1. 引言
世界上每时每刻都充斥着大量的信息,这些信息包括了客观存在并且以人类的时间尺度来看是静止不变的,比如地球围绕着太阳旋转,天空是蓝色的等等。还包括了随着人类的进化和创造而后来产生的新信息,比如中国位于亚洲、拜登担任美国总统、甚至可以是小明和小红是好朋友这种非常贴近生活的琐碎信息。在计算机领域,信息的存储与结构组织是一个重要的领域,对于如何组织并管理真实世界里如此庞大数量的信息,知识图谱作为一种解决方案出现了。传统知识图谱(Knowledge Graph)以三元组的形式存储大量的结构化事实信息,每个三元组(es, r, eo)由头实体es、尾实体eo、关系r三部分组成,用来表示现实世界中的物体或抽象概念之间的联系 [1] 。
传统知识图谱仅能表示静态不由随时间改变的信息,比如(太阳,位于,银河系),但是现实世界中大部分的信息是受到时间因素影响的,比如(美国,是总统,特朗普)这个信息只在2017年到2021年之间成立,而在这个时间段之前或之后的时间上,这个信息显然是错误的。时序知识图谱通过增加时间信息,将三元组扩充到四元组的方式解决了这个问题,使得信息随着时间可以进行变化,以达到更加接近真实世界信息的目的。依赖于时序知识图谱这种结构化的数据,很多下游应用得以发展,比如推荐系统、问答系统等等,但这不是本文的主要内容因此不再赘述。时序知识图存在大量的数据,但因为其大多都由人工、半自动方式创建和组织,通常存在着严重的数据不完备、数据稀疏的问题,很难对其进行直接使用,在这种情况下,对知识图谱的补全显得非常重要。目前知识图谱补全的主流方式为实体关系进行低维嵌入后进行评分,得分越高补全后的三元组为真实事实的可能性越大。
2. 相关工作
因为知识图谱的完备性通常得不到保证,大量三元组中的实体或关系存在缺失或者不正确的情况,因此许多研究者对知识图谱的补全工作展开了广泛的探索,产生了众多思路不同优缺点各异的解决方案。根据知识图谱是否包含时间信息,可以分为不包含时间信息的静态知识图谱补全研究和包含时间信息的时序知识图谱补全研究。
2.1. 静态知识图谱补全研究
BordersA等人 [2] 提出的第一个平移距离模型TransE,以及为了改善弥补TransE模型的缺陷或以TransE的思想继续研究发展产生的TransH [3] 、TransG [4] 、RotatE [5] 等模型,都是基于静态知识图谱的模型,并不涉及时间信息的考虑。TransE模型将知识图谱中的关系看作头实体到尾实体在二维平面空间上的平移变换,非常清晰简单,效率很高,但是无法处理复杂关系,建模的准确性也不高。TransH引入了关系向量的投影,将关系向量投影到一个超平面上,在一定程度上改善了对称性关系的建模效果,还引入了交叉损失函数进一步提升模型性能。但对复杂关系的处理还是有所不足。TransG为了解决关系和多种语义的表达问题,提出了利用贝叶斯非参数混合模型对一个关系生成多种表示。RotatE把挂安息定义为复空间中头实体到尾实体的旋转变换,并通过引入的自对抗的负采样方式让错误样本更加明显。
2.2. 时序知识图谱补全研究
随着对知识图谱领域的关注度越来越高,以知识图谱为数据分析来源的下游应用的不断发展,研究者们对时序知识图谱的关注度也开始提升,时间信息也开始被考虑被加入到知识图补全技术的范畴当中。时序知识图谱补全技术可以分为基于静态模型拓展的补全技术和基于序列学习的补全技术。时序知识图补全技术可以通过参照知识图谱补全技术来构建模型,比如Sadeghian [6] 等人受到RotatE启发提出了ChronoR模型,通过学习关系和时间参数化的K维度旋转变换,使每个事实的头部实体通过旋转变换后可以落在尾部实体附近。