1. 引言
推荐系统正在为各类用户提供个性化的服务,在电子商务、新闻网站、内容共享平台和社交媒体等广泛的在线应用中发挥着越来越重要的作用,然而,由于流行度偏差的存在,当前多数推荐系统更倾向于向用户推荐流行的项目,这与个性化推荐是背道而驰的。研究表明,流行偏见会导致推荐中的某些问题,例如随着时间的推移,用户的消费转向更主流的项目,甚至导致不同用户群体的同质化 [1] 。流行度偏差的出现是由长尾效应导致的,在互动的数据中,受到商品曝光机制、商品质量等因素的影响,多数情况下,频率的分布是不均匀的,整体呈现长尾分布,即少数项目占据了多数的交互,这就导致了推荐模型更偏向于推荐流行的项目。并不是所有的用户都喜欢流行的项目,流行度偏差的存在不仅会阻碍推荐者准确的理解用户偏好,同时也会导致推荐多样性的降低。马太效应 [2] 就是由流行度偏差所导致的,越受欢迎的物品就越被更多的推荐,变得更加受欢迎。为了缓解流行度偏差,研究人员已经探索了许多的方法,这些方法主要进行的工作就是进行无偏见的学习和排名调整。例如,反向倾向评分(IPS),它重新加权了模型训练的交互,以此来调整数据的分布 [3] ,虽然IPS方法的理论基础已经很成熟了,但是因为它的模型方差和倾向性很难进行估计,在实践中难以实现。排名调整是在得到推荐列表以后进行二次排名 [4] ,这种方法有意提高不太受欢迎的项目的分数,缺乏理论基础。消除流行偏见的关键并不是盲目的将推荐者推到长尾,而是仔细了解物品流行如何影响每次互动 [5] 。近几年,因果推断作为一个新颖的视角被引入到推荐系统中,从用户–项目交互、用户一致性和项目流行度出发,细粒度地分析并缓解流行度偏差,但是当前利用因果推断进行推荐仍然属于初步的尝试,并没有结合辅助信息。本文在此基础上对因果推理图以及遵循该因果图推理的反事实推理框架做了改进,因为在以往的因果推断过程中并没有考虑时间因素,这会影响用户–项目交互过程,从而影响最终用户对项目的评分,将时间因子纳入到因果推理图中,进而得到改进的反事实推理框架,通过实验证明,该框架缓解流行度偏差的效果相较于原框架有了一定的提升。
2. 无关模型的反事实推理框架
2.1. 因果推断和反事实推理关键概念介绍
因果推理源于统计学,它是统计学的重要研究课题,几十年来在公共政策、经济、计算机科学等许多领域得到了十分广泛的应用 [6] 。因果推断就是指根据已有的证据或者事实,推断出某种原因导致某种结果的推理过程。反事实推理是因果推断的一种方法,它是通过未发生的条件来推理可能的结果。在推荐系统中引入因果推断是必要的,传统的推荐算法的基础就是从数据中挖掘或学习相关模式,但是现实世界的应用是由潜在的因果机制驱动的,单纯的关联学习而不考虑因果关系会导致一些实际的问题 [7] ,比如就用经典的“啤酒和尿布”举例,这个事例的潜在机制是年轻的父亲通常会同时购买啤酒和尿布,如果只是从相关性出发为购买纸尿裤的顾客推荐啤酒,这回直接造成推荐的混乱,损害用户的购买体验。所以,从关联学习迈向因果学习非常有必要。
因果图是一个有向无环图,在因果图中大写字母表示一个变量,而它对应的小写字母表示这个变量的观测值。边表示祖先节点是原因,而后继节点是结果。如图1所示,
表示存在I到S的直接影响。另外,路径
意味着I通过中介M影响S。根据因果图,S的值可以由它的祖先节点的值计算得出,表达式为:
(1)
因果总效应。I对S的因果效应是目标变量S因祖先变量I的变化而发生变化的幅度,当
时,总效应定义为:
(2)
公式(2)表示
和
这两种假设情况下S值之间的差异,
通常是指I的值与实际值不一致的情况,这个值通常设置为空。根据图1的因果图,TE可以分解成自然直接效应(Natural Direct Effect,NDE)和间接效应(Total Indirect Effect, TIE),分别通过直接路径
和间接路径
表示对评分S的影响。NDE表示在直接路径
上,随着值从i*变到I,S值的改变,表达式为:
(3)
就是一个反事实推理,因为它需要相同变量的值i在不同路径设置不同的值,间接效应可以直接通过总效应减去直接因果效应,表达式为:
(4)
2.2. 推荐系统中的因果图分析
