1. 引言
随着经济的发展,网购现已得到全方位的普及,成为了我们日常生活中不可或缺的一部分,因为其有方便快捷、省时省力、送货上门的各项优点,已经越来越受到人们的青睐,并随着人们经济能力、消费水平的提高,对网购体验的需求也愈发上涨,网上各大零售业务间的竞争也愈发激烈,在各平台规模不断扩大、商品种类数不断增加的同时。为了能够吸引消费者的目光并增加商品的销量,某些商家开始采用虚假交易数据的竞争手段进行对商品的推广,最为典型的经营行为有:虚标价格,虚假销量,刷好评 [1] 。本文通过网络营销公司提供的商品数据以及店铺数据,通过定量分析和定性分析结合的方法来剖析商品出现异常的数据原因,定义部分数据作为衡量商品是否出现异常的指标,并且利用这些指标来创建数学模型对和效用函数构建出查找异常商品的数字模型,能够从大量的商品数据中识别出属于商品价格或者销量异常的商品,为网络销售平台提供准确的目标商品 [2] [3] 。
2. 问题分析
通常情况下,电商平台的各类商家会采用刷单的行为来提高竞争力。本文使用的数据集是某电商交易平台收集的海量交易商品数据,总数据分为商品数据和店铺数据,商品数据共有21个字段(主要的两个字段为:价格字段ITEM_PRICE,销量字段ITEM_SALES_VOLUME),共有4个月份数据,分别为2021年6月(7,677,206例)、7月(4,133,204例)、8月(4,861,351例)、9月份(4,771,652例)数据,按照DATA_MONTH字段区分,店铺数据和商品数据之间通过USER_ID字段进行关联,采用数学建模的方式,从全部商品数据、店铺数据中识别出可能的异常商品,为网络零售平台查找异常商品提供目标对象 [4] [5] 。
3. 模型建立
3.1. 建模思路
除通过挖掘异常价格、销量的相关指标,以建模的手段将所有的指标进行融合应用,最终得出识别异常商品的模型,再经过调优的操作进行效果评估,最终得出异常商品。技术主要采用numpy和pandas模块,对百万级别的商品数据进行分析和建模,对于构建的模型需要结合人工观测多次调优,确保模型的可行性能贴合实际应用 [6] 。
3.2. 特征工程
3.2.1. 价格异常特征
通过分析数据和查阅相关资料,我们发现价格异常通常具有价格波动较大,稳定性较差,在同品牌同一类目中具有相对差值较大等特征,且与店铺的好评度、开店时长等具有一定的相关性。根据现有数据,我们构建了如下指标:
1) 商品信息缺失率
将商品特征缺失较多的归类为异常商品,因数据格式的原因的,部分商品特征无法读取缺失,所以对该类特征缺失的部分进行替换的操作,以特定的值替换缺失区域,再用该特定值代替“NaN”,以缺失的特征个数与总特征个数的比值作为指标来评价异常商品 [7] 。
命名为loss_rate:
(1)
2) 相邻两月的共同商品数据的价格稳定度
两个相邻的商品数据中会存在共同的商品,此类商品用两个月的价格差与较小的一个价格的比值表示这两个月的价格波动程度来作为稳定度 [8] 。波动程度较大的一般为异常商品(
、
表示相邻两个月的价格,
表示相邻两个月份价格中较小的一个月的价格)。
