应用较为广泛的神经网络模型,多用于函数逼近、模型识别分类、数据压缩和时间序列预测等。
典型的BP神经网络模型结构如图1所示,主要包括输入层、中间层(隐含层)及输出层。其中,中间层可以拓展为多层,相邻层之间通过各神经元实现全连接,而同一层之间的各神经元无连接,其信号从输入层经过中间层流向输出层。其运算流程主要分为两个阶段:样本信号的前向传播和转化,以及误差的逆向反馈。在信号前向传播的过程中,输入信号通过输入层的归一化处理以及隐含层的非线性计算,从输出层产生相应的输出信号。通过与实际输出信号进行对比得到误差,借由误差的反向传播,不断调整网络的权值和阈值,当得到的输出结果在预定的误差范围内时,网络训练结束。
BP网络由输入层、隐层和输出层组成,隐层可以有一层或多层,下图1是m × k × n的三层BP网络模型结构图,网络选用S型传递函数:
(4)
通过反传误差函数:
(5)
(Ti为期望输出、Oi为网络的计算输出)不断调节网络权值和阈值使误差函数E达到极小。
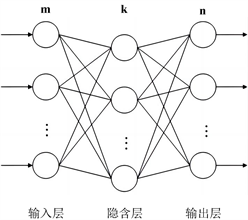
Figure 1. BP neural network model structure
图1. BP神经网络模型结构
2.3. 决策树分类器
ID3作为一种经典的决策树算法 [4] ,是基于信息熵来选择最佳的测试属性,其选择了当前样本集中具有最大信息增益值的属性作为测试属性。ID3算法根据信息论理论,采用划分后样本集的不确定性作为衡量划分样本子集的好坏程度,用“信息增益值”度量不确定性——信息增益值越大,不确定性就更小 [5] ,这就促使我们找到一个好的非叶子节点来进行划分。
假设一个这样的数据样本集S,其中数据样本集S包含了s个数据样本,假设类别属性具有m个不同的值(判断指标):
,Si是Ci中的样本数,对于一个样本集总的信息摘为:
(6)
其中,Pi表示任意样本属于Ci的概率,也可以用si/s进行估计。我们假设一个属性A具有k个不同的值
,利用属性A将数据样本S划分为k个子集
,其中Sj包含了集合S中属性A取aj值的样本。若是选择了属性A为测试属性,则这些子集就是从集合S的节点生长出来的新的叶子节点。
(7)
最后,我们利用属性A划分样本集S后得到的信息摘增益 [6] 为:
(8)
3. 模型建立与问题的求解
3.1. 异常检测
3.1.1. 高斯滤波平滑
高斯滤波 [7] 就是对整幅图像进行加权平均的过程,每一个像素点的值,都由其本身和邻域内的其他像素值经过加权平均后得到。高斯滤波器平滑处理后降低噪声的影响。采用高斯滤波器,系统函数是平滑的,避免了振铃现象。
3.1.2. 归一化处理
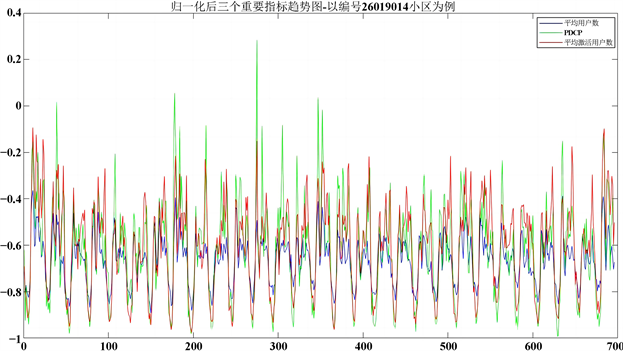
Figure 2. Trend chart of three important indicators after normalization - Take 26019014 as an example
图2. 归一化后三个重要指标趋势图-以编号26019014小区为例
由于该数据是否为异常数据受到多个指标的影响,将各项数据通过归一化处理,使各项指标处于同一量级,消除其它相关变量带来影响,而着重于看三个关键指标带来的影响,便于接下来的综合对比评价 [6] 。归一化后结果如上图2所示。
3.1.3. 皮尔逊相关系数
利用Matlab计算输出皮尔逊相关系数 [8] ,三项指标各自相关性如下:
l 小区内的平均用户数与小区PDCP流量的相关性:r = 0.9323
l 小区内的平均用户数与平均激活用户数的相关性:r = 0.9198
l 平均激活用户数与小区PDCP流量的相关性:r = 0.9248
据皮尔逊相关系数原理得,对于异常检测中三项指标两两相对,具有高度相关关系。
3.1.4. 使用Hampel滤波算法求解
在Hampel滤波算法的原理基础上,将经过高斯滤波平滑、归一化处理的指标数据导入Matlab,绘制原始信号、滤波信号和异常值,标注离群点位置。本文通过将附件1的数据导入Matlab,通过Hampel滤波函数进行处理,可以得到如下图3所示结果。

