1. 引言
现代化是一个复杂的概念,它不仅仅指经济的发展和技术的进步,还包括政治、文化、社会等方面的变革。现代化的进程是一个长期的、漫长的过程,需要不断的投入和努力才能实现。在全球化的背景下,现代化已成为各国共同关注和追求的目标,以满足人民对更好生活和更高质量的服务的需求 [1] 。
中国式现代化是指在中国特色社会主义理论指导下,中国在现代化进程中所形成的一种独特模式,以经济建设为中心,全面推进现代化建设的过程 [2] 。中国式现代化的内涵包括经济现代化、政治现代化、文化现代化和社会现代化等方面。在经济领域,中国式现代化注重提高经济发展的质量和效益,在创新驱动、产业升级、绿色发展等方面加大力度,实现经济高质量发展。在政治领域,中国式现代化推动法治化进程,加强国家治理能力和公共服务水平,实现政治体系现代化。在文化领域,中国式现代化注重传承中华文化,加强文化软实力建设,推动文化创新与产业融合,提高文化产业的核心竞争力。在社会领域,中国式现代化注重提高人民群众的生活质量和幸福感,加强教育、医疗、社保等公共服务,实现城乡一体化发展,推进共同富裕 [3] 。
如何评估中国式现代化的进程,已成为学术研究和政策制定的重要问题。评估现代化进程需要考虑多个方面,如经济发展、社会进步、政治体制等。在经济方面,可以通过GDP、人均收入等指标来评估经济现代化的进程 [4] 。在社会方面,可以通过教育、医疗、社保等公共服务的覆盖率和质量来评估社会现代化的进程。在政治方面,可以通过政治体制的改革和民主化进程来评估政治现代化的进程。在文化方面,可以通过文化产业的发展和文化软实力的提升来评估文化现代化的进程 [5] 。
总之,中国式现代化是一种独特的、符合中国国情的现代化模式,它在全面推进现代化建设的过程中注重人口规模、全体人民共同富裕、物质文明和精神文明相协调、人与自然和谐共生、走和平发展道路等方面 [6] 。评估中国式现代化的进程需要考虑多个方面的指标和因素,需要不断的投入和努力才能实现。
本文先结合现代化的五个重要特征,建立了五个维度评价指标体系,然后对收集的2012~2020年我国31个省级行政区(不含港澳台地区)的面板数据采用熵权法分析了各地区现代化发展水平,并用Dagum基尼系数、Kernel密度估计分析了各地区间和地区内的空间差异。
本文的研究意义在于,通过对中国式现代化水平的测度和时空特征的分析,可以深入了解中国式现代化的实践状况和发展趋势,为中国式现代化建设提供理论和实践支持,同时也可以为国内外学者提供参考和借鉴。
2. 数据介绍
本文数据选自中国统计年鉴,截取了2012年至2020年的数据,包含31个省市的多项指标数据,本文将其进行归纳分类,如表1所示。其中属性一栏用来表示指标的正向和负向。

Table 1. Evaluation system of modernization level index
表1. 现代化水平指标评价体系
同时,为较好地刻画中国式现代化及其时空特征,本文将31个省市按东西走向划分为东部、中部及西部,如表2所示。
Table 2. Regional division table of 31 provinces and cities
表2. 31省市区域划分表
3. 基于全指标的测度分析
(一) 指标权重和各地得分排名
本文将全部指标通过熵权法进行计算权重,在表1中已将所有指标进行分类,因此每个类别的所有指标权重和为1,结果如表3所示。
