1. 引言
命名实体识别(NER)是指在中文文本中识别出实体的边界和类别。它是关系抽取、事件抽取、知识图谱、信息抽取、问答系统、句法分析、机器翻译等众多自然语言处理(NLP)任务的基础,被广泛应用于自然语言处理领域并发挥着重要作用,用于识别文本中的实体。命名实体识别通常从实体注释开始,然后识别单个实体,最后识别复合实体。
NER技术主要有以下方法:基于规则和词典的方法、机器学习的方法和基于深度学习的方法。基于规则和词典的方法 [1] 因依赖于手工指定的原则从而不需要对数据进行标注,但容易出错。Collins等人 [2] 发现未标记示例对于命名实体分类会产生影响,要想减少这些影响,需要制定大量规则用来提高实体识别的效率。随后许多机器学习算法被应用于监督NER中,包括HMM [3] 、SVM [4] 和CRF [5] 等,这些模型利用监督学习算法对特征进行仔细标记。乐娟等人 [6] 将隐形马尔可夫模型(HMM)和Viterbi算法结合来识别京剧机构命名实体。Bender等人 [7] 在命名实体识别系统中利用最大熵模型(MEM)来提高实体识别的准确性。段少鹏等人 [8] 提出基于条件随机场(CRF)和支持向量机(SVM)的双层模型对老挝的组织名称进行识别。
最近几年,由于深度学习能够从文本中挖掘隐含的信息,在自然语言处理中得到了越来越多的关注。NER算法能够充分发挥深度网络的非线性特性,实现对数据的有效提取。与现有方法(如HMM和CRF)相比较,深度学习方法可以利用神经网络的非线性激活函数,从海量的数据中提取出复杂特征信息。与基于特征的方法相比,深度学习方法可以从输入中自动发掘信息以及学习信息的表示,从而不需要过于复杂的特征工程。深度NER模型采用端到端模型可以避免流水线(pipeline)类模型中模块之间的误差传播还可以承载更加复杂的内部设计,最终产出更好的结果。凌媛等人 [9] 在LSTM-CRF模型的基础上提出增强的LSTM-CRF疾病命名实体识别,在字符输入处理中添加了CNN与LSTM,提高了疾病识别的有效性。由于单向长短期记忆网络只能从前往后读取信息,不能更好的理解词语间的修饰作用,所以提出了双向长短期记忆(BiISTM [10] )网络。万忠宝等人 [11] 提出融合双向长短时记忆网络(BiLSTN)、注意力机制和条件随机场(CRF)的中文命名实体识别的模型来提高命名实体识别的性能和效率。这些方法虽然在NLP领域取得了一定的效果,但实体识别的效率上还需要进一步提升。谷歌在2018年提出BERT模型 [12] ,具有强大的语言表示能力,可以对单词进行动态建模以获得更多上下文语义表示。李伟等人 [13] 利用BERT-BiLSTM-CRF模型预测未标记数据的实体标签得到可靠的数据扩展到初试训练数据集在重新训练,证明了模型的有效性,为教育舆论中的命名实体识别问题提供了解决方案。Liu等人 [14] 将BERT-BiLSTM-CRF模型应用到了历史领域,用来提取非结构数据中的实体信息。胡薇薇等人 [15] 通过改进BERT并结合CRF将其注入到知识图谱中,提高了整体性能。李凯微等人 [16] 提出改进BERT模型,并使用BiLSTM、IDCNN和CRF来提高对JAVA知识点的实体识别。
2. RoBERTa-CNN-BiLSTM-CRF模型
2.1. 模型概述
本文提出了RoBERTa-CNN-BiLSTM-CRF模型结构如图1所示,模型由4个模块组成分别为RoBERTa模块、CNN模块、LSTM模块和CRF模块。RoBERTa模块对输入文本进行预训练提取数据的语义特征,将得到的语义特征作为CNN模块的输入提取局部特征并进行输出,然后输入到LSTM模块,LSTM模块预测实体标签的概率分布。最后通过CRF模块将这些实体表情的概率分布进行解码操作,解码出相应的实体标签进行输出。该模型图如图1所示:
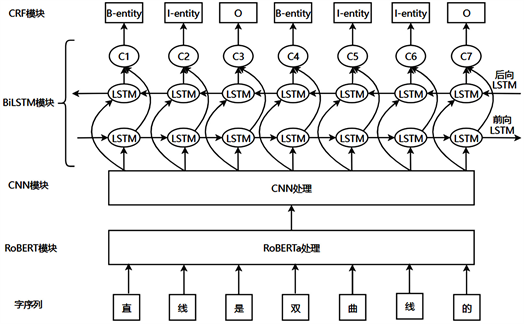
Figure 1. Structure diagram of the RoBERTa-CNN-LSTM-CRF model
图1. RoBERTa-CNN-LSTM-CRF模型结构图
算法描述如下:
输入:中文语句
输出:中文语句预测标签
算法步骤:
(1) 将输入的文本分解成对应的字序列;
