1. 引言
根据心理学的研究 [1] 人们通过以下信息传播情感:55%的信息通过脸部表情传递。微表情是一种持续不到0.5秒的短暂面部表情 [2] ,并且可以在0.5秒内传递出丰富的情感和信息。这种微妙而敏捷的表达方式在交流中扮演着不可忽视的角色。因此,微表情在谎言测试和行为分析领域表现出潜在的巨大应用前景 [3] [4] [5] [6] [7] 。这些微小而瞬时的面部变化不仅可以作为信号指示谎言,还可用于对精神疾病等疾病的评估诊断。在教学评估方面,微表情的识别可以为教育工作者提供更全面的学生情感反馈,从而优化教学方法。此外,在交流谈判中,对微表情的解读也可以为参与者提供额外的洞察力,促进更有效地沟通。在公安侦查领域,微表情分析有望成为一种新型的犯罪调查工具,帮助警方更准确地理解被调查者的真实意图。这种多领域的潜在应用使得微表情研究不仅仅是心理学领域的一项重要工作,更是跨学科合作中的关键组成部分。
1966年,Haggard和Isaacs发现瞬间微表情,随后Ekman等人提出BART短表情识别方法 [8] [9] [10] 。Ekman随后在对日本人和高加索人进行的短暂表情识别测试中,引入了JACBART方法 [11] 。1978年,Ekman创建了Action Unit (AU)与情感的面部动作编码系统,精准记录AU时间、Onset、Offset和Apex [12] [13] 。当前研究中,许多学者选择使用微表情视频序列进行研究。Apex帧的准确定位对微表情识别的准确性产生重要影响,因此准确定位Apex帧一直是研究者们追求的目标。
微表情识别算法根据特征提取的时刻位置不同可划分为两个类别 [14] 。首先是基于序列的方法,从微表情图像序列的每一帧或采样帧中提取特征 [15] [16] [17] [18] 。而另一类是基于峰值帧(Apex)的方法,以起始帧(On-set)为基准,相对于基于序列的方法,基于峰值帧的微表情识别方法专注于提取关键时刻,以最小帧数保留最显著的微表情信息,突显情感传达的关键瞬间 [19] [20] ,因此在实际应用中更为优越。因此,目前许多学者倾向于基于Apex帧进行面部微表情识别研究。
对于Apex帧的检测,当前研究主要分为两个方向。一方面是基于时空域提取微表情Apex帧的方法,其中Patel等学者 [21] 采用在小的局部空间区域上计算的积分光流向量,以识别视频的起始帧和偏移帧。S.-T. Liong等研究者 [22] 则采用局部二值模式和光流的二值搜索策略,在有趣的面部子区域上辨识微表情视频序列中的峰值帧。Liong等人 [23] [24] 提出了特征提取算法Bi-WOOF和OFF-ApexNet,用于识别人脸微表达视频序列的起始帧和峰值帧。Xu等人 [25] 通过结合双重注意力模型和迁移学习提升微表情识别准确性。温等人 [26] 则使用顶峰帧光流和卷积自编码器。峰值帧图像采用 [27] 等人的帧间差分方法提取。
另一方面是基于频率域提取微表情Apex帧的方法。Zhao等学者 [28] 提出了3D快速傅里叶变换来辨认微表情视频的峰值帧,结合了频域和时空连续变化信息。Li Y等研究者 [29] 则提出了基于频率的方法,通过分析面部肌肉变化在频域的变化表示来确定峰值帧。
由于微表情的公开数据样本规模小,一些算法,如CMED-3DFFT [25] 和DCNN [28] ,需要大量的样本进行训练。为了弥补这一不足,本文提出了一种创新性的方法,结合了多特征融合和背景建模的思想,以在有效减少计算量的同时,实现对微表情Apex帧的准确检测。这一方法引入了背景建模和离散傅里叶变换,是本文的主要创新点之一。
2. 基于多特征融合及背景建模的微表情Apex帧检测