其中,熵权法(Entropy Weight Method)是一种常用的多属性决策分析方法 [7] ,用于确定各个属性在决策中的权重。熵权法基于信息熵的概念,将多个指标的熵值作为权重因子,通过计算每个指标的信息熵和信息熵权重,来确定各个指标的权重。熵权法适用于多属性决策分析中,可以帮助决策者确定各个指标的权重,从而更加科学、客观地评价和选择决策方案 [8] 。与其他权重确定方法相比,熵权法不需要预先确定指标之间的关系,不受主观因素干扰,具有较高的可靠性和实用性。根据熵的特性,我们可以通过计算熵值来判断一个事件的随机性及无序程度,也可以用熵值来判断某个指标的离散程度,指标的离散程度越大,该指标对总体的影响越大。假设数据有n行记录,m个变量,数据可以用一个n∙m的矩阵表示(n行m列)。下面式子中,
;
。
1) 数据标准化
将各指标由绝对值变为相对值,同时消除量纲对结果的影响。
对于正向指标:
(1)
对于负向指标:
(2)
2) 确定各指标的信息熵
计算第j个指标下第i个样本占该指标的比重:
(3)
计算第j个指标的熵值:
(4)
3) 确定各指标的权重
(5)
Table 3. Result table of entropy weight method
表3. 熵权法结果表
由表3可知,在人口规模现代维度中,规模以上工业企业R&D人员全时当量指标权重最大;在全体人民共同富裕的现代化指标中,公共服务支出占地区生产总值比重指标权重最大;在物质文明和精神文明相协调的现代化维度中,技术市场成交额占地区生产总值比重指标权重最大;在生态文明现代化维度中,人均水资源量指标权重最大;在走和平发展道路的现代化维度中,国际旅游外汇收入指标权重最大。以上几大指标综合考虑了工业水平、社会保障程度、科技发展水平、人均生存资源及国际交流程度,较好地刻画了现代化发展的水平。同时,为考虑各维度的重要性,同样采取熵权法对各二级指标进行权重计算,结果如表4所示。
Table 4. Weight table of each dimension
表4. 各维度权重表
由表4可知,各个二级指标比较均衡地刻画了现代化水平,从侧面反映了本文对各指标的分类较为合适。接着我们通过对各个二级指标进行综合得分计算,可得各省市的综合得分情况,如表5所示。
Table 5. Comprehensive score table of provinces and cities
表5. 各省市综合得分表
由表5可知,广东省、西藏自治区、江苏省、浙江省、北京市、上海市、山东省、天津市及福建省等十个省市综合排名靠前,其中西藏自治区因为人均资源丰富,污染排放少,生态文明现代化那一项的得分远远高于其他地区,并且人口密度小,有国家政策帮扶,故在本文的现代化评价体系内其综合得分较高。
(二) 现代化空间发展的差异分析
根据表2的划分,对三大地带进行综合得分计算,结果如表6所示。
Table 6. Comprehensive score table of the three major zones
表6. 三大地带综合得分表
由表6可知,东部地带现代化程度最高,中西部地带综合现代化程度略低一些,且中西部地带现代化差异较小。
Kernel Density Estimation (KDE)是一种非参数密度估计方法 [9] ,用于估计随机变量的概率密度函数。它通过对数据进行核函数(Kernel Function)平滑处理来估计概率密度函数,从而避免了使用参数化概率分布模型的假设。KDE的基本思想是将每个观测值视为一个独立的概率密度函数,并通过对所有观测值的概率密度函数进行平均,来估计总体概率密度函数。具体地说,对于一个实数随机变量X,其概率密度函数可以表示为:
(6)
其中,n表示观测值的数量,xi表示第i个观测值,Kh表示核函数,h表示平滑参数(也称带宽或窗宽),用于调节核函数的宽度。核函数Kh必须满足一些条件,比如非负性、积分为1等,通常使用高斯核函数或Epanechnikov核函数等常见的核函。KDE的核心思想是通过将每个观测值的概率密度函数加权平均,来估计总体概率密度函数。权重的大小由核函数Kh决定,它决定了每个观测值对最终概率密度函数的贡献大小。当h较小时,核函数的宽度较窄,估计出的概率密度函数较精细,但容易受到噪声的影响;当h较大时,核函数的宽度较宽,估计出的概率密度函数较平滑,但可能会损失一些细节信息。
