1. 引言
1.1. 研究背景及意义
1.1.1. 研究背景
随着工业化、城镇化、人口老龄化进程加快以及生态环境、生活行为方式等发生改变,慢性非传染性疾病已成为居民的主要死亡原因和疾病负担 [1] 。心脑血管疾病、癌症、慢性呼吸系统疾病、糖尿病等慢性病导致的负担占总疾病负担的70%以上,成为阻碍提高健康预期寿命的重要原因之一 [2] 。
心脏病是一种常见的循环系统疾病,它涉及心脏、血管和调节血液循环的神经体液组织。会严重影响患者的劳动能力,是内科疾病中的常见病。心脏病和脑血管病的特点是患病率高、致残率高、复发率高和死亡率高,给社会和经济发展带来了沉重的负担 [3] 。据统计,我国现有的高血压患者达2.7亿、脑卒中患者1300万、冠心病患者1100万。高血压、血脂异常、糖尿病等是心脑血管疾病的主要危险因素,而肥胖、吸烟、缺乏运动、不健康的饮食习惯等也会增加患病的风险 [4] 。中国18岁以上居民中,约四分之一的人患有高血压,接近一半的人血脂异常,并且这些比例还在上升。对这些危险因素进行干预,不仅可以预防或延缓心脑血管疾病的发生,还可以与药物治疗配合,预防其复发。
1.1.2. 心脏病研究意义
心脏病是一种致死率高的危险疾病,需要尽早发现。但很多心脏病患者在早期没有胸闷、气短、乏力、心绞痛等典型症状,这就是“沉默的心脏病”。这导致很多病人无法及时发现自己有心脏病,错过了最佳治疗时机。因此,通过了解身体各项指标和日常生活习惯,来判断是否有心脏病对降低心脏病的死亡率非常重要。
机器学习是一门新兴的学科,它通过周围的环境学习来模拟人类的智能。随机森林是一种基于决策树的集成学习算法,它可以减少过拟合的风险,提高模型的泛化能力。因为每个决策树只使用了部分样本和特征,所以每个决策树都是独立的,并且随机森林可以通过多个决策树的投票或平均值来降低单个决策树的错误率。全连接神经网络有着比浅层体系结构更强的数据处理能力,可以利用出色的服务器性能对海量大数据进行特征挖掘与处理。本文主要利用随机森林和全连接神经网络两种模型对心脏病数据进行训练学习,经过对比得出最优分类算法模型,有利于构建适用于心血管疾病的预测模型,从而辅助医师对心脏病患者提供诊断评估依据。
总而言之,利用随机森林模型对是否患有心脏病提供较为准确的预测,能为医生诊断提供依据,将机器学习与医学相结合,精准诊断并治疗,提高医疗资源的利用效率,从而降低心脏病的死亡率。该方法经推广后可用于其他疾病的预测,对于控制各类疾病发生具有重要积极意义。
1.2. 文献综述
目前有许多针对心脏病的研究模型,然而大部分仅针对热门特征变量进行建模,并未考虑一些新型的影响因素,且使用国内患者数据的影响因素比较陈旧,这会降低模型的预测效能。其次这些研究都是基于类别平衡的数据集,但真实的临床数据多为类别不均衡数据,基于这种数据构建的机器学习模型性能差距较大,且无法直接给出模型基于哪些因素进行预测,这将无法满足医疗领域要求模型可解释的需求。因此本文根据疾病特点使用经典模型进行建模对比,且使用某地区患者数据,使其更好地服务于心脏病的预测。