命名为fluc_rate_mn (mn表示相邻的两个月份数),模型如下:
(2)
3) 四个月共同出现的商品价格稳定度
四个月份共同出现的商品,单个价格和四个价格均值的差值的绝对值数与四个价格的均值之比来表示该商品在四个月中的稳定度指标(
表示某一商品价格,
表示该商品四个月的均价)。
命名为price_volatility_0n (n表示月份数),模型如下:
(3)
4) 四个月共同出现的商品价格指标稳定度
四个月共同出现的商品,以其每个月的单个价格与四个月的均价差的平方和的二次方根值为自变量,进行sigmod化,将两端的峰值进行归一化处理,以此来表示稳定度 [9] (P6,P7,P8,P9表示商品所属月份对应的价格,
表示同一商品四个月的均价)。
命名为price_stab_e,模型如下:
(4)
5) 商品单价在同类商品均价中的稳定度
同类商品的价格波动程度较其他维度的价格波动程度更为准确,选取缺失率最低的三级类目为分类指标,以偏离同类商品均价的程度来表示商品价格的异常程度,用计算标准差中每个商品价格的占比大小来表示该商品偏离均价的高低 [10] (
商品价格,
同类商品价格均值)。
命名为price_offset_0n (n表示月份数),模型如下:
(5)
6) 补差价商品价格的稳定度
日常生活中,网购时补差价数值一般不会很高,如果补差价值很高,可视为异常商品 [11] (
表示补差价的商品价格,
表示该类商品的平均价格,n表示商品数量)。
命名为price_diference_deviate,模型如下:
(6)
7) 店铺的评分评价店铺的优劣
以店铺数据中的商品描述得分、物流得分、服务得分占总分值的比例来评价店铺的优劣(
商品描述得分,
服务得分,
物流得分)。
命名为score,模型如下:
(7)
3.2.2. 销量异常特征
通过数据分析和查阅资料,我们发现销量异常具有销量通常较大,不同月份之间销量的波动较大、稳定性差,普通店销量高于旗舰店销量,存在刷单刷好评情况等。因此构建如下指标:
1) 绝对销量
为了降低销量在高点的斜率,以销量得二次方根值来表示销量得绝对销量值(
表示某商品的销量)
命名为abs_sales,模型如下:
(8)
2) 两个相邻月份的商品数据的销量稳定度
两个相邻的商品数据中会存在共同的商品,此类商品用两个月的销量差与前一个月份的销量的比值表示这两个月的销量波动程度。波动程度较大的一般为异常商品(
、
表示某商品相邻两个月的销量)。
命名为sales_fluc_mn (m,n表示相邻月份数) ,模型如下:
(9)
3) 四个月共同出现的商品销量稳定度
四个月份共同出现的商品,其中之一的销量和四个销量均值的差值与四个销量的均值之比作为稳定度的指标(
表示某商品的销量,
表示该商品四个月销量的均值)
命名为sales_volatility_0n (n代表月份数),模型如下:
(10)
4) 四个月共同出现的商品销量波动稳定度
根据幂函数的函数特征,指数越低,函数值越靠近x轴,适合波动程度较大的自变量的处理,四个月共同出现的商品,以其销量十分之一次方来将销量的波动程度降低,用以表示商品的销量稳定程度(