KDE的实现步骤通常包括以下几个步骤:
1) 选择核函数,通常使用高斯核函数或Epanechnikov核函数等常用的核函数;
2) 选择平滑参数h,通常使用交叉验证等方法来确定h的最优值;
3) 对于每个观测值,计算其对应的核函数值;
4) 对所有观测值的核函数值进行加权平均,得到最终的概率密度函数估计值。
通过对三大地带的二级指标进行核密度估计,如下所示。
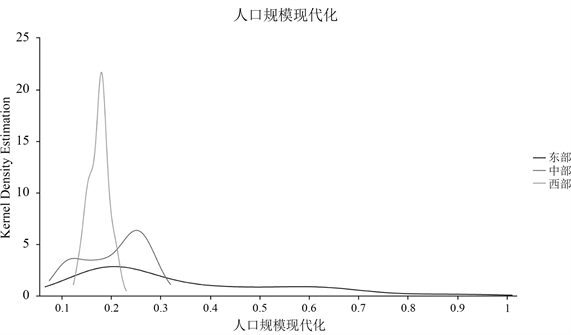
Figure 1. Kernel density curve of population scale modernization in the three major zones
图1. 三大地带人口规模现代化的核密度曲线
由图1可知,西部地带各省市的人口规模现代化差异较小,水平低,多集中在0.1~0.2之间,而东部地带人口规模现代化分布差异较大,如海南与北京之间的城镇化水平和高级科研人员等指标的较大差异导致此二级指标的得分差异较大。
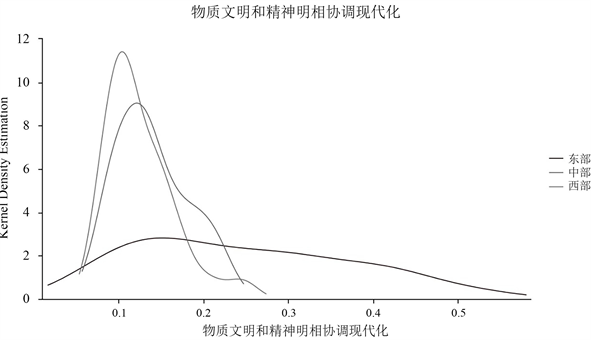
Figure 2. Kernel density curve of the coordinated modernization of material civilization and spiritual civilization in the three major zones
图2. 三大地带物质文明和精神文明相协调现代化的核密度曲线
由图2可知,中部地带和西部地带的物质文明和精神文明相协调现代化程度主要集中在0.1~0.3之间,地带内部差异较小,而东部地带内部各省市差异较大。
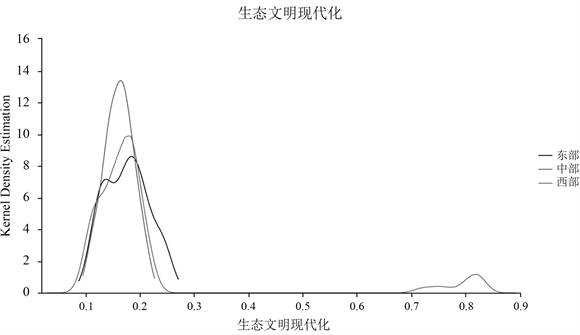
Figure 3. Kernel density curve of ecological civilization modernization in the three major zones
图3. 三大地带生态文明现代化的核密度曲线
由图3可知,各地带内部的生态文明现代化差异较小,且主要集中在0.1~0.3之间,具体地,近些年各省市均在“绿水青山就是金山银山”的倡导下进行绿色发展,故得分比较接近,其中西藏自治区的得分最高,且远远大于其他地区。
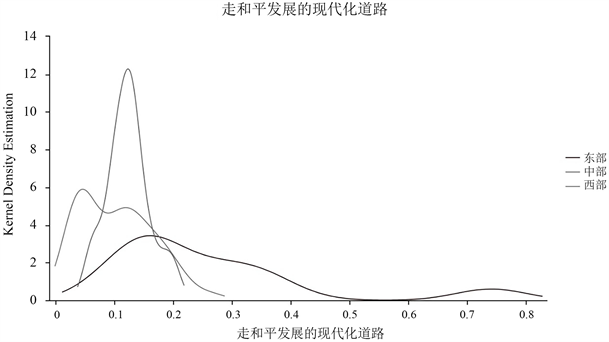
Figure 4. Kernel density curve of the modernization path of the three major zones taking away peaceful development
图4. 三大地带走和平发展的现代化道路的核密度曲线
由图4可知,在走和平发展的现代化道路指标中,东部地带差异较大。
由图5可知,在全体人民共同富裕的现代化指标中,各地带的内部差异均较显著,如东部地带的北京和海南、中部地带的湖南和山西、西部地带的四川和新疆等。

Figure 5. Kernel density curve of the common prosperity and modernization of all the people in the three major zones
图5. 三大地带全体人民共同富裕现代化的核密度曲线
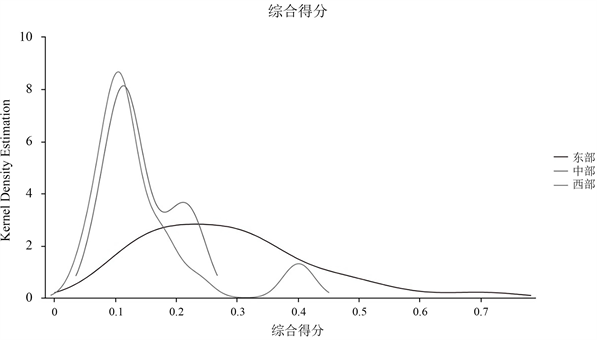
Figure 6. Kernel density curve of the comprehensive scores of the three major zones
