1. 引言
随着我国经济的高质量发展,铁路交通的运输生产力得到了快速提高,铁路的安全问题也越来越受到重视 [1] 。铁路营业里程的增加和机车运营速度的提高,给铁路安全运营带来了巨大压力,对铁路安全行车的保障技术提出了更高的考验。根据相关的调查研究,机车驾驶室的工作环境比较恶劣,容易引起司机疲劳驾驶而出现操作失误,这是导致铁路安全事故的一个因素 [2] 。司机能否在列车开车停车、进出站等重要节点做出正确手势是衡量工作质量的重要指标。不正确的手势判断不利于列车运行安全,因此对司机手势动作的监控识别十分重要。机务段依赖人工方式对机车司机室监控视频,考核司机的违章行为,工作量繁重且耗时较长。因此需要探索出一种智能化分析机车司机室监控视频的方法,达到准确、快速地识别司机手势动作的目的,不仅可以减少监管系统的人力资源浪费,还能够帮助列车更加安全高效地运行。
近年来,基于深度卷积神经网络的计算机视觉技术在轨道交通司机行为识别领域受到了相关研究人员的广泛青睐。文献 [3] 首先利用Alphapose姿态估计算法 [4] 提取人体骨骼的关键点坐标,设计了行为分类器对手势行为的骨架点坐标进行预分类识别,然后通过YOLOv5目标检测算法检测感兴趣物体的位置,最后将骨架检测和目标检测结果进行融合决策得到行为的识别结果,大幅度提高了对各类危险驾驶行为检测的准确性和鲁棒性。文献 [5] 提出了一种基于OpenPose [6] 神经网络模型的肢体识别算法,结合目标检测模型和手势动作的知识库,对司机驾驶过程中的手指确认等操作进行检测和判断是否标准。文献 [7] 设计了一种基于区域三维卷积神经网络(Region Convolutional 3D Network, R-C3D)的司机手势识别模型。通过深度学习神经网络的训练和调优措施,凭借着RC3D网络中的特征提取子网络、时序提议子网络和行为分类子网络,可以实现高准确率且快速地识别和定位司机手势的动作。文献 [8] 提出一种多时空尺度的融合网络RepC3D (Re-parameterization Convolutional3D)。首先通过背景消减法获取目标动作区域,然后再对目标区域进行RGB和光流转化,接着输入深度学习神经网络,并提取出视频时序特征和空间特征,最后经过RepC3D块将获取到的特征进行逻辑运算,获取到融合信息。在地铁司机手势动作的数据集中进行测试,该算法模型具有较高准确率和较低漏检率的性能表现,可以有效识别司机的手势行为。上述研究者全部采用深度卷积神经网络实现列车司机手比动作的检测。然而,基于深度卷积神经网络的姿态估计算法更加擅长提取局部特征,对于全局特征的理解具有一定的局限性,限制了检测精度的进一步提高,同时其推理时耗费计算资源较多,检测速度较慢。