2011年,G. Subbalakshmi等 [5] 将年龄、血压等因素作为预测患心脏病的指标,用贝叶斯分类器作为内核函数,建立支持决策的心脏病预测系统(DSHDPS)。Alickovic E.等 [6] 采用自回归模型提取特征,并通过k邻近算法、多层感知器和支持向量机等技术来判别心率是否正常。Dimopoulos A. C.等 [7] 将传统心血管疾病评分系统分别与决策树、随机森林和KNN算法结合进行对比分析,发现机器学习适合风险预测研究。Gokulnath等 [8] 提出了SVM的优化函数,将其应用于遗传算法中,提升心脏病预测的效果。Khourdifi等 [9] 利用粒子群优化算法和蚁群优化算法对人工神经网络进行优化,结果证明了所提出的混合方法在处理心脏病分类数据中的有效性和鲁棒性。Valarmathi等 [10] 使用三种不同的超参数优化算法对随机森林和极端梯度提升算法进行参数调整与测试,研究发现随机森林通过随机搜索方式进行参数调优的心脏病预测结果更好。
2. 数据来源与处理
2.1. 数据来源
本文采用来自CDC公开的2021年行为风险因素检测系统(BRFSS)的原始心脏病数据集,其数据总量为438,693条,304个特征变量。分类标签为是否患有心脏病,1代表患有心脏病病,2代表未患心脏病,在所有原始数据中共有22,831条记录为患有心脏病。其中部分特征都存在明显的关联性,且对心脏病的影响较小。
2.2. 数据预处理
在训练机器学习模型之前,特征选择是一个很重要的预处理过程,它能从原始特征集中选择最有用的特征子集,以提高模型的预测性能和泛化能力。当我们遇到维数灾难问题,如果可以挑选出重要的特征变量,然后再进行后续的学习过程,那么维数灾难问题可以减轻。并且剔除不相关的特征变量不仅可以降低学习任务的难度,使模型更易理解,还可以减少过拟合的风险,帮助我们创建一个稳定性良好、泛化性能更强的模型。本文对心脏病数据集的预处理主要采取以下步骤:
1) 变量筛选:依据一些关于影响心脏病风险因素的国内外研究,从临床诊断经验中提取患者的病史和症状,结合心脏病相关的参考文献,选择出高频率且在医学角度与心脏病相关性较强的因素作为自变量。删除特征关联性较为明显的变量因素。最后我们从304个特征变量中选取了30个特征变量作为解释变量进行研究分析见表1。
2) 缺失值处理:统计数据包括实验数据和调查数据,在此类调查数据获取的过程中,客观因素的限制或人为原因造成数据缺失的情况是非常常见的。由于缺失情况对变量特征值损失率过高且数量较大,例如,空值,调查对象回答“不知道”或拒绝回答的,因此我们将这部分数据直接剔除。
3) 离散化:离散化是指对连续的数值变量进行分段处理,可以分为等频和等长两种离散化方法。等频和等长离散化方法不仅可以提高算法的运行速度,而且更有,利于提升模型的预测精度。在此数据集中,如Sex (受访者年龄)的值为[18, 65+)范围内的连续变量,按照等长离散化对年龄数据进行分段处理,得到6类分类数据。
4) 哑编码:当变量不是定量特征时,无法对模型进行训练,因此引入哑变量将不能够定量处理的变量量化,然后得到可用于模型训练的特征。对于有n个分类属性的自变量,通常需要选取1个分类作为参照,因此可以产生n − 1个哑变量。如BMI (体重指数)分为过轻、正常、过重和肥胖四类多分类有序变量,将其赋值为1、2、3、4,通过数字的大小关系来体现程度之间一定的等级关系。
5) 规范化处理:将现有数据进行规范化处理,转化为便于数据分析处理的特征形式。本文旨在分析预测是否患有心脏病,因此分类标签数值化处理为1 = 未患有心脏病,0 = 为患有心脏病。

Table 1. Raw data variable interpretation
表1. 原始数据变量解释