流行性偏见是推荐系统中一个长期存在的挑战:流行的项目被过度推荐,而用户可能感兴趣的不太流行的项目却被推荐不足。这种偏见对用户和商品提供商都产生了不利影响,许多人都致力于研究和解决这种偏见 [8] 。利用因果关系探讨流行度偏见,如图2所示的因果图描述了推荐过程中的重要因果关系,这与历史互动的生成过程相对应,其中U表示用户,I表示项目,M表示用户和项目的特征匹配,S表示排名分数或交互概率。当前交互可能性的主要有三个因素,分别是用户–项目匹配、用户一致性和项目的受欢迎程度。现有的推荐模型主要关注的是用户–项目匹配因素,事实上,另外两个因素对用最终的交互概率也有十分重要的影响。假设同一个用户对于两个商品拥有相同的匹配度,那么流行度更高的商品更有可能被推荐给用户并进行购买,这就是从节点U到节点S边的含义;另外,不同用户受到商品的受欢迎程度的影响也会有所不同,有些用户更倾向于购买流行度高的商品,有些用户则更喜欢一些比较冷门的商品,这是从节点I到节点S的含义。

Figure 2. Recommendation system causal inference diagram
图2. 推荐系统因果推断图
2.3. 模型不可知的反事实推理框架
从因果关系的角度来看,项目的流行程度会直接影响最终的推荐得分,所以消除了从物品流行程度到推荐得分的直接影响就可以消除流行度偏差,所以首先需要在训练时建模因果图中的因果效应。反事实推理框架的三个模块分别建模因果图
,
和
的因果路径对推荐的影响,并执行多任务学习来进行模型训练。既然是模型不可知的,所以该框架与模型无关,可以实现在现有的协同过滤推荐系统之上,只需要添加用户和物品模块到框架中,这些模块就会将用户和项目融入到推荐分数中。
3. 改进后的无关模型反事实推理框架
3.1. 时间因子
目前的推荐算法能够引入的计算因子主要包括用户社会关系、用户信誉度以及时间因子等 [5] 。用户在使用系统的过程中,他每次行为的时间往往会被准确的记录下来,推荐算法的首要目的就是要找出目标用户当前最有可能感兴趣的项目,目标用户最近的行为数据才是最具有价值的数据 [9] [10] ,引入时间因子的合理之处就在于它可以更好的划分不同数据的价值,拥有了时间因子的参与,用户和项目的匹配度可以更加精准,可以进一步帮助消除流行度偏差。用户u对项目i评分的时间权重可以定义为:
(5)
Tf表示用户首次进行项目评价的时间,Ti表示用户对项目i评分时对应的时间,Lu表示用户u使用推荐系统的总时长,同时利用艾宾浩斯遗忘规律进一步改进,每一个不同时间点的评分项都有一个不同的时间权重,距离当前时间越近的评分时间权重越大。
3.2. 融合时间因子的因果图
将时间因子融入到因果图中,用户–项目–时间共同决定了用户和项目的匹配程度,时间因子的加入使得用户和项目的匹配更加细粒度化,通过模型训练可以进一步消除流行度偏差
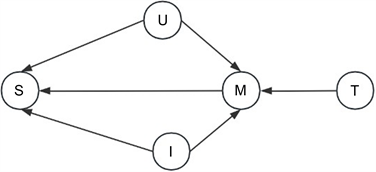
Figure 3. Causal inference graph integrating time factors
图3. 融合时间因子的因果推断图
3.3. 改进的反事实推理框架
图4所示为改进的反事实推理框架,它的实现遵循图3的因果图,一共分为了三个模块,分别是用户–项目–时间段匹配模块、项目模块以及用户模块。在用户–项目–时间段匹配模块中,匹配分数可以表示为
,它反映了在某一段时间内,用户和项目的匹配程度;项目模块得分可以表示为
,反映了在某一段时间内,项目受欢迎程度的影响,受欢迎程度越高的项目得分越高;用户模块的分可以表示为
,反映了在某一段时间内,用户u和项目交互的程度。由于考虑到随机向两个用户推荐同一个项目,其中一个用户可能会因为从众性更强或者偏好更广而点击这个项目,这类用户更容易收到项目流行度的影响,因而评分也会更高。将这三个分支汇总为最终预测分数如下所示:
(5)
公式中
是一个s型的函数,它的作用就是依赖用户–项目的匹配程度来恢复历史的交互记录。
本论文以BCE损失函数来监督和恢复历史交互,如下所示:
LO,LU,LI均为推荐损失,最终的训练损失函数为:
(6)
消除人气偏差的关键就是通过路径
从排名分数中将直接影响剔除,其中
是超参数,表示的是直接因果效应,TW表示时间因子。公式如下:
(7)
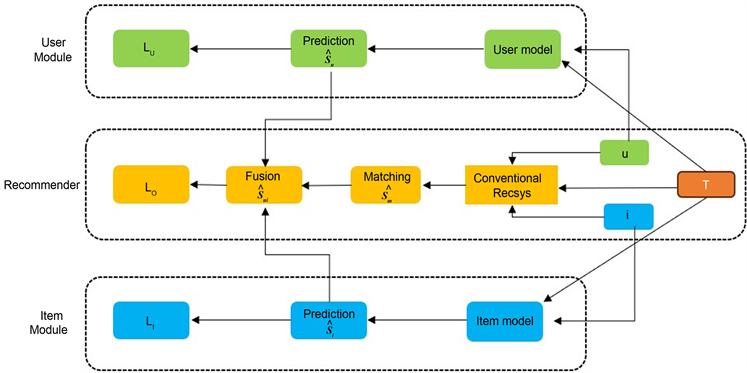
Figure 4. Improved counterfactual reasoning framework
图4. 改进的反事实推理框架
4. 实验结果分析
4.1. 评价指标
命中率(Hit Ratio,简称命中率):命中率强调的是模型推荐的准确性,即用户感兴趣的项目是否包含在模型的推荐项中,可以表示为:
S为样本的数目,可以理解为用户的需求项的数目。Hit(i)用于表述第i项需求项是否包含在模型推荐的项目列表中。若在,则其值为1;否则为0.