图6. 三大地带综合得分的核密度曲线
由图6可知,中西部地带内部各省市的综合得分差异较小,而东部地带内部各省市的差异较大。
基尼分解(Gini Decomposition)是一种将总体不平等度量分解为各因素贡献的方法 [10] 。洛伦兹曲线描述了收入分配的累积分布情况,即横轴表示人口比例,纵轴表示收入比例 [11] 。而洛伦兹系数则反映了洛伦兹曲线与完全平等状态之间的差距,它等于曲线下方面积与对角线下方面积之差。定义一个变量y表示某种社会福利指标,如收入、财富或教育水平等。同时,我们假设有n个人,并且第i个人的收入为yi。那么,整个群体的洛伦兹系数可以表示为:
。其中,分子部分是所有两两个人之间收入差异的绝对值之和,分母部分是所有人收入之和的两倍。将总体的洛伦兹系数拆分为各因素贡献的和。假设有k个因素影响了收入分配,如教育、性别、种族等等。那么,我们可以将总体的洛伦兹系数表示为:
。其中,G0是完全平等状态下的洛伦兹系数,Gj是第i个因素对总体不平等的贡献,λi是第i个因素对总体不平等的弹性系数。
使用基尼系数(Gini Coefficient)来度量各因素对总体不平等的贡献度。基尼系数等于洛伦兹系数减去完全平等状态下的洛伦兹系数,即:
这个公式表示了第i个因素对总体不平等的贡献。如果gj > 0,则说明该因素导致了不平等的增加;如果gj < 0,则说明该因素导致了不平等的降低。
本文对三大地带进行计算基尼系数及贡献率,如表7所示。
Table 7. Decomposition and contribution rate of Dagum Gini coefficient in Chinese-style modernization level region
表7. 中国式现代化水平区域Dagum基尼系数分解和贡献率
从表7中可以明显看出,2012~2020年地区间差距贡献率远高于地区内部差距的贡献率。从表中的数据变化趋势来看,地区内部差距的贡献率呈现缓慢递增的趋势,由2012年的24.94%上升到2020年的28.94%;而地区间差距贡献率由2012年的59.87%逐渐下降到2018年的52.15%,然后在2019年之后大幅上升到2020年的55.11%,地区间差距贡献率整体呈现先下降后递增的趋势。超变密度贡献率在2012到2019年间整体呈现递增趋势,但在2020年又大幅下降到15.95%。可以得到我国现代化水平总体差异主要来源于地区间的差异。
4. 基于特征选择的测度分析
(一) 特征选择
当需要进行大规模数据分析时,可能会面临大量指标和特征的问题,这会导致计算成本高昂、模型过拟合以及模型性能下降等问题 [12] 。因此,进行特征选择和筛选是一个重要的预处理步骤,可以从原始数据中选择最相关的特征,提高模型的性能和可解释性。对于分析中国式现代化的指标,本文将按照以下步骤进行特征筛选:
1) 数据探索和预处理:首先,需要对数据进行探索和预处理,包括缺失值填补、异常值处理、数据标准化和归一化等。通过减少噪声和冗余信息,提高模型的鲁棒性和可靠性。
2) 特征重要性评估:然后,使用随机森林等算法计算每个指标的重要性得分,以确定哪些指标对于分析中国式现代化的影响最大。
3) 特征组合和交互:对于一些相关性较高的指标,可以考虑进行特征组合和交互,例如计算这些指标的平均值或比例值,或者构建新的指标作为特征。
4) 模型评估和调优:在进行特征筛选后,需要对模型进行评估和调优,以确定最佳的模型参数和特征组合。可以使用交叉验证和网格搜索等方法来选择最佳的模型参数,或者使用集成学习和深度学习等方法来进一步提高模型性能。