2.3. 患病人数总体分布情况
首先查看数据标签的比例,标签特征为是否患有心脏病,黄色代表患有心脏病的记录共有2994条,比例为6%,蓝色代表未患有心脏病的记录共有48,305条,比例为94%。标签特征相差较大,处于不平衡状态。若直接对此数据进行建模分析是没有意义的,例如:利用机器学习方法建模分类,如果数据集中不均衡的比例超过了4:1,分类器就会倾向于样本较多的类别,如果训练集中有90%的样本都属于同一种类,那么分类器会将所有的样本都判断为属于该类,尽管最后的分类准确度很高,但在这种情况下分类器是无效的。所以我们考虑混合采样的方法对数据进行预处理。采样得到的数据中患有心脏病比未患有心脏病约等于1:1见图1。
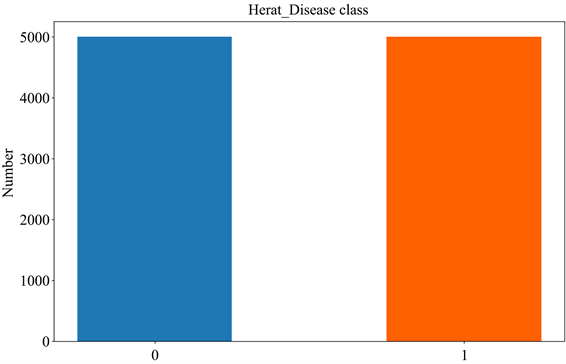
Figure 1. Distribution of heart disease after sampling
图1. 采样后心脏病人数分布图
3. 模型构建
本研究通过信息增益分析训练模型的重要特征信息,模型中数据特征重要性降序排序结果见图2。通过对比不同特征的信息增益值可知,这些重要特征是对模型输出具有不同的影响。其中年龄、高血压、高胆固醇和肥胖是心脏病的关键危险因素。不同的生活方式也会导致人们患有心脏病,包括:食用油炸食品、蔬菜的频率、吸烟、缺乏运动。食用高饱和脂肪和高胆固醇的饮食也会增加心脏病和相关疾病的患病风险,如:心绞痛(如动脉粥样硬化)。此外,部分现有研究中较少涉及的外在因素,如:收入、教育、婚姻等也会在一定程度上增加患心脏病和心脏病发作的风险。

Figure 2. Data feature importance ranking
图2. 数据特征重要性排序
3.1. 随机森林(Random Forest)
在随机森林模型中,我们将分别将数据的70%、30%作为训练集和测试集,建立模型进行预测分析。此方法使用Python中的开源Random Forest包来建立建模。此模型需录入年龄、食用炸土豆的频率和体重特征等不同属性的解释变量数据进行抽样,建立大量决策树预测模型 [11] 。为了获得最佳的变量组合形式,用OOB样本在已训练好的决策树上运行,计算袋外预测误差e1,然后固定其他不变,依次计算决策树第500个特征的特征值,得到袋子外误差ei2。其中随机森林OOB得分为0.8854,OOB错误率为0.1146。
得到随机森林模型的混淆矩阵见图3:
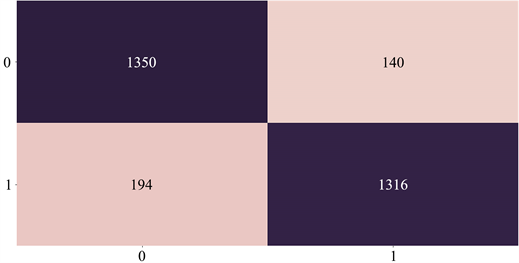
Figure 3. Random forest confusion matrix
图3. 随机森林混淆矩阵
在随机森林模型测试集的3000个样本中,预测正确的共有2666个,预测错误的共有334个。其中有140个样本是将未患有心脏病的样本预测为患有心脏病的样本,而有194个样本是将实际患有心脏病的样本预测为未患有心脏病的类别。
3.2. 全连接神经网络
本文设置了4层隐藏层神经网络来预测是否患有心脏病,以性别、年龄、高血压、高胆固醇等30个变量作为输入,隐藏层节点设为50,输出层节点为2的二分类模型。模型图见图4:
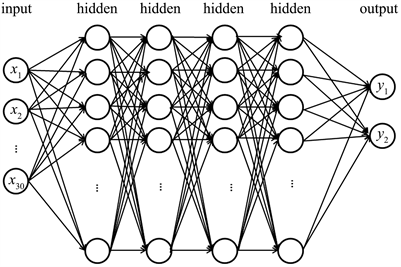
Figure 4. Fully connected neural network structure diagram
