1. 引言
复合材料是具有优良性能的新型材料,由多种属性不同材料组成,它比组成的原始材料更坚硬,更耐磨,更轻 [1] 。尽管复合材料有这些出色的优点,但是,复合材料结构在制造和使用的过程中容易受到各种损伤,从而显著地改变了它们的结构行为,最终导致结构失效或者使用寿命减少。为了保证复合材料结构的结构安全,当结构受损时,尽早知道损伤的具体情况是十分关键的。但是复合材料的各向异性特性使得一般的检测方法较难进行损伤评估。目前有许多无损检测技术NDT (Non-Destructive Testing)可用于检测复合材料结构内部的缺陷,如红外热成像检测 [2] ,声发射检测 [3] 等,虽然这些无损检测技术现如今很成熟,但是其中的大部分技术并不能按照最开始所设想的那样,直接使用检测设备进行无损检测,除了相关的仪器之外,还需要技术娴熟的操作员以及特定的检测环境。对于结构表面损伤,常采用目视检查技术。此外,目视检查也是许多现实实例中使用的最基本的NDT类型。因为它可以通过减少其他种类测试措施来节省检测所需要的时间和金钱,或者在某些特殊情况下同时减少对其他类型测试的需要,目视检查主要的优点就是速度快和相对承受性高 [4] ,但是检测的准确性也取决于检查员的判断能力。照明、检查的时间、检查员的疲劳和经验、环境条件等因素都会影响检查员的判断力,进一步影响目视检测的可靠性和检测成功的概率,随之就带来了健康和安全风险等问题。
近年来,随着科技发展,计算机硬件可以提供充足的算力,人们在自动化、数据分析、图像采集技术、人工智能技术等方面的取得了较大进步,使得低成本硬件的计算能力能够满足软件的计算需求,这也让搭建一个实用的自动视觉检查系统成为了可能 [5] 。Min Ma等人 [6] 使用一维多尺度残差卷积神经网络对碳纤维增强聚合物CFRPs (Carbon Fiber Reinforced Polymers)进行损伤检测,基于仿真软件和实验获得CFRPs的损伤图像构造数据集。实验中训练所提出的网络结构,并根据测试数据集结果对该算法进行评估。该方法的决定系R2数为0.885,是该组网络架构中最高的网络结构,说明了模型的拟合效果较好。
过去提出的CNNs (Convolutional Neural Networks)在基于图像的数据上的应用中,所获取的图像都是通过NDT获得,如热成像和X射线,NDT需要专业的设备以及经验丰富的操作员获取。这些研究的专业性和难度较大,不利于其他学科的学者了解。为了解决这个难题,本文提出了一种基于深度学习的复合材料层合板损伤检测方法,通过在网络和相关文献中寻找损伤图像数据和未损伤图像数据构造数据集,训练多个神经网络并找出一个适用于评估复合材料层合板中的服役损伤情况的网络。最后通过优化算法结构提高网络的稳定性和准确性来实现有效的复合材料无损检测,大大降低复合材料结构检测成本,提升了复合材料结构的安全性。
2. 相关理论
2.1. 数据获取与增强
本文收集到的部分图像数据如图1所示,从不同厚度、材料、叠层、纹理等方面的复合材料层合板的文献中收集了一套全面的图像,包括未受损和受损伤图片。图像数据集总共包括177张损伤图片,63张表面完整复合层合板图像图片图像在参考文献 [7] [8] [9] [10] [11] 中获得。
2.2. 数据增强
卷积神经网络(CNNs)的优秀泛化能力需要依赖大量的训练数据,而大量数据在工业实践中是难以获得的,数据增强通常被认为是解决这一问题的有效策略。数据增强能将较少的数据数量提升数倍,数据集样本的多样性和训练模型的鲁棒性都有足够的保障。训练过程中较少的样本所具备的特征信息不够充足,将会导致模型过度依赖某些属性,泛化能力不足,而使用数据增强方法可以避免这种情况出现。
现在,主流的增强策略分为几何变换和像素变换。几何变换包括平移,旋转和缩放等;像素变换方法有添加不同的噪声,调节亮度和改变饱和度等。在本文的实验研究中,将采用如下三个方法:第一个是旋转方法,2次幅度为90˚的角度旋转;第二个是翻转方法,将图像按照水平方向镜面翻转;第三个添加噪声,给图像加上高斯和椒盐噪声。
使用数据增强方法来获得更多的学习数据,每幅原始图像总共产生5张图像。由于采集图像的高宽比不一致,每张图像根据图像的自身条件进行不同形式的增强 [12] 。本文准备使用三种增强方法包括旋转90˚和180˚,水平翻转以及添加高斯噪声和椒盐噪声两种噪声,五种增强图像结果如图2所示。