本文提出的基于多特征融合及背景建模的微表情Apex帧检测其技术框架如下,包括人脸检测、面部特征提取、微表情Apex帧提取三个阶段,如图1所示,首先对原始微表情视频或图像序列通过深度残差网络模型对图像进行人脸检测;其次进行面部特征提取,在面部特征提取时需考虑眼镜边框对提取人脸图像特征的影响,本文使用基于RGB颜色特征方法从人脸图像中提取出人脸肤色区域,通过使用基于关键点检测的算法,我们能够从人脸图像中提取关键点的坐标信息。这些关键点通常包括人脸的眼睛和鼻子等特定位置。将这些关键点映射到肤色区域之后,我们进行了二值化处理,接着提取最大连通域,以获取人脸面部的特征信息。这一过程有助于准确捕捉人脸在图像中的关键特征。然后在最大连通域内对图像进行背景建模,提取前景变化区域,获取运动区域图像;最后对变化区域进行统计,得出最大前景区域所在的帧序号,作为微表情Apex帧。图2为相应的流程示意图。
2.1. 基于深度学习的残差网络的人脸检测
基于深度学习的残差网络对输入的微表情视频或微表情图像序列进行人脸检测,截取图像中的人脸并进行尺寸归一化。
本文中所用的深度学习模型为resnet10网络模型,该模型具有检测人脸效果好、速度快等优点。
2.2. 最大连通域的面部特征提取
为了更准确地检测脸部微表情,本文将肤色提取和人脸关键点检测相融合。通过融合基于RGB颜色特征的方法和基于关键点检测算法,我们能够在人脸图像中更有效地提取人脸肤色区域,并准确获取人脸关键点的位置。这种综合的方法有助于定位微表情发生的区域,同时正确分离无关的信息,使我们能够专注于提取与微表情相关的关键信息。
1、基于RGB颜色的肤色检测方法。
对于给定的包含人脸的图像I,人脸前景分割问题定义如下:
定义1 对于给定的人脸彩色图像I,表示如下:
(1)
其中:
表示
处的像素值;Ω为整个图像区域。
肤色前景定义如下:
定义2 将肤色前景S定义为人脸图像的一个子集
,该子集中包含了尽可能多的肤色点。以下是模型的表示:
(2)
其中
是S中肤色点的像素数,表达式如下:
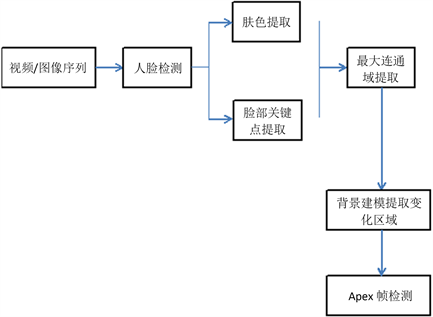
Figure 1. Micro-expression Apex frame detection framework based on multi-feature integration and background modeling
图1. 基于多特征融合及背景建模的微表情Apex帧检测框架
(3)
在RGB彩色模型中,由于肤色的呈现受到亮度变化的显著影响,我们采用了一系列复杂的约束条件,以精确筛选出图像中的皮肤区域。在这一模型中,肤色的取值范围需符合以下约束条件:
(R,G,B) > (95,40,20)
max(R,G,B) − minmax(R,G,B) > 15
|R − G| > 15
R > G
R > B
2、基于关键点定位方法。
人脸关键点检测主要用于处理上述经过归一化的人脸图像,以精确定位人脸的68个关键区域。这些关键区域被划分为内部关键点和轮廓关键点。通过定位人脸68个关键区域,内部关键点包括眉毛、眼睛、鼻子、嘴巴(51点),轮廓关键点包括17点,通过对这些关键点检测,我们能够准确捕捉人脸面部的关键特征,为进一步的分析和处理提供了有力支持。
使用OpenCV3.4中提供的Facial Landmark Detection人脸关键点检测API,提取面部68个关键点。提取到的关键点将有助于戴眼镜中面部区域被割裂现象的弥补,有效提高微表情Apex帧检测准确率。
3、面部区域二值化及最大连通域提取。
研究发现,眼镜对面部微表情识别有严重的负面影响。为了消除眼镜框在二值化后变为黑色使得脸部被分成两块区域,导致提取最大联通区域时丢失脸的上部分或下部分,提取面部关键点中的眼睛和鼻子在图像中的坐标,将其与面部肤色图像中坐标进行映射,给面部肤色图像中的这些位置坐标进行连线并赋予白色像素值。
2.3. 离散余弦变换背景建模
对最大连通域面部特征中提取到的轮廓内的图像进行分块背景建模,使用DCT进行背景建模,提取运动区域;最后在运动区域中使用加权方法,检测Apex帧,从而提取到人脸微表情发生的Apex帧。
1、块模型及初始化
通过视频首帧信息为每块x创建包含N个样本的背景样本集
,其中
为块x的8邻域内的 DCT直流分量
,
(4)
在首帧中,基于 [30] 的相似分布假设,每块通过DCT变换提取直流分量构建块模型,以8邻域块的DCT直流分量作为背景模型样本集,确保样本多样性。通过(5)式初始化背景模型。
代表x块的空间8邻域,通过(5)式来初始化背景模型。