Transformer如今被广泛应用于自然语言处理和计算机视觉领域 [9] 。DETR (DEtection TRansformer)作为首个使用Transformer做目标检测的模型,是一种端到端可学习的目标检测器,非常具有创新性且性能优越 [10] 。DETR将目标检测建模成集合预测的任务,在训练过程中,使用二分图匹配预测和标签进行训练,而测试时不需要后处理即可产生所有结果。DAB-DETR [11] 提出使用动态的锚框用于DETR,直接将框坐标作为询问输出到Transformer的解码器中。在每一层动态更新box。使用box可以加速训练收敛,同时可以使用box的高宽对位置注意力图建模。DN-DETR引入去噪任务直接把带有噪声的真实框输入到解码器中,在DAB-DETR的基础上进一步加速了收敛。去噪任务仅在模型训练时出现,推理时并不需要,不会给模型的实际应用带来额外负担 [12] 。DINO模型第一次让DETR类型的检测器取得了目标检测的最优性能,在COCO数据集上取得了63.3 AP的性能,相比之前该类型的检测器将模型参数和训练数据减少了十倍以上 [13] 。DINO设计了训练模型识别负样本的方法,不仅要回归真实框,还需要辨别负样本。提出了混合查询选择方法,有助于改善询问的初始化。另外,DINO引入非临近层的特征,增加了感受野的范围,提高小目标的表达能力。
本文在前人的研究基础上,提出了一种基于DinoPose的列车司机手势动作识别算法模型。首先采用本文所提出的DinoPose姿态估计算法,提取机车驾驶室监控视频中的列车司机右侧手臂和躯干关键骨架点的坐标位置信息,然后根据右臂和躯干的角度、位置和模长等空间信息,建立司机手比确认动作的识别模型,最后将识别结果和机车LKJ信息 [14] 进行关联分析,实现手比动作违章的检测和判断。根据试验结果,本文所设计的基于DINO-POSE的列车司机手势动作识别算法模型,通过OKS (Object Keypoint Similarity)指标衡量人体关键骨架点的检测效果,其mAP达到了95.72%,手比项点的检测准确率达到85.74%以上。能够满足铁路局机务段机车司机室监控视频智能分析的实际业务需求,这对保障机车安全行驶,提高监管部门的工作效率有着重要意义。
2. 模型算法
2.1. DinoPose
本文在Dino网络的基础上提出DinoPose,利用Transformers中的编码器–解码器结构来执行基于回归的行人和关键点检测,成功的将Dino从目标检测扩展到二维人体骨架点检测上。
DinoPose由主干网络、Transformer编码器、Transformer解码器、关节点检测分支、目标框分支和置信度分支组成,如图1所示。输入的图像经过主干网络提取C3、C4、C5的多尺度的特征后展平送入Transformer编码器,Transformer编码器进一步融合了不同尺度的特征并提取得分最高的前N个特征作为初始查询(query),和经过融合的键(key)、值(value)特征送入Transformer解码器后进行计算,经过检测框分支和置信度分支得到N个人体的检测框(x, y, w, h)及置信度,关节点检测分支预测得到人体的各个关节点相对人体检测框中心点的偏移值
和该关键点置信度。在推理过程中,我们首先得到大于置信度阈值的人体检测框,随后将人体检测框的中心点(x, y)与各关键点偏移值相加得到人体各个关键点