(2) 将字序列输入到RoBERTa模块中,得到字符特征向量;
(3) CNN模块利用CNN获得每个字符的特征;
(4) BiLSTM模块通过BiLSTM计算输入隐藏信息;
(5) 利用CRF模块对BiLSTM模块输出进行解码,求解。
2.2. RoBERTa模块
RoBERTa模型是BERT的改进版。与BERT相比,RoBERTa具有更大的训练集更大的数据样本数量、不需要使用下一句预测任务、使用更长的训练序列和动态掩码。这样可以在大量数据不断输入的过程中,模型会逐渐适应不同的掩码策略,学习不同的语言表征,提高了模型输入数据的随机性,最终提升了模型的学习能力。RoBERTa模型主要对语言模型完成训练和处理,确定各个句子语义之间的相互关系并进行处理,整个模型架构分为输出层、编码层与输入层三层对数据进行处理。在利用RoBERTa模型对数据进行处理过程中,模型中的双向Transformer编码层对数据的特征进行提取与分析起到了关键的核心作用。Transformer编码层主要采用Encoder特征提取器通过计算注意力权重并进行归一化来计算语义向量,计算公式如下:
(1)
其中
向量为每个字向量与
三个参数矩阵计算得到的,
为输入向量的维度。通过编码层处理后的字符特征向量由输出层输出,作为CNN模块的输入向量。
2.3. CNN模块
卷积神经网络(CNN)是一种专门用来处理具有类似网格结构的数据的神经网络,它不仅广泛应用于计算机视觉领域,也应用于自然语言处理的特征抽取中。在NLP任务中将句子或文章作为一个矩阵来输入给CNN网络,可以用一个词语或者一个字符来表示矩阵中的每一行。再利用卷积层和池化层进行降维操作,提取句子中的局部特征。卷积层和池化层的计算公式如下:
卷积层计算公式:
(2)
池化层计算公式:
(3)
其中
为卷积层输出特征图,
为输入特征图,
为卷积核,
为偏置向量,
为卷积核的数量,
为池化层输出特征图,
为输入特征图,
为池化窗口大小。卷积层使用卷积核滑过矩阵的整行,再经过池化层提供一个固定大小的输出矩阵用于分类,减少输出矩阵的维度,同时保留句子中的特征。最后连接全连接层,得到分类结果。
2.4. BiLSTM模块
长短期记忆网络(LSTM)是对循环神经网络(RNN)进行了改进,由于其加入了门结构,更有选择地保存上下文信息。LSTM由3个门单元模块组成分别为输人门、遗忘门及输出门。遗忘门决定了之前的记忆中需要被遗忘的信息;输入门决定了新的输入信息对记忆的影响;输出门决定了记忆中的信息如何被传递给下—输出层。其计算公式如下:
遗忘门计算公式:
(4)
输入门计算公式:
(5)
(6)
输出门计算公式:
(7)
长记忆计算公式:
(8)
短记忆计算公式:
(9)
首先遗忘门将
和
作为输入,将
中的各个数字输出0~1的值用来表示保留信息的多少。其次由输入门层来决定更新某些值,并与
层创建的
候选值向量相结合共同来更新信息。再将
和
相乘,
和
相乘并相加得到更新后状态
。最后将
的值进行规范化与输出门参数
进行点乘,得到过滤后的信息并输出。这使得LSTM能够有效地处理和记忆长距离依赖关系。
BiLSTM在LSTM的基础上添加了反向计算,即将输入的序列进行反转,对反转后的序列重新按照LSTM的方式进行计算并输出,最后将正向LSTM的隐向量和反向LSTM的隐向量进行拼接,得到最终的隐向量。
所以将CNN和双向长短时记忆网络(BiLSTM)结合,即利用CNN编码得到每个段落的embedding,再将其送到LSTM里拿到LSTM隐向量。CNN能够有效地处理输入数据的局部特征,BiLSTM的双向性能够使模型同时考虑过去和未来的信息,从而更好地抓住序列数据中的上下文信息,这样能够学习到局部和全局特征,并且可以自适应地去提取特征,从而在处理序列数据时具有出色的表现。但BiLSTM只能挑出每个词的最大概率值的label进行输出,并不能学习到输出的各个标注之间是否存在转移依赖关系和序列标注的约束条件,所以引入了CRF层来学习序列标注的约束条件,确保预测出的结果的准确性。
2.5. CRF模块
条件随机场(CRF)负责学习相邻实体标签之间的转移规则,当预测序列的每一个位置的输出状态,需要考虑到相邻位置的输出状态。CRF的核心作用是建模标签之间的依赖关系,目标是学习隐形变量到观测值的发射概率,以及当前观测值和下一个观测值之间的转移概率。CRF的损失函数主要包括两个部分,分别为