表示商品某一月的销量,
表示该商品四个月销量的均值,
表示月份数)。
命名为sales_stab_e,模型如下:
(11)
5) 商品销量在同类目商品销量中的稳定度
以三级类目为分类参照,同类商品的均销量与单个商品的销量差再与同类销量的比值代表这一稳定度的指标(
表示商品的销量,
表示同类商品的均销量)。
命名为sales_differ_0n (n表示月份数),模型如下:
(12)
6) 评销比
评论数与销量的比值为评销比,代表每件商品的评论数,如果销量数据是刷单刷出来的,那该商品的评销比值一定异常,但因为评论数采用历史沿用数据,所以只能用开店时长算出商品的月均评论数来计算评销比,计算出的评销比波动较大不宜观察及总结,所以我们采用sigmod函数处理(其中
表示的是销量的数量,
表示的是开店时长的月份数) [12] 。
命名为ev,模型如下:
(13)
7) 与官方旗舰店的销量差
消费者在选择同品牌的商品时,考虑到真假的问题,更多会优先选择旗舰店的商品,所以一般旗舰店的商品较普通店铺卖的更好,但商品的种类不同,所对应的销量也各不相同,所以我们最终采用同品牌的商品中销量最高的值为参照,以同品牌普通店铺的商品销量与之做对比作为一个评价商品异常的指标 [13] (S表示销量)。
命名为differ,模型如下:
(14)
3.2.3. 特征归一化
所有评判商品异常的指标计算出来以后,应对最终模型的需求,需要将所有指标进行归一化处理 [14] (其中x表示所需要的任何一个指标,
表示所选指标的最小值,
表示所选用的指标的最大值)。
(15)
3.2.4. 特征指标总结
所有评判商品异常的指标如下表1和表2所示。

Table 1. Price anomaly judging characteristics
表1. 价格异常评判特征
Table 2. Sales anomaly judging characteristics
表2. 销量异常评判特征
3.3. 模型预测与评判
3.3.1. 预测模型
预测模型包括价格异常预测模型和销量异常预测模型。价格异常预测模型将同类商品的价格稳定度、补差价商品的价格稳定度、多次出现商品的价格稳定度、相邻月份共同出现商品的价格稳定度进行线性融合,不同的稳定度指标对结果的贡献度不同,因此通过权重因子W进行调节。同时考虑到一般情况下开店时长越长、店铺评分越高出价格现异常的情况应该是越少。当然存在店铺刷分的情况,因此利用指数模型进行调节。一般情况下商品的信息缺失率高,商品出现异常的情况会增加。最终得出价格异常商品的模型如公式(16)。
销量异常预测模型将绝对销量值、相邻月共同商品的销量波动程度、多次出现商品的销量波动程度进行线性叠加,同时设置调节因子W1,将缺失率、评销比、销量稳定程度、销量的对数值进行乘性叠加。同样的,一般情况下开店时长越长、店铺评分越高销量出现异常的情况应该是越少,因此将其作为分母。最终得到销量异常的预测模型如公式(17)。
(16)
(17)
3.3.2. 参数选择和模型评价
