1. 引言
三维激光雷达点云目标检测是自动驾驶 [1] 、智能机器人以及智能交通等领域的一项关键技术,受到了国内外学者的普遍关注。不同于传统图像数据,三维点云数据具有直接空间信息,可以为实现三维场景理解和环境感知提供更加真实和全面的视角。然而,点云数据具有无序性、稀疏性、置换不变性等特殊性质,同时含有较多噪点,为在遮挡程度较高的环境中实现高效且准确的目标检测带来极大困难。
近年来,为了克服点云数据的缺点,国内外学者提出了多种不同的三维点云目标检测方法。Charles等 [2] 提出的PointNet算法直接逐点处理点云,完成特征学习,该方法能够保留点云的原始信息,但无法解决点云无序性和稀疏性带来的特征提取困难及计算效率低下问题;Zhou等 [3] 提出的VoxelNet算法将空间划分为体素,对每个体素应用PointNet,然后使用3D卷积中间层来巩固垂直轴,最后应用2D卷积检测体系结构,虽然这种方法在一定程度上克服了点云数据的不规则性,但由于体素化过程会导致模型推理时间延长,无法实时部署;Yan等 [4] 提出的SECOND算法有效提高了VoxelNet的推理速度,但其中的3D卷积运算成为影响算法实时性的瓶颈。为了提高目标检测算法的运行速度,Lang等 [5] 提出的PointPillars将点云数据划分为一系列垂直排列的支柱,然后通过2D卷积在支柱表示上进行特征提取,该方法可以更有效地处理大规模点云数据并保留重要信息,并且在速度和准确性之间取得了完美的平衡,但存在诸如小尺寸目标检测效果差、遮挡漏检等问题需要解决。
为了弥补经典PointPillars算法的缺点,本研究在经典PointPillars算法的基础上,在支柱特征网络中增加点云特征表示来丰富特征编码,以提高每个点的表征能力。随后,在伪图像上应用空间注意力机制来重新计算编码后空间点的特征权重,从而增强算法的特征提取能力,进一步提高目标检测性能。最后的实验结果表明,这一改进方法能够精确地检测小尺寸行人和骑行者目标,精确预测目标的朝向,同时在大尺寸汽车目标检测方面保持稳定的性能。
2. PointPillars算法原理
相较于其他三维目标检测算法,PointPillars算法采用点云立柱化的表征方式,将三维点云转化成二维伪图像,然后使用二维的Backbone进行特征提取 [6] ,模型主要包括三大模块:1) 支柱特征网络模块,完成点云到伪图像的转换;2) Backbone主干特征提取模块,使用二维卷积神经网络(2DCNN)提取不同支柱之间的空间和语义特征;3) SSD检测头模块,完成包围框的回归和目标的分类。具体的检测过程如下文所述。
图1所示为支柱特征网络模块结构图。首先,将X-Y平面上的输入激光雷达点云等间隔离散化,构成一组支柱(pillars);其次,通过支柱堆叠创建维度为(D, P, N)的密集张量,其中D表示点的特征维度数,P表示非空支柱的数量,N表示每个支柱包含点的个数;再次,使用PointNet [2] 简化版网络结构,对于柱中每个点,经过线性层,批归一化(BatchNorm)层和ReLU激活层,输出维度为(C, P, N )的张量;最后,对多通道特征图进行最大池化(MaxPool)创建维度为(C, P)的输出张量,并通过编码将它们分散回原始支柱位置,获得维度为(C, H, W)的伪图像,其中C表示伪图像通道数,H和W表示伪图像的高度和宽度。

Figure 1. Pillar feature network structure diagram
图1. 支柱特征网络结构图
