1. 引言
随着物联网和智能穿戴设备的发展,对基于位置的服务(LBS)的需求也日益增强,尤其是在人员活动密集的场所(商城、停车场、医院、工厂、机场等)。虽然全球导航卫星系统(GNSS)在户外广泛使用,但在室内环境中,信号很容易被阻挡、衰减或反射,使其不太可靠 [1] 。在室内环境中,蓝牙、WIFI、超宽带、射频技术等技术替代了全球导航卫星系统。其中,WIFI节点无处不在、无需额外设备的特点,使得WIFI指纹定位成为最受欢迎的热点技术 [2] [3] 。
虽然WIFI指纹定位技术比较成熟且具有广阔的应用前景,但在多楼层和多建筑物的环境中,多路径效应的噪声以及随机波动会影响定位准确性,是一个关键的挑战。传统的WiFi指纹识别方法,例如K-最近邻(KNN) [4] 、加权KNN (wKNN)和支持向量机(SVM) [5] ,需要大量的过滤和参数调整工作,耗时且无法满足实际要求。深度学习(DNN)能够高效地提取特征且需要调节的参数较少,成为理想的解决方案 [6] 。基于深度学习的方法的性能仍然取决于输入训练数据的充分性,并且深度学习是完全连接的,计算的复杂性与神经网络的深度(即层数)直接相关,从而直接影响定位结果的准确性 [7] 。
Nowiki和Wietrzykowski构建了一个模型 [8] ,将堆叠自动编码器(SAE)接在一个DNN网络上,用于预测用户所在的建筑、楼层以及坐标。但模型需要进行数据增强,若样本数量太少,效果则不佳。在文献 [9] 中,Song等人提出了CNNLoc系统,将堆叠自动编码器(SAE)与一维CNN结合起来。堆叠自动编码器从RSSI数据中提取主要特征,然后使用卷积神经网络(CNN)训练数据。该方法在楼层分类中取得了较好的结果,但在室内目标定位方面存在较大误差,容易受到RSSI波动的影响,并且难以剔除RSSI的无效数据。
为了解决以上问题,本文提出了一种基于卷积神经网络(Convolutional Neural Network, CNN)的轻量化室内定位模型。该模型将RSSI转换为标签为坐标的二维灰度图像,并在转换过程中剔除无效数据,以降低RSSI不稳定性的影响。然后使用深度可分离卷积进行特征提取,并通过自适应池化层固定输出大小,以减少全连接层参数量。最后,将提取的特征输入全连接层进行分类。在该模型中,建筑楼层和二维坐标被分开预测。首先根据模型预测建筑和楼层,然后修改模型的全连接层输出以预测目标坐标位置。
2. 模型与方法
2.1. 模型设计
本文模型设计的网络结构如图1所示。模型由两部分构成:特征提取和分类。特征提取网络包括五层网络,首先将预处理好的大小为64 × 64,通道数为1的二维灰度图像加载到网络。第一层是由普通的卷积层、激活函数、最大池化层组成。卷积层输出通道为32,卷积核大小为3,步长为1。激活函数为ReLU,最大池化层为2。目的是提取数据的特征并加快训练速度。然后输入到第二层,第二层到第四层由深度可分离卷积、激活函数、最大池化层组成。第二层深度可分离卷积输入通道为32,输出通道为64,卷积核大小为3,步长为1。激活函数为ReLU,最大池化层为2。第三层深度可分离卷积输入通道为64,输出通道为128,卷积核大小为3,步长为1。激活函数为ReLU,最大池化层为2。第四层深度可分离卷积输入通道为128,输出通道为256,卷积核大小为3,步长为1。激活函数为ReLU,最大池化层为2。最后一层为自适应平均池化层(Adaptive Avg Pool 2d),它可以自适应地将输入张量的高度和宽度降采样到任意给定大小的输出尺寸,有效减少参数量。在特征提取网络的最后一层中使用,以便于进行后续的分类。