和
,其中
表示所有路径分数
表示真实路径分数,计算公式如下:
计算公式:
(10)
(11)
损失函数定义:
(12)
其中
为发射分数,
为转移分数。损失函数的值越大说明得到的序列越优,那么该序列就是所有序列中的最优序列,即识别的准确率越高。
3. 实验结果分析
3.1. 实验数据集
本实验采用高中数学知识作为数据集,数据集主要来源于高中数学人教版课本、百度百科和百度文库等包含高中数学知识点的相关语句。本实验包含了数据集样本,实体,训练集以及测试集。数据集样本的数量为9271个,实体数量为2225个,训练集数量为6271个,验证集数量为1500个,测试集数量为1500个。
3.2. 数据集标注及评价指标
本实验采用BIO实体标注方法,B表示每一个标记实体的开始,I表示每一个实体的其余部分,O表示非标注实体 [17] 。实验的主体主要分为两类:B-entity和I-entity,标注结果(部分)如表1所示:

Table 1. BIO annotation results (partial) table
表1. BIO标注结果(部分)表
本实验选用精确率、召回率以及
指数作为评测指标,具体计算方式如下:
定义
为实际为正例且预测正确的数量,
为预测为正例但实际为反例的数量,因此有精确率:
(13)
定义
为实际为正例但预测为反例的数量,因此有召回率:
(14)
指数计算公式为:
(15)
3.3. 实验环境配置及参数
实验中使用设备配置如表2所示。
Table 2. Experimental environment configuration table
表2. 实验环境配置表
实验中使用的参数如表3所示。
Table 3. Experimental parameter table
表3. 实验参数表
3.4. 实验结果与分析
为验证试验结果,使用高中数学知识数据集,分别使用BERT-CRF模型、BERT-BiLSTM-CRF模型、RoBERTa-BiLSTM-CRF模型以及RoBERTa-CNN-BiLSTM-CRF模型对高中数学知识数据集进行命名实体识别实验,结果如表4所示。
Table 4. Comparison table of model experiments
表4. 模型实验对比表
由实验结果数据可知,文中使用的RoBERTa-CNN-BiLSTM-CRF模型在精确率、召回率和
值都高于该实验模型中的其它模型,并且各个评测指标分别达到94.32%、94.58%、94.45%。由下表可知本文中使用的RoBERTa-CNN-BiLSTM-CRF模型在处理高中数学知识命名实体的识别中具有很大的优势。
3.5. 模型测试
为验证RoBERTa-CNN-BiLSTM-CRF模型的准确性,对模型进行测试,选取导数应用这个知识点进行测试,测试结果如表5所示。
Table 5. Comparison table of model test results
表5. 模型测试结果对比表
针对导数应用这个知识点的描述,分别利用四个模型进行测试,由上表发现BERT-CRF模型、BERT-BiLSTM-CRF模型和RoBERTa-BiLSTM-CRF模型对高中知识点中的“增函数”和“减函数”这两个实体识别的不是非常准确,而RoBERTa-CNN-BiLSTM-CRF模型能够准确的识别出“增函数”和“减函数”这两个实体,具有较高的准确性。
4. 结束语
本文是针对中文的文本实体进行识别本文提出RoBERTa-CNN-BiLSTM-CRF模型,RoBERTa模块将输入文本进行预处理得到表示上下文语义特征信息的词向量,再通过CNN模块获得字的特征来补充词向量,然后通过LSTM模块对生成的词向量进行特征提取,最后通过CRF进行解码。实验结果表明,该模型在高中数学知识实体识别中取得了很高的精确率、召回率和F1值,分别达到94.32%、94.58%、94.45%。对比实验结果表明,本文提出的模型在和其他模型对比中各方面的性能为最高。由于该实验的是在特定的数据集下取得了很好的效果,下一步的工作,考虑将其应用到其他数据集中,观察其性能,并对其进行相应的优化和改进。
基金项目
辽宁省教育厅高校基本科研项目(JYTMS20231226),面向多模态大数据的智能感知技术研究。
参考文献