图2所示为Backbone主干特征提取模块结构图。该模块包含下采样和上采样两个子网络,下采样网络由三个自上而下的卷积核为3 × 3的二维卷积(Conv)模块组成,三个模块层数依次为4,6,6,输出特征维度分别为64,128,256,在每层卷积之后均依次经过BatchNorm层和ReLU激活层;上采样网络由三个二维反卷积(Deconv)模块组成,用于将三个下采样块输出的不同维度特征上采样为128维特征,特征经过BatchNorm层和ReLU激活层后通过特征拼接Concat模块连接在一起,最终输出384维特征。
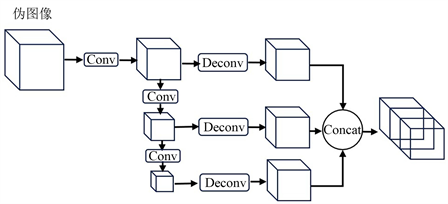
Figure 2. Backbone feature extraction network structure diagram
图2. 主干特征提取网络结构图
三维点云经支柱特征网络和主干特征提取网络,顺利完成目标特征提取。将提取的特征图输入SSD [7] 检测头模块,进行包围框(bounding box)回归和目标分类,得到物体的位置和种类 [6] 。
3. PointPillars算法改进
在传统PointPillars算法中,点云支柱特征编码部分容易导致特征丢失,同时主干特征提取网络对伪图像的特征提取不够充分,因此存在目标检测精度低的问题。为了提高检测性能,在原支柱特征网络部分添加点云编码特征,对特征编码进行丰富;此外,在主干特征提取之前添加空间注意力机制(Spatial Attention, SAt),对伪图像空间点细微特征进行提取。
改进后网络结构如图3所示。其中Backbone主干特征提取保持原始PointPillars中的结构,检测头部分使用二维卷积网络训练汽车、行人、骑行者三个类别,先验框与真实框匹配过程不考虑高度信息,使用2D (IoU) [8] 匹配方式。
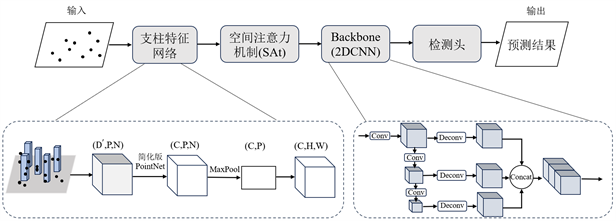
Figure 3. Improved network structure diagram
图3. 改进后网络结构图
3.1. 支柱特征网络
原PointPillars模型在通过支柱特征网络模块对点云进行编码时,每个支柱中激光雷达点s维度数D = 9,点s编码如式(1)所示:
(1)
式中,[x, y, z]是激光雷达坐标系中点的空间坐标,r是反射强度,[xc, yc, zc]表示点s的[x, y, z]到当前支柱中所有点空间坐标的算术平均值的距离,[xp, yp]表示点s的(x, y)距当前支柱中心(x, y)的偏移量。
可以看出,原PointPillars算法仅考虑了点的空间坐标与支柱中所有点的空间坐标均值的偏差,没有考虑点的反射率强度偏差特征。在某些场景中,目标可能与背景具有相似的几何特征,但反射率强度特征有明显差异,通过分析反射率强度偏差,可以更准确地将目标与周围环境分离开来。其次,在光照条件变化或目标具有复杂反射特性的情况下,有效地捕获每个点的相对亮度或暗度信息,可以更好地区分不同表面特性的目标。因此,在点云特征表示方面,在点s上增加当前点的反射率到支柱中所有点反射率均值的偏差特征 ,使特征维度数D' = 10,增强后的特征编码如式(2)所示:
(2)
3.2. 注意力模块
注意力模块的主要功能是通过添加注意力机制来增加数据的表征能力,使网络学习特征中的重要信息并抑制不重要信息 [9] ,常见的有通道注意力机制SE [10] 、ECA [11] ,空间注意力机制FPN [12] 、PAN [13] 、混合注意力机制CBAM [14] 等 [15] 。为了使模型动态地学习点云数据的空间关联性,使模型可以更好地理解支柱编码生成的伪图像中不同点之间的相对位置和分布,受注意力机制CBAM的启发,在支柱特征网络生成的伪图像上使用如图4所示的空间注意力机制(SAt),更准确地捕获不同目标的几何形状和空间特征。空间注意力模块如式(3)所示:
(3)