,只保留置信度大于0.5的关键点并过滤掉人体检测框之外的关键点。与基于特征图目标框回归的2D人体骨架点模型算法相比,DinoPose通过利用Transformer范式把检测问题转换为预测集的问题,实现了对模型预测结果和图片中位置的解耦。DinoPose避免了传统的稠密目标检测算法中多个预测值对应于一个真实样本的问题,从而去除了后处理非极大值抑制算法,更好的适配于现实拥挤场景问题,实现了真正的端到端。
2.2. 关键点去噪训练
与DINO相同,DinoPose使用基于集合的匈牙利损失,对每个输出结果和真实样本进行一对一的标签匹配。我们使用Focal loss损失函数作为人体置信度损失
和关键点置信度损失
,对于人体检测框使用L1损失和GIOU损失进行回归(合为
),对于人体关键点回归,使用L1损失
和OKS损失
。最常用的L1损失对小目标姿态和大目标姿态具有不同的尺度差异,为了缓解这个问题,本文额外使用对象关键点相似性(Object Keypoint Similarity, OKS)损失进行人体关键点回归,其可以表示为下式:
(1)
式中,
是第i个预测关键点和真实关键点之间的欧式距离,
是真实关键点的可见性标志,s是对象比例,
是每个关键点的常数系数。如上所示,OKS损失通过进行归一化,使每个关键点的重要性相等,从而缓解不同的尺度姿态目标的损失差异。

Figure 1. Structure diagram of DinoPose
图1. DinoPose结构图
由此,DinoPose的一对一的标签匹配可以表示为下式:
(2)
式中,
、
、
、
、
分别代表损失的权重。
DINO使用去噪训练技术,在稳定训练和加速收敛方面非常有效。我们同样在本文中将去噪思想引入到关键点训练中去,如图2所示。我们将添加噪声的真实目标框及其标签提供给解码器,并训练模型来重建目标框和目标关键点。
因此,DinoPose的损失函数可由下式表述:
(3)
式中,
代表基于匈牙利匹配的损失,
代表去噪损失,M代表模型的解码器层数,N代表总共有N组去噪损失。
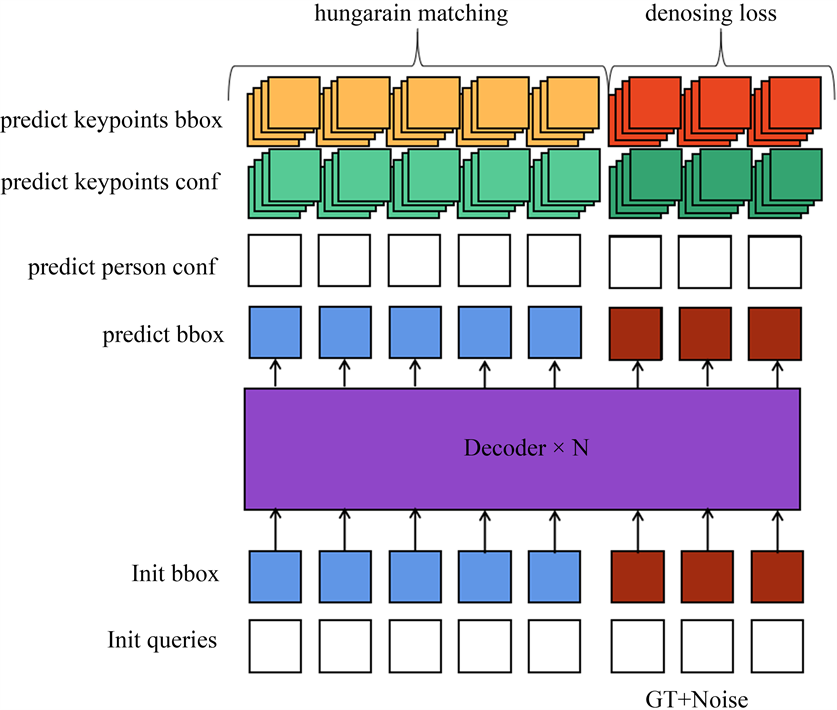
Figure 2. Denoising training of Dinopose
图2. Dinopose去噪训练
2.3. 后处理行为判别
当完成人体关键点估计后,我们可以通过分析人体各关节之间的角度关系得到司机的姿态和动作,通过人体各关节点坐标相减得到人体肢体的向量,通过余弦公式得到肢体之间的角度。通过计算右大臂和躯干角度α、右大臂与右小臂角度β辨别司机是否正进行手势,设定如果α大于90˚且β大于90˚时,判定司机处于做手势的状态,如图3所示。
3. 实验及结果
为了验证本文所提出算法的效果,本文搭建DinoPose网络模型进行了训练,并针对各项优化的效果进行评估。
3.1. 数据收集与参数设置
本文采集了多组列车驾驶室的数据抽取关键帧作为训练集和测试集,标记其中出现的司机人体关键点和人体目标框,标注数据采用COCO关键点标注格式,共标注左右眼、左右耳、鼻子、左右肩、左右肘、左右手、左右髋、左右膝、左右踝17个人体关键点。共标注13,258张图片,数据按10:1的比例随机分为训练集和测试集,分别为11,933张和1325张。其中测试集共有364个手比行为。训练集共有4328个手比行为。