在本文中,将2.1节所得到的240张图片随机选取145张作为训练集,48张作为验证集,47张作为测试集。通过上述的数据增强方法,使得训练集和验证集数据量被增加为原来的6倍,由193张变成1158张。

Figure 2. The result of the image augmentation
图2. 数据增强结果图
2.3. 基础网络模型
2.3.1. AlexNet模型
AlexNet网络是最常用的CNN架构之一,已经成功地训练了超过100万张图像,是广泛应用于图像分类的最有影响力的CNN,并以15.3%的小错误率获得了ImageNet LSVRC-2012比赛的第一名 [13] 。该模型的意义在于能够提取有关图像的实际信息,并了解每一层中添加的特征。该网络总共包含8层学习层,网络的前大半部分使用卷积层和池化层来提取特征信息,后半部分使用全连接层。在网络中还使用了Dropout策略,通过随机失活部分层的神经元,避免网络过拟合现象。因为AlexNet在ImageNet数据集上进行预训练的分类任务为分类大量类别图像,而损伤检测只包含2个类别(损伤和未损伤),所以本文将输出向量修改为只有2个类,即输出层采用了分类数设置为2类的Softmax激活函数。
2.3.2. VGG模型
VGG网络最早由Visual Geometry Group提出,网络也是沿用该团队的名称,该模型在ImageNet中实现了92.7%的top-5测试准确率 [14] 。卷积神经网络的深度与模型性能关系是VGG网络主要研究的对象。它的特点是结构简洁。在这个模型中,它的目标不是有更多的超参数,而是反复堆叠具有步幅为1的3*3滤波器的卷积层和步幅2的2*2滤波器的最大池层。VGG16是单向多层结构,其名称中的16代表网络层数,它大约含有1.38亿个参数。此外,在本研究中使用pytorch搭建VGG16预训 练版本,在ImageNet上训练的模型分类数目是1000,针对于本文所研究的损伤检测任务,将输出分类改为两类。
2.3.3. ResNet模型
ResNet是2015年的ImageNet大规模视觉识别竞赛中最引人注目的项目,由前微软研究院的何凯明等4人共同合作研究的一种新型卷积神经网络 [15] 。自从VGG提出之后,研究者们就开始相信只要提高网络深度就可以直接简单地增加预测精度,但是现实实验结果并非如此,越是深层的卷积神经网络,其模型参数会指数级增长,导致网络优化困难并且会出现梯度消失问题。而ResNet的设计概念改变了深度学习的发展方向,该网络通过提出跳跃连接的方式来缓解上述问题,跳跃连接应用于网络内部的残差块中,使得参数易于优化,最终提高了网络的性能。图3即为残差块,其中x表示输入,残差块的输出就是F (x) + G (x)而不是传统网络层的F (x)。当输入和输出的维数是相同的时候,函数G (x)的取值就是x本身,此时跳跃连接称为恒等映射。因为恒等映射剔除了中间层的权重,所以可以更加容易的训练网络。
现在已经有许多版本的ResNetXX架构,其中“XX”表示层数。在ResNet34中,网络层数是34。默认情况下,预训练的模型分类输出类别是表中显示的1000,但在本文执行的实验分类数目是2类,所以前两个网络模型处理方式相同,将最后的softmax分类层改成2。
3. 实验与结果分析
3.1. 实验环境
本文的实验都是在具有以下环境配置的设备上进行的:处理器为12th Gen Intel (R) Core (TM) i7-12700H 2.30 GHz,内存16 GB;显卡是NVIDIA GeForce RTX 3060。编译工具Pycharm,采用python3.8编译语言。
3.2. 实验评价标准
实验评价标准为测试集中模型预测的精确度(Accuracy),计算公式(1):
(1)
其中,TP指的是预测正确的样本数,NUM则指的是测试集总共的样本数。
3.3. 模型训练
实验中bachsize设置为64,训练20个epoch,输入图片大小是224*224。训练过程中优化参数的优化器为Adam优化器,该优化器初始学习率设置为0.00001。选择使用交叉熵损失函数,它可以写成公式(2)的形式:
(2)
其中,N是图像数目,
表示样本k的标签,
表示样本k预测为正类的概率。