第二部分分类由Dropout、ReLU激活函数、全连接层(Linear)组成。为了防止训练过拟合,将特征提取模块提取的特征输出送到Dropout中,p设置为0.5。然后接一个ReLU激活函数,最后将特征送到全连接层中,全连接层将提取的特征映射到特定维度的标签空间,求得预测结果,其输入通道为256,输出为13个类。使用的ReLU激活函数如下所示:
(1)
2.2. 数据预处理
为了降低RSSI不稳定性的影响并提高模型的准确率,对RSSI数据集进行预处理。
1) 格式转换:模型的输入数据为相邻接入点的RSSI转换后的灰度图像。在使用的数据集中,每个采样点中原始RSSI值的范围从−102 dBm到0 dBm,其中0表示弱信号或者零信号,100表示最强信号。由于信号很强和信号很弱的情况极少,所以将强度为100的值转换为0。
2) 图像转换:实验中的数据集采用UTM坐标(UTM, Universal Transverse Mercator),UTM坐标是一种平面直角坐标系统,用于描述地球表面的点,将其表示为带状区域内的坐标值。为了明确转换过程,以室内定位数据集UJIIndoorLoc为例。RSSI转换为灰度图像如图2所示。数据集中包括21049个采样点,每个采样点表示为r = (r1, … ri, … r520),其中ri表示每个AP点的RSSI大小。首先从CSV文件格式的数据集中读取每一行数据,并将其存储为26 × 20的二维矩阵。接下来,将该矩阵转换为灰度图像,其中UTM坐标作为灰度图像的标签值,并剔除无效的图像。在保存图像的过程中,检查是否已经在指定的目录中存在指定的文件夹,如果不存在,则创建一个新的文件夹,文件夹名为对应的建筑和楼层编号。最后将转换后的灰度图像保存到该文件夹中。
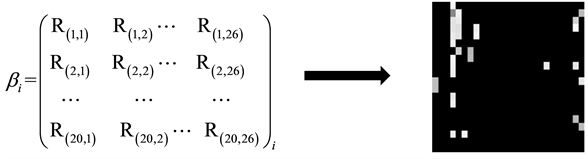
Figure 2. Converting RSSI to a grayscale image
图2. RSSI转换为灰度图像
2.3. 室内定位方法
基于本文提出的室内定位方法,首先将RSSI重建为灰度图像,然后训练网络模型以获取最佳超参数。接下来,将训练得到的网络模型参数加载到预测网络中,以定位建筑、楼层和坐标。训练过程首先进行图像变换,包括尺寸调整、随机垂直翻转和归一化等操作,并导入图像数据。然后定义训练和验证函数,在训练函数中进行损失反向传播和模型参数更新。在验证函数中,模型处于评估模式,不需要更新参数。这两个函数中,模型根据输入数据计算预测输出,并根据预测输出和实际标签计算损失和准确率。最后保存最佳的模型。
在预测过程中,将训练得到的网络模型参数加载到预测网络中,导入所有类别标签,并定义函数将张量转换为图像。将模型设置为验证模式,对验证集中的每个样本进行迭代。对于每个样本,提取数据和标签,并将数据扩展为四维张量以适应网络的输入要求。对于每个数据批次,通过模型进行前向传播,获取预测结果。然后将预测的类别与实际类别进行比较,计算预测UTM坐标与实际UTM坐标之间的欧氏距离,并累加这些距离的平方,以计算模型预测的平均误差。欧氏距离公式如下:
(2)
式中x,y为坐标。
在训练过程中,为了避免过度拟合同时提高模型的泛化能力,采取了“早停”策略。该策略通过监控模型在训练和验证集上的性能指标,例如损失函数或准确率等,来判断模型是否过度拟合,并在模型性能达到最佳时及时停止模型训练。
3. 实验