本文在8块A30显卡上进行了训练,模型的主干网络设置为经过Imagenet数据集预训练的ResNet50,Transformer的编码层、解码层设置为6层,训练集和测试集图片统一输入尺寸为(384, 288),批尺寸(batch size)设置为16,训练步数(epoch)设置为200,采用Adam梯度下降方法,初始学习率为0.0001。本文采用OKS作为每张图片人体关键点识别好坏的衡量标准。统计测试集所有图片OKS计算MAP (均值平均精度)作为测试集的衡量指标。
3.2. 实验结果分析
表1和图4统计了训练后DinoPose的精度以及与其他常规算法的对比。相比于Openpose和Yolo-pose算法,本文在精度做到了最好,在耗时上,本文的方式超越了Openpose方法,但略逊于Yolo-pose算法。DinoPose的检测效果如图5所示。

Table 1. Performance comparison of DinoPose accuracy with other algorithms
表1. DinoPose精度与其他算法性能比较

Figure 4. Performance comparison of DinoPose accuracy with other algorithms
图4. DinoPose精度与其他算法性能比较图
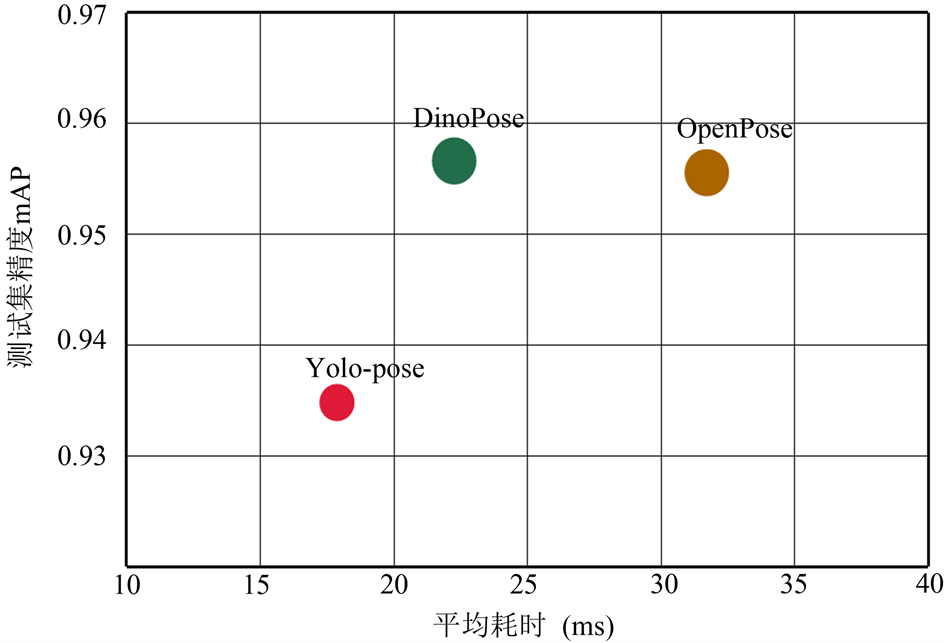
Figure 5. Detection effect picture of DinoPose
图5. DinoPose检测效果图
表2所示展示了基于角度分析的人体检测后处理的测试集手比识别情况,我们使用精确率(Precision)和召回率(Recall)衡量在测试验证集上的基于角度分析的人体检测后处理的效果,如表3所示。
Table 2. Test set gesture detection statistics
表2. 测试集手势检测统计
Table 3. Effectiveness of gesture detection based on angle analysis
表3. 基于角度分析的手势检测效果
4. 结论
本文利用Transformers中的编码器–解码器结构来实现基于回归的人体骨架关键点检测,提出了一种端到端的列车司机手势动作识别算法模型DinoPose。DinoPose由主干网络、Transformer编码器、Transformer解码器、关节点检测分支、目标框分支和置信度分支组成,将Dino网络从目标检测成功扩展到二维人体骨架关键点检测。通过多组列车驾驶室的视频图像所抽取的关键帧数据集测试,本文所提出的算法在精度上优于Openpose和Yolo-pose算法,能够满足铁路局机务段机车司机室监控视频智能分析的实际业务需求。
考虑到本文所提出方法的精度测试仅局限于铁路场景列车驾驶室驾驶员视频图像数据集,此后还需要在其他公开数据集上与各基准方法进行对比测试,进而验证本文所提出方法的泛化能力,扩大其应用范围。此外,由于本文所提出方法与实际铁路业务产品强相关,还需要考虑对DinoPose进行边缘端的应用部署。
NOTES
*通讯作者。