实验一共1205张图片,训练集、验证集和测试集将按照数据集6:2:2进行划分,其中使用增强后的870张用于模型训练,288张用于模型验证和未增强的47张用于模型测试。实验中根据验证集结果保存网络分类性能最好的权重参数,然后使用与训练样本不同的测试集评估模型的性能,将不同网络模型的测试集结果收集起来进行对比实验。
3.4. 结果及数据分析
3.4.1. 测试集结果比较
本文使用了AlexNet、VGG16和ResNet34三个模型进行对比实验,测试结果根据上文提及的实验评价标准的计算公式,可以得到模型的测试精确度。精确度是指在测试集所有图像中正确分类的图像的数量,3个模型的实验结果如表1所示。

Table 1. The experimental results of the test set
表1. 测试集实验结果
通过表1可以看出,3个网络模型的验证精度都是非常的高,基本都在80%以上,其中提出时间较早的AlexNet和VGG16网络精度都达到了97.87%,而之后提出的网络模型ResNet34的测试精度只有87.23%,这表明了越先进的神经网络并不一定适用于复合材料层合板无损检测领域。
为了进一步比较网络的性能,将三个模型的混淆矩阵绘画出来。如图4所示:
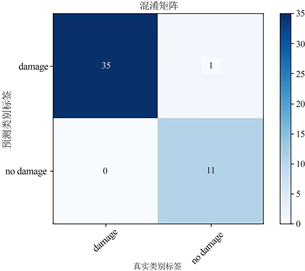
(a) AlexNet网络
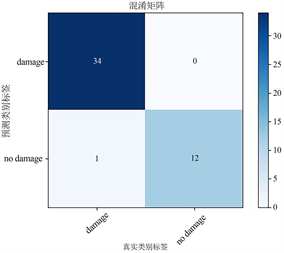 (b)VGG16网络
(b)VGG16网络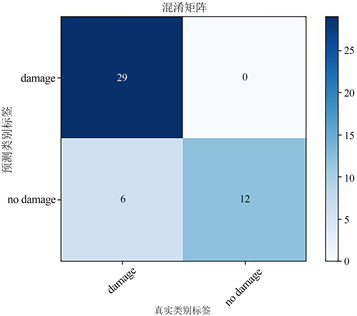 (c) ResNet34网络
(c) ResNet34网络
Figure 4. Confusion matrix diagram for different networks
图4. 不同网络的混淆矩阵图
从图4的混淆矩阵图可以看出,虽然AlexNet和VGG模型的测试集分类准确率相同,但是分类错误的情况不一样,AlexNet是误将无损伤的图像分类成了损伤图像,而VGG模型是将损伤的图像错误分类成了无损伤图像,在现实应用场景中的这个现象会导致巨大的事故,造成无法挽回的经济损失。因此结合混淆矩阵图可以得出最适合与复合材料层合板无损检测的神经网络模型为AlexNet。
3.4.2. 训练过程分析
为了进一步验证上文得出的实验结论的正确性,将三个不同模型的验证过程中的精度和损失的详细图绘制成图5所示:
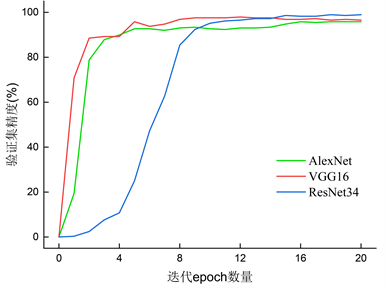 (a)验证集精度
(a)验证集精度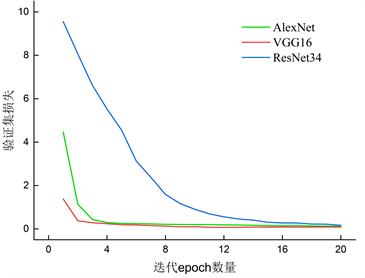 (b)验证集损失
(b)验证集损失
Figure 5. Iteration curves of each model
图5. 各模型迭代曲线
从图5中可以清晰的观察到三个模型的验证精度和损失值大小。其中AlexNet最大验证精度为95.83%;VGG16最大的验证精度为97.92%;ResNet34网络最大验证精度为98.95%。三个网络模型的验证精度相差范围不大。从模型验证损失可以看出ResNet34网络相较于前两个网络损失始终更大,这也说明了ResNet34网络并不太适用于复合材料层合板无损检测。虽然在模型验证损失AlexNet与VGG16模型的差异较小,但是AlexNet训练验证20个epoch所花费的时间为66秒,而VGG整个训练过程需要4431秒。因此,从时间方面来看,AlexNet训练时间少,从而消耗更少资源,更符合现实应用场景的需求。
4. 结论
本文采用深度学习技术对复合材料层合板进行损伤检测。根据网络和相关文献中的复合材料层合板图像构造数据集,并且使用几种不同的数据增强技术扩大了数据集的规模。在实验中比较了预训练后的AlexNet、VGG16和ResNet34三种不同模型在测试准确率以及训练模型的时间方面的性能。根据实验结果分析可以得出结论,AlexNet适用于对复合材料层合板图像进行分类,因为与其他模型相比,该模型训练所花费的时间最少且测试精度能够保持在较高水准。本文提出的基于深度学习的复合材料层合板损伤检测模型,可以为复合材料层合板检测提供一种新的检测技术。
基金项目
国家自然科学基金(62366033);南昌航空大学重点科研基地开发基金(EW202107216)。
NOTES
*通讯作者。