(5)
2、运动物体检测
在欧式空间,计算背景块与块
相同位置的直流分量。通过欧氏距离和相似匹配阈值判断前景/背景,记录最大差异样本序号,更新样本集,具体来说就是使用以
为圆心、
为半径的圆,计算圆内与
相同值的样本数,比较#value与相似匹配阈值#min,根据结果归类。
(6)
通过实验证明,在灰度图像中,选择块大小为3 × 3,圆的半径R = 40,相似匹配阈值#min = 2,以及前景连续匹配块阈值threshnum = 3时,模型表现较好。详细参数讨论见第3.4节。
3、模型更新
从视频第二帧开始,视频背景模型更新分为:背景、前景区域更新,确保精准建模和平滑过渡。
A、背景区域更新
视频背景模型更新涉及背景区域和前景区域更新。背景区域更新采用最不相似样本替换策略,通过DCT直流分量值替换背景块样本集中最不相似的样本,确保平滑过渡。对邻域块采用与文献 [30] 相似的随机更新策略,生成随机数决定更新哪个块,再生成整数确定更新哪个样本,以块的DCT直流分量值替换该样本。
B、前景区域更新
对前景块x,fcount记录其前景次数。当fcount ≥ threshnum时,替换背景样本值;否则,不替换。具体公式如下:
(7)
前景区域判断是否替换背景样本,替换时使用块的DCT值替换第ind个样本,同时去除最不相似样本,fcount重置为0。实验证明threshnum = 3时检测准确率较高。
3. 实验与结果分析
3.1. 实验数据
实验中采用中国科学院心理研究所提供的微表情测试数据集CASME和CASME2 [31] 进行实验。
3.2. 深度学习的残差网络
本文选择深度残差网络(ResNet)作为人脸检测基础模型,通过引入残差单元和短路连接,继承VGG19的优势并在下采样时采用stride = 2卷积,保持高分辨率特征提取。使用全局平均池化替代全连接层,设计原则保持网络层复杂度。在微表情图像高分辨率的情况下,ResNet在人脸信息提取方面表现卓越,实验中取得显著成果。
3.3. 最大连通域的面部特征提取
如图3所示,当图像中的个体戴着眼镜时,基于RGB颜色的肤色检测时会将脸部分成两个比较大的连通域,在筛选连通域时会丢失一个次最大连通域,使得会失去部分微表情。本文使用关键点提取技术,提取出脸部的眼睛、鼻子、眉毛等坐标信息,将其坐标信息映射到肤色提取到的图像中,在映射后图像的关键点坐标内的像素值置为全白色,这样在对肤色进行二值化时能够有效消除眼镜框导致的面部图像断裂情况的发生,为后续进行准确的轮廓提取提供了基础。



 原始图像 肤色提取最大连通域 本文算法
原始图像 肤色提取最大连通域 本文算法
Figure 3. Connected domain extraction results
图3. 连通域提取结果
3.4. 背景建模
在背景建模中,跟踪问题可被视为一个二分类问题,即前景为运动物体和背景为非运动物体。本文采用PCC曲线对各类算法的分类性能进行评估。PCC的计算公式如下:
(8)
这四个参数(TP, FP, TN, FN)分别表示正确分类的前景像素点数、将背景错误分类为前景的数量、正确分类的背景像素点数以及将前景错误分类为背景的数量。
A、实验参数讨论
通过实验确定算法参数:圆半径R = 40,相似匹配阈值#min与文献 [30] 保持一致设为2,连续匹配块阈值threshnum设为3,块大小固定。在这样的设置下,实现了较好的跟踪效果,特别是当连续3次判定为前景块时,使用DCT后的直流分量值更新样本集,取得高分类正确率。图4展示了在不同连续匹配块阈值下的分类准确度。
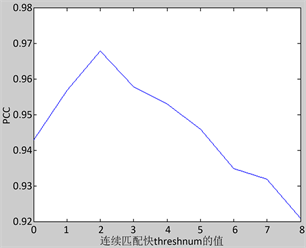
Figure 4. Classification accuracy under different consecutive matching block threshold
图4. 不同连续匹配块阈值下的分类精度
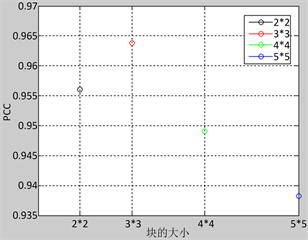
Figure 5. Classification accuracy under different block size