式中,FSAt为SAt的输出数据,F为输入数据,[·; ·]表示沿通道维度的拼接操作,MaxPool(F)和AvgPool(F)分别表示通道维度的最大池化和平均池化;f3 × 3是3 × 3卷积,其输入和输出通道数分别为2和1。最大池化和平均池化操作在特征提取方面呈现出多尺度的特性,能够捕获不同尺度下的特征信息差异,通过将最大池化和平均池化的结果进行拼接并应用3 × 3卷积,模型可以同时考虑不同尺度的特征信息,在汽车、行人和骑行者等不同目标的检测方面,这种多尺度信息整合有助于提高模型不同尺度尤其是小尺度目标的检测性能。σ表示sigmoid激活函数,用于对注意力权重进行归一化,确保每个点的注意力权重在0到1之间,让模型可以对每个点进行不同程度的关注,将更多的注意力集中在可能包含目标的区域,从而提高检测效率。
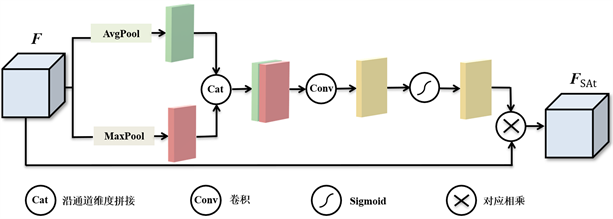
Figure 4. Spatial attention mechanism SAt structure
图4. 空间注意力机制SAt结构图

Figure 5. Plot of weights for different samples
图5. 不同样本权值图
该注意力机制可以以较低的模型复杂度学习特征图中每一个空间点的权重,通过权重的计算和特征的更新,增强对点云数据空间关系的建模能力,提高模型性能。图5所示为使用改进PointPillars网络模型对数据集中不同环境下的不同测试样本引入SAt的可视化验证。图像亮度对应利用Sigmoid函数对注意力权重进行归一化后,获得的0到1之间的权重值。
从图5可以看出:含有目标的区域点权重值较高,不含目标的区域点权重值相对较低,意味着SAt有效起到了特征筛选作用。
4. 实验与结果分析
使用官方KITTI [16] 数据集进行实验,实验环境为Linux操作系统,Python3.7,Pytorch1.10,Cuda11.1,主机配置有Intel(R) Silver 4210R CPU,GPU为NVIDIA RTX A5000,显存为24 G。本小节详细介绍KITTI数据集、网络参数设置、损失函数以及结果分析。
4.1. KITTI数据集
官方KITTI数据集根据目标遮挡程度、目标大小、点云噪声、天气状况等条件将目标检测分为简单、中等、困难三个级别,数据集中训练样本、测试样本总个数分别为7481、7518。本文在激光雷达点云上进行训练,在实验过程中,使用3712个训练样本和3769个验证样本 [9] ,同时为了增强点云数据多样性,采取随机镜像翻转、全局旋转和缩放等点云增强操作。
4.2. 网络参数设置
网络在训练过程中,使用的所有权重都是均匀分布且随机初始化。支柱特征网络中支柱长宽为0.16 m、高度为4 m,每个支柱最多包含32个点,训练阶段可以使用的最大体素数16,000,测试阶段可以使用的最大体素数40,000。优化器采用Adam、权重衰减系数为0.01,动量值为0.9,初始学习率为0.003,学习率衰减值为0.1,最大迭代次数为90。
4.3. 损失函数
使用PointPillars中引入的损失函数,定位损失使用SmoothL1损失;为了区分目标方向,减小目标朝向反向误差,在离散方向上使用SECOND网络中的Softmax分类损失;目标类别分类损失使用Focal Loss损失。
4.4. 结果分析
4.4.1. 实验定量分析
使用平均精度(AP)指标在KITTI数据集三个级别难易程度上对改进算法和原有PointPillars、VoxelNet、Second等算法的目标检测性能进行评估与对比分析。汽车的IOU阈值为0.7,行人以及骑行者的IOU阈值为0.5。

Table 1. KITTI dataset 3D model evaluation results
表1. KITTI数据集三维模式评估果