Figure 3. Hampel exception filtering
图3. Hampel异常滤波处理
3.1.5. 时间周期的选择
针对各个小区的三项核心指标,根据快速傅里叶变换算法(FFT)和互信息法 [9] ,计算出各个小区的时间周期;若计算出的时间周期大于12,就舍弃;否则就保留数值;最后将所有小于12的时间周期取平均值,获得时间周期的值。快速傅里叶变换周期功率下图4所示。快速傅里叶变换功率下图5所示。
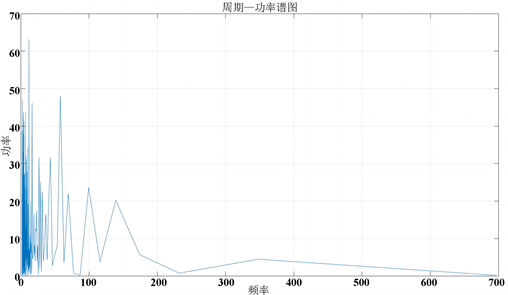
Figure 4. Fast Fourier transform periodic power diagram
图4. 快速傅里叶变换周期功率图
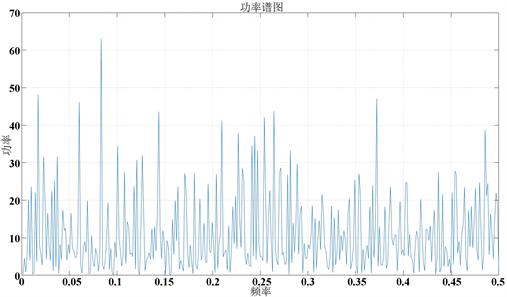
Figure 5. Fast Fourier transform power
图5. 快速傅里叶变换功率
3.2. 预测未来三天数据趋势
BP神经网络滚动预测模型 [10] 的建立采用Matlab内置方法newff进行建模和训练,经过多次实验,本方案将newff的各项参数设定为如下:第一个参数为经过Hampel滤波处理后的数据;第二个参数设定隐层神经元的个数为10个,输出层的神经元个数为1个;第三个参数设定隐层神经元传输函数为“tansig”,输出层传输函数为“purelin”;其余采用默认参数。通过Matlab内置的神经网络工具箱用梯度下降法对模型进行训练,实时滚动预测即采用神经网络进行单步预测,用t时刻的数据预测t + 1时刻数据,t + 1时刻将采集的实测数据用于t + 2时刻的预测,以此类推,滚动的补充新数据,剔除旧数据。实时滚动预测 [11] 也称为实时跟踪预测,由于每次预测都利用了最新的实测数据,预测的结果也更加准确。预测未来三天数据趋势下图6所示。

Figure 6. Forecast data trends for the next three days
图6. 预测未来三天数据趋势
3.3. 异常预测
3.3.1. 自相关系数分析
将三项关键指标数据与异常数据进行自相关性分析 [12] 。得出autocorr结果如下图7、xcorr结果如下图8所示。
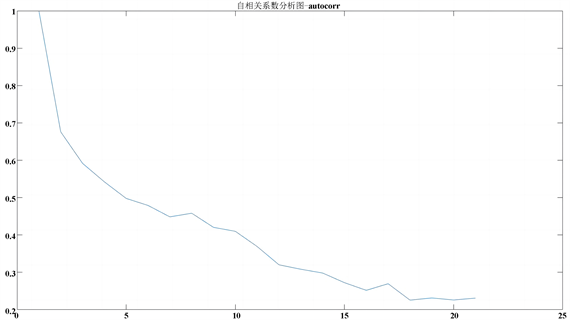
Figure 7. Autocorrelation coefficient analysis chart—autocorr
图7. 自相关系数分析图——autocorr