3.1. 实验环境与数据集设计
实验环境为Ubuntu操作系统,python3.8编程语言和Pytorch1.9.0深度学习框架。硬件采用Intel (R) Core (TM) i7-8700 CPU @3.20GHz内存为16 G,显卡为GTX1080Ti显存11 G,采用CUDA11.0加速计算。
UJIIndoorLoc数据集 [10] 涵盖了Jaume I大学的三座建筑,其中包括两座四层建筑和一座五层建筑。该数据集包含了来自933个RP(参考点)的21,049个WiFi指纹样本,这些样本来自不同的设备和用户。每个指纹都可以通过位置标签进行识别,包括建筑物编号(0~2)、楼层(0~4)以及坐标。重建后的图像数据集按照8:2的划分标准进行了分割,并且剔除了无效图像,划分为训练集(15,897个)和验证集(3,964个),并根据建筑和楼层数进行了13类划分。图3为UJIIndoorLoc数据集类别分布。
Tampere包含两个RSSI数据集 [11] ,分别是TIE1和SAH1。TIE1数据集是在2017年8月至12月期间从坦佩雷大学的Tietotalo大楼收集的,包含10,633个采样点。SAH1数据集是在2017年10月至12月期间从坦佩雷大学的Sahkotalo大楼收集的,包含9,291个采样点。SHA1和TIE1经过重建后转换为灰度图像,并按照8:2的划分标准合并在一起,划分为训练集(12,750个)和验证集(3,183个),并根据建筑和楼层高度进行了9类划分。

Figure 3. Class distribution of the UJIIndoorLoc dataset
图3. UJIIndoorLoc数据集类别分布
3.2. 评价指标
本文使用“准确率”和“平均误差(Mean)”作为评价指标。
准确率是所有分类的总体准确率的百分比(%)
(3)
其中,TP、FP分别是真阳性和伪阳性的数量,而TN、FN分别为真阴性和伪阴性的数量。在定位误差中,平均误差是用来衡量估计位置与真实位置之间的平均距离。用以下公式计算:
(4)
其中,xi表示估计位置的坐标,yi表示真实位置的坐标,n表示分类的数量。
混淆矩阵(CM):它是一个正方形矩阵,展示分类模型的完整性能。CM的行表示真实类别标签的实例,列表示预测类别标签的实例。该矩阵的对角元素定义预测标签等于真实标签的点数。
3.3. 结果
3.3.1. UJIIndoorLoc数据集上的结果
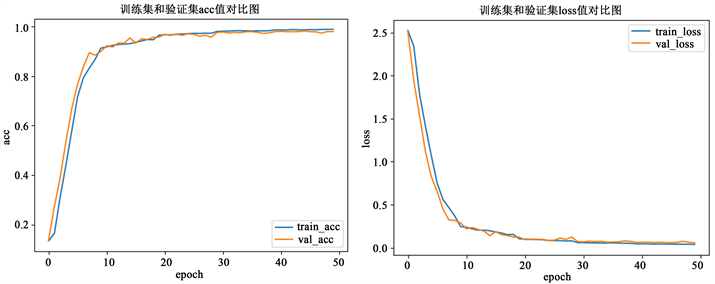
UJIIndoorLoc数据集中,15897个样本用于训练模型,而3964个样本(测试数据)用于评估模型的性能。图4展示UJIIndoorLoc数据集上训练和测试时模型的性能。图5中展示在UJIIndoorLoc数据集中测试数据预测时得到的混淆矩阵图。表1为UJIIndoorLoc数据集上本文模型定位性能与最新室内定位方法的比较,结果显示,本文提出模型的楼层准确率为99%,参数量为48685个,和CNNLoc模型相比,提高了2.97%的准确率。
 (a) (b)
(a) (b)
Figure 4. Accuracy and loss trend graph of the model on the UJIIndoorLoc dataset
图4. UJIIndoorLoc数据集上模型的准确率和损失变化趋势图
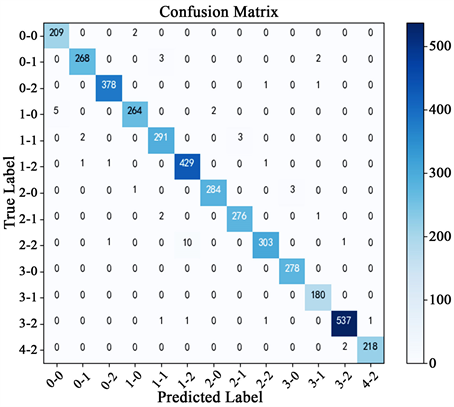