本文将采用随机森林进行特征选择。在分析模型之前,应先引入决策树,随机决策树是根据策略抉择而建立起来的树模型,其构建的目的就是寻找具有决定性作用的特征 [13] ,再根据特征重要性程度构建一棵树,以程度最大特征为树的结点,逐步递归找出各个分支下的子数据集中排名第二大的结点,以此类推,将所有数据循环划分到所属类中,从而筛选出特征重要性较大的前几项。
随机森林模型就是在决策树的基础上,在训练过程中添加随机属性,在基决策树上每个节点属性中随机选中包含n个属性的子集合,再从子集合中选最好的属性 [14] 。对于切分节点的好坏,一般采用子节点不纯度的加权和G(xi, vij)来表示:
(7)
其中,xi表示某一个切分点变量,vij为切分值,nleft、nright以及Ns分别表示切分点左右子节点训练样本合数以及当前节点所有训练样本个数,Xleft和Xright表示训练样本集合,H(X)表示不纯度函数。问题一采用随机森林的回归预测模型,因此H(X)一般采用均方误差来衡量,即:
,其中ym为当前节点样本目标函数的平均值,流程如图7所示。
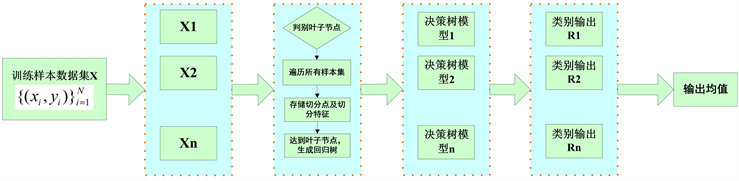
Figure 7. Random forest regression algorithm model
图7. 随机森林回归算法模型
(二) 指标权重
本文综合以上算法进行了各特征权重计算,显示了各指标对模型贡献的重要程度,其加和值为1,如表8所示。
Table 8. Weight table of each indicator after feature selection
表8. 特征选择后的各指标权重表
(三) 测度分析结果
本文将特征选择后的指标首先通过熵权法进行计算权重,结果如表9所示。同时,计算经特征选择后的各个维度即二级指标的权重,结果如表10所示。
Table 9. Weight table of four indexes after feature selection
表9. 基于特征选择后的四级指标权重表
由表9可知,规模以上工业企业R&D人员全时当量、公共服务支出占地区生产总值比重、技术市场成交额占地区生产总值比重、人均水资源量、接待国际游客等各个维度中权重第一的指标与未经特征选择的大概一致,说明本文通过特征选择有效地剔除了冗余特征。
Table 10. Weight table of secondary indicators after feature selection
表10. 基于特征选择后的二级指标权重表
由表10可知,与全指标相比,各个二级指标的权重占比差异更小,说明通过特征选择后更有效地选取了具有代表性的特征。结合各个二级指标对各省市进行计算综合得分,如表11所示。
Table 11. Comprehensive score table of provinces and cities after feature selection
表11. 基于特征选择后的各省市综合得分表
Table 12. Comprehensive score table of the three major zones after feature selection
表12. 特征选择后的三大地带综合得分表
由表11和表12可知,与全指标测度分析结论基本一致,其中广东省的现代化程度最高,东部地带的现代化程度综合最高。
5. 结论
综合上述,本文中广东省现代化程度最高,西藏自治区也比较靠前,主要因为人均资源较为丰富、国家政策帮扶等因素,而宁夏回族自治区现代化程度较低。而我国现代化水平总体差异主要来源于地区间的差异。在三大地带中,东部地带现代化程度最高,而中西部现代化程度近似。本文还考虑了指标过多是否会影响分析,因此结合随机森林等方法进行特征选择,基于选择后的特征再次进行分析,结果显示,与全指标测度分析结果基本一致,一方面说明了这些指标中确实存在冗余,另一方面也再次论证了本文测度分析结果的稳定性。