Zixuan Li [7] 等人提出了RE-GCN模型,通过对知识图谱序列进行循环建模来学习每个时间戳的实体和关系的演化表示。并将实体的静态属性通过静态图谱约束组件纳入考虑,以获得更好的实体表示。针对在同一个时间阶段内有多个事件同时发生,产生多个存在一些紧密结构依赖的信息,很难提取局部实体的差异结构信息的问题,提出了基于序列学习的时序知识图谱补全方法。Luyi Bai [8] 等人提出的TPmod模型整合实体和关系的特征,预测时序知识图谱的缺失事件,并基于注意力机制的启发提出了一种新的趋势策略来指导聚合过程。
3. ConvE模型
ConvE [9] 是使用二维卷积在嵌入上预测知识图中缺失链接的模型,组成部分包括一个卷积层、一个到嵌入维数的投影层和一个内积层。ConvE的参数数量少,并且通过1-N评分的方式加速训练。在ConvE模型中,实体和关系嵌入首先被重塑和连接(步骤1、2),然后将得到的矩阵用作卷积层的输入(步骤3),得到的特征映射张量被矢量化并投射到k维空间(步骤4),并与所有候选对象嵌入(步骤5)匹配。以
表示头实体,
表示尾实体,ConvE的评分函数的定义如下:
(1)
其中,
是一个依赖于关系r的关系参数,
,
代表
,
的二维reshape,相应的,如果
,那么
,此时
。*表示卷积操作。
模型连接
,使其作为二维卷积层的输入,卷积层的滤波器为
,这一层会返回一个特征图张量
,这个c表示维度为m和n的2D特征图的数量。这个张量随后被reshape成一个向量
。然后该向量通过矩阵
参数化的线性变换将其投影到k维空间中,并通过内积匹配对象嵌入
。
为了训练模型参数,使用sigmod函数
来打分,即
,并使用以下二元交叉熵损失来最小化以训练模型:
(2)
4. Conv-ATG模型
4.1. 时间信息表示
大多数的链接预测方法都会将三元组中的实体和关系类型嵌入之后再进行操作。由于时间信息的稀疏性和不规则性,学习带有时间信息的表示是很有挑战性的。在本文中,将时间信息转换为表述时间信息的序列,具体思路为通过神经网络来学习时间感知表示,该神经网络使用表示时间谓词和时间戳数字的序列,神经网络的最后隐藏状态与标准评分函数相结合。
时间信息有很多种表示方式,比如之前、之后这种文字描述,比如2023年9月1日到2023年9月30日这种时间区间,也可以将时间的表示精度进行调整。描述时间信息具有多种方式,且现实世界中的信息包含的时间信息也各式各样,不能用一种唯一的标准去规范时间信息。这为时间信息表示的任务增加了难度。目前时间嵌入主流方式是利用循环神经网络LSTM或相似的模型学习可能包含时间谓词和时间戳数字的序列,将事件信息融合到实体或者关系的表示向量中,再用已有的模型评估带有时间信息三元组的真实程度,最终达到完成时序知识图补全的任务的效果。
Alberto García-Durán [10] 等人提出了利用LSTM (longshort-termmemory)长短期记忆网络来学习关系类型的时间感知表征,学习到的时间感知表征可以与现有的潜在因式分解方法结合使用。具体来说其将关系和时间戳的特征,也就是年月日等时间信息构成一个关系序列,通过一个线性映射函数,将关系和时间戳特征映射为相同维度的向量。最后把该序列向量输入神经网络进行编码,学习到融合了时间信息的关系表示向量。以图1为例,可以将年月日时间信息分解成时间标记组成的序列。
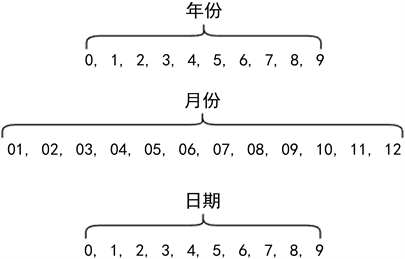
Figure 1. Schematic diagram of time information decomposition
图1. 时间信息分解示意图