Figure 5. Confusion matrix of the model trained on the UJIIndoorLoc dataset
图5. UJIIndoorLoc数据集上模型训练的混淆矩阵

Table 1. Comparison of the localization performance of our model on the UJIIndoorLoc dataset with the latest methods (results not reported in the benchmark paper are marked with a hyphen “-”)
表1. UJIIndoorLoc数据集上本文模型定位性能与最新方法的比较(基准论文中未报告的结果用连字符“–”标记)
3.3.2. Tampere数据集上的结果
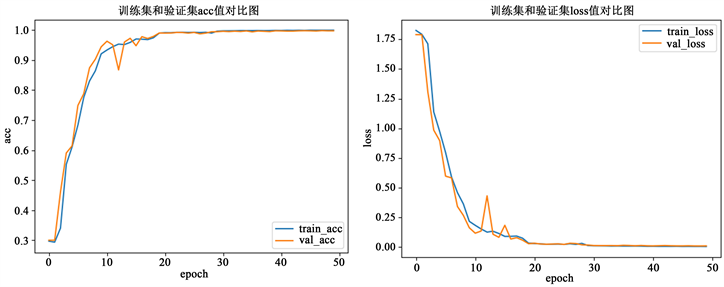
Tampere数据集中,12750个样本用于训练模型,而3183个样本(测试数据)用于评估模型的性能。图6展示了Tampere数据集上训练和测试时模型的性能。图7中展示了在Tampere数据集中测试数据预测时得到的混淆矩阵图(CM)。表2为Tampere数据集上,本文模型定位性能与最新室内定位方法的比较,实验结果显示,本文提出模型的楼层准确率为99.7%,参数量为47657个,和CNNLoc模型相比,提高了3.67%的准确率。
 (c) (d)
(c) (d)
Figure 6. Accuracy and loss trend graph of the model on the tampere dataset
图6. Tampere数据集上模型的准确率和损失变化趋势图
Table 2. Comparison of the localization performance of our model on the Tampere dataset with the latest methods (results not reported in the benchmark paper are marked with a hyphen “-”)
表2. Tampere数据集上本文模型定位性能与最新方法的比较(基准论文中未报告的结果用连字符“–”标记)
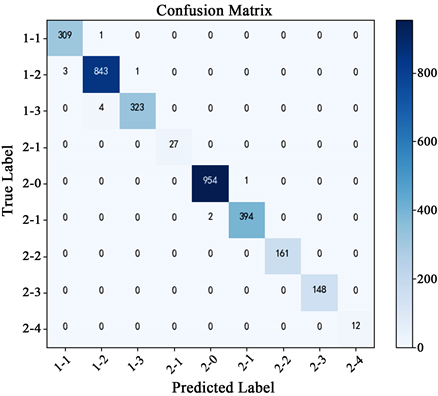
Figure 7. Confusion matrix of the model trained on the tampere dataset
图7. Tampere数据集上模型训练的混淆矩阵
3.3.3. Tampere数据集上的结果
在进行深度学习模型训练时,输入图像尺寸越大,训练时间越长。为了探究不同的输入图像大小和激活函数对定位性能影响,本文在UJIIndoorLoc数据集上分别以输入大小为64 × 64、128 × 128、224 × 224的图像进行测试,结果显示64 × 64为最佳输入尺寸。得到不同参数性能比较结果如表3所示。
Table 3. Performance comparison with different parameters
表3. 不同参数性能比较结果
4. 小结
本文提出一种基于卷积神经网络的轻量化室内定位模型,对于提高室内定位精度和减少模型参数量有着重要的意义。通过使用深度可分离卷积层和自适应池化层提取特征,在保证精度的前提下,显著降低了模型参数大小,并且降低坐标定位的误差。
参考文献