图4. 全连接神经网络结构图
得到全连接神经网络的混淆矩阵见图5:

Figure 5. Fully connected neural network confusion matrix
图5. 全连接神经网络混淆矩阵
在全连接神经网络模型测试集的3000个样本中,预测正确的共有个2375,预测错误的共有个625。其中有338个样本是将未患有心脏病的样本预测为患有心脏病的样本,而有287个样本是将实际患有心脏病的样本预测为未患有心脏病的类别。
4. 模型评价
4.1. 模型结果
通过运用随机森林和全连接神经网络算法建立模型,两种模型的混淆矩阵结果见表2和表3;各个模型ROC曲线汇总图见图6;两个模型的评价指标结果见表4。
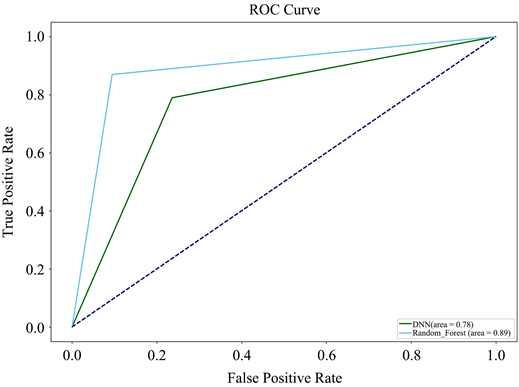
Figure 6. ROC curves of random forest and fully connected neural network models
图6. 随机森林和全连接神经网络模型的ROC曲线
Table 2. Random forest confusion matrix
表2. 随机森林混淆矩阵
Table 3. Fully connected neural network confusion matrix
表3. 全连接神经网络混淆矩阵
Table 4. Comparison of model classification performance index
表4. 模型分类性能指标对比
ROC曲线的横轴FPR表示假阳率,纵轴TPR表示真阳率,ROC曲线越靠近左上角,模型的性能越好 [12] ,因为此时TPR高、FPR低,随机森林模型能够很好地区分正例和负例。
4.2. 结果分析
心脏病患者的数量和影响心脏病的因素逐渐增多,如何选择重要特征变量发现患有心脏病的患者是预测模型的核心内容。提前发现心脏病患者,及时介入治疗,有利于减低心脏病带来的死亡风险。敏感度和召回率两个指标共同反应了模型是否正确预测患者患有心脏病的能力,根据表4可得出两种机器学习模型中基于随机森林模型相较于全连接神经网络模型的分类性能更加优越。随着大数据时代的发展,大部分医学数据难以实现较为高效且快速的数据处理,故传统模型会面临淘汰。在较为前沿的机器学习算法所构建的模型中,随机森林在精确度、召回率、AUC (Area Under Curve)以及准确率4个方面都具有较好的效果,AUC的取值范围在0.5到1之间,越接近1表示模型的性能越好,说明随机森林模型在数据量较大、指标分类较为复杂的医学邻域有较为广阔的前景。同时,相较于全连接神经网络,随机森林不依赖高维变量的组合优化,针对存在较大异质性的数据的情况,我们可以加大决策树来消除具有极端情况的异质性,从而表现出良好的适用性和泛化性。
在大数据新发展格局下,数据类型多样,来源复杂,范围扩大,需要新型生物统计理论方法加以支撑,医疗统计在疾病预测,危险因素分析等方面起着至关重要的作用。随机森林模型的建立应不断与临床需求相适应,选出较为重要的影响因素纳入学习模型进行不断迭代,使得模型更加优化和完善。灵活地将统计应用到医学事业中是时代的大势所趋,更是实现健康中国的重中之重,把人民健康放在首位,大幅提高健康水平,努力全方位、全周期保障人民健康,为全面建设社会主义现代化国家、全面推进中华民族伟大复兴打下坚实的健康基础。