在图2中,关系“出生于”和时间信息“1999年”经过LSTM模型的处理之后,形成了融合了时间信息的关系表示向量rresp,下一步就是使用该融合了时间信息的关系表示向量与头尾实体进行其他嵌入模型的分数评估,判断该包含时间的信息的真实程度。
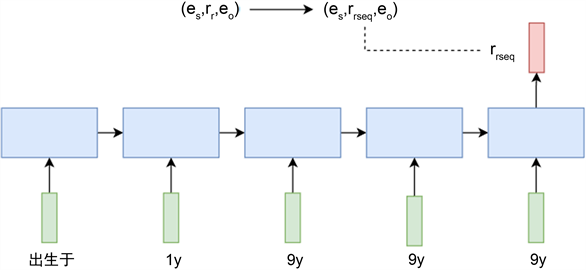
Figure 2. Schematic representation of time series information in a relationship
图2. 时间序列信息在关系中的表示示意图
4.2. 自适应注意力机制
自适应注意力机制(Adaptive Attention Mechanism)是一种用于增强神经网络对输入的关注度分配的方法。它通过学习权重分配来决定模型在不同时间步或空间位置上应该关注哪些信息。这种机制能够使模型更加灵活地处理不同的输入情况,并在需要的地方进行更深入的处理,从而提升模型性能和泛化能力。
注意力机制通俗上可以被描述为:将n个查询向量通过对应的
键值对映射到新的n个输出向量的过程。查询向量用
,
以及
来表示,即注意力机制可以根据所选择的注意力计算公式为每个查询向量计算出对应的加权输出向量。通用的计算公式为如下所示。其中
函数输出一个
的矩阵代表向量Q与对应的键向量K之间的相似度得分,而Softmax函数则是进行归一化操作,保证每个查询向量对应的所有相关权重和始终是1。
(3)
4.3. Conv-ATG模型
目前对时序知识图谱的研究较少,对于时序知识图谱补全领域的关注度更是稀少。现有的技术对于四元组的嵌入通常采用时间和头尾关系实体进行联合编码的方式,没有充分考虑到时间戳信息和实体、关系之间的交互。本模型在自身四元组嵌入过程中引入自适应注意力机制结合卷积神经网络,对于时间信息进行带权重的理解,使其更好的融入上下文表示的语义向量中。
本文提出的Conv-ATG模型在传统的卷积神经网络ConvE静态知识图嵌入模型的基础之上利用LSTM循环神经网络学习时间信息可能包含谓词的序列格式,并增加了自适应注意力机制模块对时间信息的学习效率进行提升,最终以高效且稳定的表现证明了有效性。
Cnov-ATG模型的评分函数如下:
(4)
5. 实验结果
使用MRR、Hit@1、Hit@3、Hit@10进行模型评价。MRR是根据排名的倒数计算的平均值,对于每个查询,模型会返回多个候选答案并按照其得分进行排序。MRR计算方式为将正确答案的倒数作为得分,然后计算所有查询的得分的平均值。MRR的范围是0到1,越接近1表示模型在排名中的表现越好。Hit@N指标是指有多少正确的三元组最终的排序是在topN,值是越大越好的,常使用的是Hit@1、Hit@3、Hit@10。
本次实验使用ICEWS18数据集、WIKIDATA数据集,对Conv-ATG模型与其他时序知识图嵌入模型进行训练、计算,最终统计出对比结果。如表1所示,Conv-ATG模型在Hit@10的评价指标上表现不是最好,但在MRR、Hit@1、Hit@3上均表现出了不错的效果,领先于其他时序知识图嵌入模型。

Table 1. Experimental results on ICEWS, WIKIDATA datasets
表1. ICEWS、WIKIDATA数据集上实验结果
6. 结论
针对时序知识图补全任务,基于ConvE模型和自适应注意力机制融合时间信息表示的Conv-ATG模型通过多层神经网络从全局进行缺失实体预测。其中使用自适应注意力机制的神经网络模型来将时间信息有效地融合到实体的向量表示中,从而集成了更丰富的信息来提高补全的精度。实验结果表明,TGNN方法与多个基线方法相比,实现了更好的补全效果,证明了模型的有效性。
参考文献