对筛选后的价格异常商品进行按照总样本的2%进行抽样,与日常生活中类似的网络交易商品价格比对进行人工添加标签确认作为验证集。模型测试多组不同权重值计算出来的异常概率值,依据F1分数作为评判标准选出最优的权重组合,之所以选择F1分数作为评判标准是因为F1分数作为准确率和召回率的加权平均值,可同时考虑准确率和召回率,以便重新计算新的分数,F1分数计算 [15] (18):
(TP:真阳性,FP:假阳性,TN:真阴性,FN:假阴性)
(18)
价格异常分数计算所需指标的权重最优组合是通过遍历网格(表3)最终得出F1分数最高的组合Wet_comb_1 (如图1),计算最优权重组合的确认后的标签与预测标签计算准确率与召回率:准确率为0.90,召回率为0.88。
对筛选后的销量异常商品进行按照总样本的1%进行抽样,与电商平台的同类商品实际观测到的数据对比再次确认标签作为验证集,模型测试多组不同权重值计算出来的异常概率值,同样依据F1分数作为评判标准选出最优的权重组合,价格异常分数计算所需指标的权重最优组合是通过遍历网格(表4)最终得出F1分数最高的组合Wet_comb_1 (如图2),计算最优权重组合的预测标签与确认后的标签的准确率与召回率 [16] :准确率为0.874,召回率为0.875。
Table 3. Price index weight test grid
表3. 价格指标权重测试网格
Table 4. Sales index weight test grid
表4. 销量指标权重测试网格
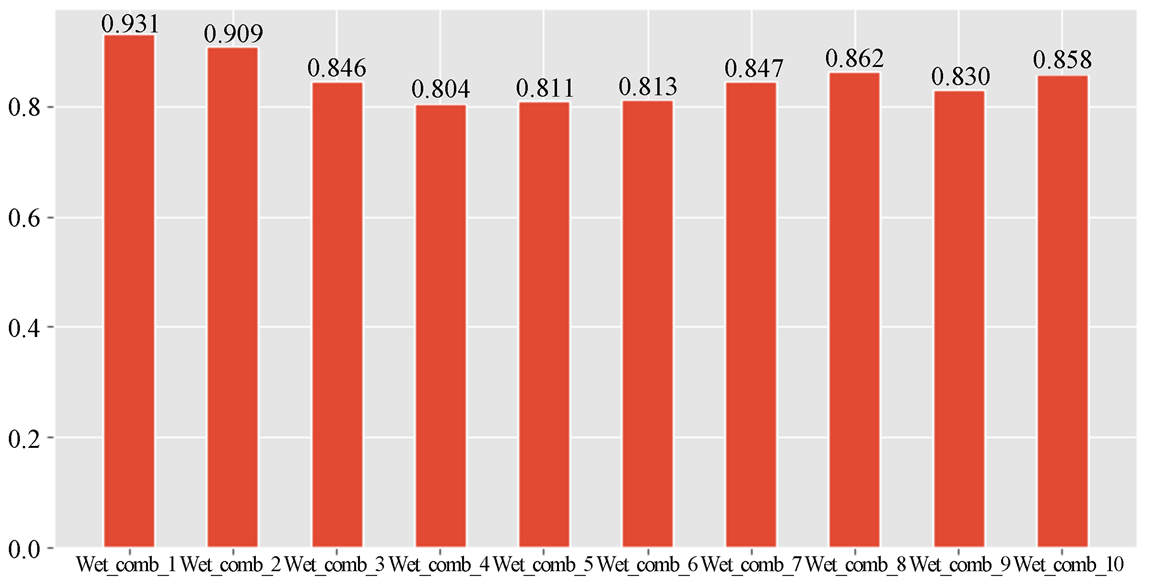
Figure 1. Price anomaly indicator weight recombination F1 value
图1. 价格异常指标权重组F1值
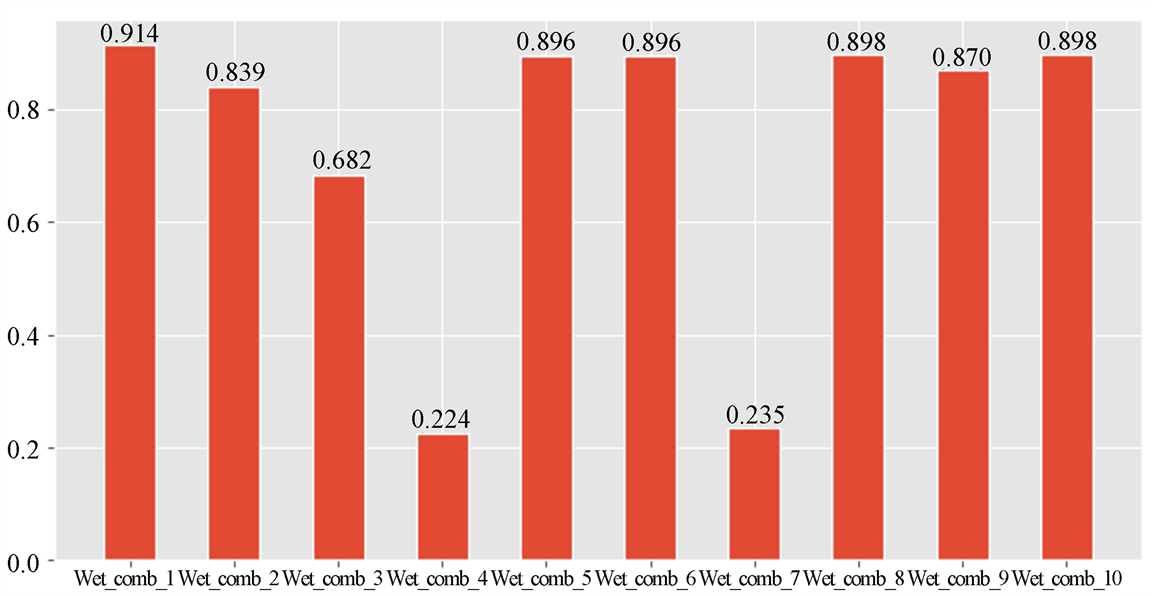
Figure 2. Sales exception index weight reorganization F1 value
图2. 销量异常指标权重组F1值
4. 结果分析
经过模型的筛选,从总样本千万的数据集中筛选出6月价格异常4365例,销量异常12,569例,7月价格异常2350例,销量异常6767例,8月价格异常2764例,销量异常7959例,9月价格异常2713例,销量异常7813例,异常的总占比为2.2‰,五金/工具类的商品更容易出现异常的情况,电子元件或电子产品的异常占比也相对较高,这一种类的商品更容易有价格或者销量的波动,所以商家利用这一特征钻空子,因此需要重视该类问题。
通过计算模型的准确性可以看出,基于稳定度的异常商品(价格、销量)识别模型拥有较高的识别能力,对于复杂的数据集也能合理的应对,能够从海量的商品数据中快速的计算出商品异常的概率,辅助相关电商监管机构准确、快速地完成筛选处理。需要注意的是该模型需要足够的历史数据来辅助模型的调优与测试,确保其可扩展性和可维护性,以便将来随着数据量的增长进行优化和改进。
基金项目
2020年新疆维吾尔自治区自然科学基金创新环境建设专项(2020D01C001),新疆维吾尔自治区高等学校科学研究计划资助(XJEDU2023P127)。
NOTES
*通讯作者。