归一化折损累计增益(Normailzed Discounted Cumulative Gain,简称NDCG):NDCG强调的是用户的需求项在模型推荐列表中的位置,越靠前越佳,可以表示为:
S为样本的数目,可以理解为用户的需求项的数目。P(i)为第i项需求项在模型推荐的项目列表中的位置。若第i个需求项不在推荐列表中,则
为0。
召回率(Recall,简称Rec):召回率是推荐系统在召回阶段常用的评价指标。在其他的领域也经常会看到Recall作为评价指标,其含义为正样本中由多少预测为真。在推荐系统中,Recall可以表示为:
其中u为用户,R(u)为模型预测出的需要推荐的item的集合,T(u)表示真是的测试集中被推荐的集合。对每一个用户求得recall后求平均就可以得到整个数据集上的recall。
4.2. 实验结果比较
本实验使用MovieLens 10M数据集作为实验数据集,使用经典的MF算法来实现改进以后的反事实推理框架TMACR,已探索TMACR框架如何提高推荐的性能。实验将本论文的方法和MF推荐算法以及MACR_MF算法两个基线进行比较,利用命中率、归一化折损累计增益、召回率来作为实验的评价指标。它们的比较结果分别如图5,图6,图7所示,,MF算法均低于MACR_MF和TMACR_MF,说明反事实推理框架可以帮助矩阵分解算法缓解流行度偏差,同时本论文提出的改进的反事实推理框架TMACR缓解流行度偏差的效果要好于原框架,证明了本论文方法的有效性。
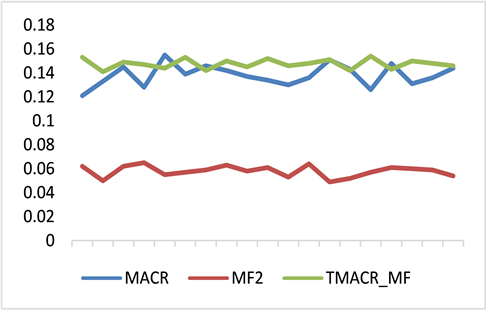
Figure 5. Comparison of hit rates of different algorithms
图5. 不同算法的命中率对比
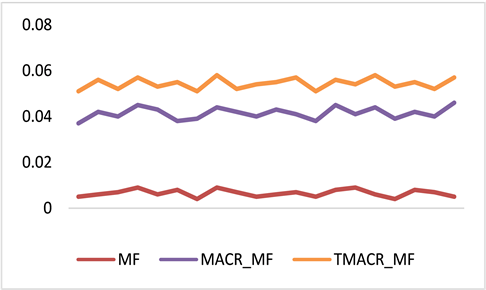
Figure 6. Comparison of normalized loss cumulative gain of different algorithms
图6. 不同算法的归一化折损累计增益对比
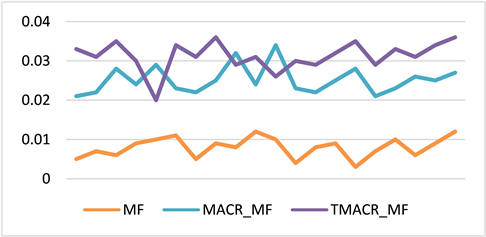
Figure 7. Comparison of recall rates of different algorithms
图7. 不同算法的召回率对比
5. 结束语
本文提出的改进的反事实推理框架由于融入了时间因子,这使得框架更偏向于通过用户最近的行为来进行推荐,针对项目流行度和用户一致性也将时间因素考虑在内,通过反事实推理消除了项目流行度和用户一致性对与用户项目交互的影响,所以在消除流行度偏差的效果相较于原框架有所提升。
参考文献