图5. 块的大小与分类正确率
通过实验统计块大小为
、
、
、
时的分类正确率,绘制PCC曲线。结果显示,在块太小
和太大(
、
)时,分类准确率较低。在这项工作中,块的大小选择是基于图5中显示的块大小与准确性之间的关联,选择
的块大小,因为在此配置下,兼顾了对光照变化的抵抗力,避免了将背景块错误分类为前景,实现了较高的分类准确率。
3.5. 结果对比
使用中国科学院心理研究所提供的微表情测试数据集CASME2和CASME使用本文提出的算法分别进行探测Apex帧实验,在CASME2中图像序列中发现Apex帧效果如图6所示;图中a为disgust (厌恶)微表情的Apex帧,b为fear (恐惧)微表情的Apex帧,c为happiness (快乐)微表情的Apex帧,d为repression (压抑)微表情的Apex帧,e为sadness (悲伤)微表情的Apex帧,f为surprise (惊讶)微表情的Apex帧。
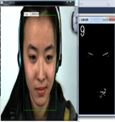
 (a) (b) (c)
(a) (b) (c)
Figure 6. Apex frame detection results on CASME II
图6. 在CASME II上的顶点帧检测结果
在CASME中图像序列中发现Apex帧效果如图7所示;图中a为tense (紧张)微表情的Apex帧,b为surprise (惊讶)微表情的Apex帧,c为disgust (厌恶)微表情的Apex帧。


 (a) (b) (c)
(a) (b) (c)
Figure 7. Apex frame detection results on CASME
图7. 顶点帧检测结果为CASME

Table 1. Experimental results of each peak detection algorithm on the microexpression datasets
表1. 各个峰值检测算法在微表情数据集上的实验结果
为了验证本文所提算法的效果,我们使用平均绝对值误差(MAE) [32] 和标准错误 [32] 来评估峰值检测的性能。现有的频率域微表情峰值检测的算法有:CLM [33] 、LBP [33] 、OS [34] 和RHOOF [35] 的比较见表1。
各算法对测试集中样本进行微表情提取所需的平均时间对比如表2所示。
Table 2. Average time consumed by each algorithm
表2. 各算法消耗的平均时间
将本文算法与频率域中检测Apex帧的Zhao等人 [25] 提出的CMED-3DFFT算法以及Li Y [28] 等人提出的DCNN算法进行比较,结果在表3。
Table 3. Experimental results of the frequency domain spike detection algorithm on the microexpression dataset
表3. 频率域峰值检测算法在微表情数据集上的实验结果
通过在不同微表情视频序列下,分别运行本文所提算法提取Apex帧与其他微表情提取算法的准确率进行比较,本文所提算法优于其他算法,如表4所示。
Table 4. Comparison of the average recognition accuracy
表4. 比较平均识别精度
4. 结束
本文在微表情研究中,提出了一种基于多特征融合及背景建模的微表情Apex帧检测,其主要特点是,通过对检测到人脸图像进行肤色提取和人脸中的眼睛、鼻子等关键点的提取后进行二值化,提取脸部区域的最大连通域,在最大连通域内进行背景建模,提取前景,通过统计前景区域中的面积最大值,得到微表情变化最大的Apex所在的帧。实验结果表明,本算法能够较好地检测出视频序列中微表情发生的Apex帧。本算法基于实验室理想条件下进行测试,然而,在实际应用中,人脸的表情容易受到光照变化、非正面头部姿势、遮挡等多种因素的影响。未来的研究方向将专注于在真实且复杂的环境中,研究如何更有效地进行微表情识别。