Figure 8. Autocorrelation coefficient analysis chart—xcorr
图8. 自相关系数分析图——xcorr
3.3.2. 皮尔逊相关系数分析选取指标数据
将三项关键指标数据与异常数据进行皮尔逊相关系数分析,对于相关系数:R ≥ 0.9,数据选为特征指标,得到与异常数据相关性较高的特征指标。结果分别见下表1~3。

Table 1. Correlation coefficients of other indicators corresponding to abnormal data of the average number of users in the community
表1. 小区平均用户数异常数据对应的其他指标相关系数
Table 2. Correlation coefficients of other indicators corresponding to abnormal PDCP data in the community
表2. 小区PDCP异常数据对应的其他指标相关系数
Table 3. Correlation coefficient of other indicators corresponding to abnormal data of average activated users
表3. 平均激活用户数异常数据对应的其他指标相关系数
3.3.3. BP神经网络滚动预测模型
BP神经网络滚动预测模型 [13] 的建立采用Matlab内置方法newff进行建模和训练,经过多次实验,本方案将newff的各项参数设定为如下:第一个参数为经过Hampel滤波处理后的数据;第二个参数设定隐层神经元的个数为10个,输出层的神经元个数为1个;第三个参数设定隐层神经元传输函数为“tansig”,输出层传输函数为“purelin”;其余采用默认参数。通过Matlab内置的神经网络工具箱用梯度下降法对模型进行训练,实时滚动预测即采用神经网络进行单步预测,用t时刻的数据预测t + 1时刻数据,t + 1时刻将采集的实测数据用于t + 2时刻的预测,以此类推,滚动的补充新数据,剔除旧数据。实时滚动预测也称为实时跟踪预测,由于每次预测都利用了最新的实测数据,预测的结果也更加准确。
3.3.4. 决策树分类器异常预测

Figure 9. Decision classification tree diagram
图9. 决策分类树图示
决策树分类技术 [14] 是数据挖掘中的高效技术,该技术利用属性比较方法获取样本分类结果。因为决策树是采用自顶向下的递归方式,从树的根节点,经过若干个叶子节点,每个叶子节点代表目标类别属性的值,故而我们把经过问题一处理后的数据进行分类,选取部分被问题一判定出的某一指标下的异常数据所占据的一行的所有数据,作为一个叶子节点的输入数据,满足该叶子节点的数据即为异常数据,否则进入下一叶子节点的判定,除了异常数据,本方案还会抽取部分正常数据作为其他叶子节点的数据 [11] ,最终异常数据和正常数据的数目比达到1:1。以上操作借助Matlab自带的统计工具箱函数ClassificationTree.fit (X, Y),即可完成决策树分类器的建立。在决策树分类器建好后本方案采用Matlab自带的统计工具箱函数eval (t, X),从正常数据与异常数据并存的混合数据中选取75%的数据,输入决策树分类器中,对决策树分类器进行训练。最终训练出的决策分类树结构见上图9。
4. 结果
数据分析
本文通过BP神经网络滚动预测模型分别对决策分类器指标小区内用户平均数、决策分类器指标小区PDCP流量和决策分类指标平均激活用户数进行检测 [15] 。检测结果如表4~6。
Table 4. Test the average number of users in a decision classifier index cell
表4. 对决策分类器指标小区内用户平均数的检验
Table 5. The test of PDCP traffic in decision classifier index cell
表5. 对决策分类器指标小区 PDCP 流量的检验
Table 6. Test the average number of active users of the decision classifier index
表6. 对决策分类器指标平均激活用户数的检验
5. 结语
本文数据进行预处理时采用一维高斯函数、归一化处理,一维高斯系统函数是平滑的,避免了振铃现象,归一化处理使各指标处于同一数量级,适合进行综合对比评价。分别对于不同的指标小区内用户平均数小区内用户平均数、小区PDCP流量小区PDCP流量数、平均激活用户数平均激活用户数正常值确定率为84.0491%,p1 = 81.573%,p1 = 84.1004% p1 = 84.1004%,异常值确定率为p2 = 84.2105%,p2 = 83.9713%,p2 = 82.1818%。
建立模型时,选择建立的BP神经网络滚动预测模型,该模型属于BP神经网络模型,而BP神经网络具有较强的非线性拟合能力、容错能力。
基金项目
西藏大学2022年大学生创新训练项目(2022XCX083)。
参考文献
NOTES
*通讯作者。