Table 2. KITTI dataset BEVmodel evaluation results
表2. KITTI数据集鸟瞰图模式评估结果
Table 3. KITTI dataset AOS model evaluation results
表3. KITTI数据集AOS模式评估结果
表1~表3分别表示KITTI数据集三维模式、鸟瞰图(BEV)模式以及平均方向相似度(AOS)模式的评估与对比结果。其中,mAP为在中等难度条件下,对三个类的平均精度(AP)进行平均计算得到。
4.4.2. 实验定性分析
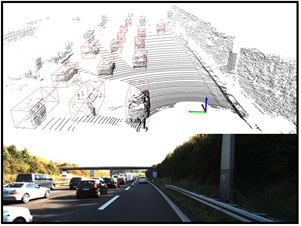
改进后的PointPillars算法在KITTI数据集的部分检测结果如图6所示。图中上半部分为在点云场景中的三维检测效果图,下半部分为对应的相机中的真实场景图。检测结果用不同颜色的框表示不同的类别,红色框代表汽车、蓝色框代表行人、绿色框代表骑行者,目标朝向由三维框的交叉线表示,含有交叉线的方向为目标的前向。
 (a)
(a) 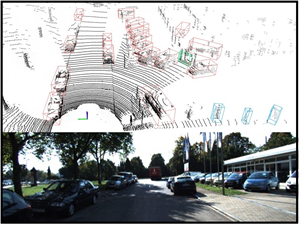 (b)
(b)
Figure 6. A classic example of spatial data sets
图6. 空间数据集经典例子
可以看出:对于远距离场景图6(a)以及较为复杂的场景图6(b),改进算法依然可以实现较准确的检测;从目标的朝向角度分析,本文算法能准确预测出目标朝向。
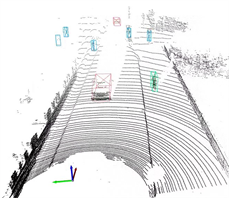
此外,改进算法还可以较好的减小误检率,如图7所示,图7(a)为原始PointPillars算法的检测结果,图7(b)为本文算法的检测结果,图7(c)为对应的相机中的真实场景图。改进算法没有将相机图像中紫色标注框的电线杆误检成行人。
 (a)
(a)  (b)
(b)  (c)
(c)
Figure 7. Comparison of detection results between this algorithm and the original PointPillars algorithm
图7. 本文算法与原PointPillars算法检测结果对比
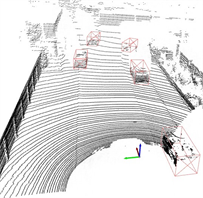
最后,改进算法可以较好的减小漏检率,如图8所示,漏检车辆用紫色边框标出,图8(a)为原始PointPillars算法的检测结果,图8(b)为本文算法的检测结果,图8(c)为对应的相机中的真实场景图。改进算法可以检测出被前方车辆遮挡相机图像中紫色标注框的后方车辆。
 (a)
(a) 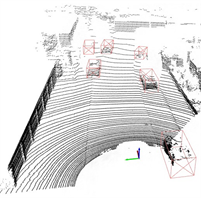 (b)
(b)  (c)
(c)
Figure 8. Comparison of detection results between this algorithm and the original PointPillars algorithm
图8. 本文算法与原PointPillars算法检测结果对比
5. 结论
提出一种基于经典PointPillars三维激光雷达目标检测改进算法,解决了小尺度目标检测效果差的难题。通过添加当前点的反射率与当前支柱所有点反射率均值的偏差特征,增强点的表征能力,通过引入空间注意力机制,提高算法对伪图像的特征提取能力,提高算法的目标检测性能。在KITTI数据集上的实验结果表明:改进算法相较于原始算法在三种模式下的检测精度都有所提高,对于目标朝向角度误差,在小目标骑行者类别上精度提高效果尤其显著;在保证精度的同时,本文算法也能够有效降低目标误检以及目标被部分遮挡造成的漏检概率。
参考文献