1. 引言
在合适的环境条件下,强风暴内部下沉冷空气到达近地面向外流出与环境空气交汇形成的界面称为阵风锋,属于一种中、小尺度灾害性天气状况。阵风锋近年来在气象灾害预防中备受关注,主要是其过境时引起阵性大风和低空风切变,而且会触发新的对流或加强原来的对流,造成环境温度降低,风向变化,地面气压值升高,通常伴随着大风大雨的天气现象。容易造成船舶出海、飞机飞行安全和农作物倒伏、损害等,影响日常生活生产和人民的生命财产安全。对其进行准确的自动识别及报警一直是气象业务中的重点难点,而对阵风锋探测和识别几乎世界各地都在进行,因为阵风锋过境往往伴随着严重的灾害性天气,因此对阵风锋的探测和识别能更好的加深对其引起的气象灾害的认识,对提高此类灾害性天气的短临预警能力显得尤为重要,也对气象防灾减灾具有重要意义。
目前国内国外的各种研究大部分都基于多普勒天气雷达数据资料,CINRAD新一代多普勒天气雷达相比于其他雷达产品拥有更强的三维观测能力,更广的探测范围,更高的高时空分辨率,以多角度体扫模式获取不同仰角层的雷达体扫资料,将一个雷达作为一个统计样本,统计每个样本的阵风锋回波特征,包括:强度场、速度场、谱宽场、组合反射率、反射率因子垂直剖面。其中阵风锋在强度图上表现为一条线状或弧状回波,在雷达气象学上称之为窄带回波。阵风锋在速度场上表现为径向速度辐合(切变),包括风速辐合或风向切变两种情况,这两种情况的径向速度梯度都在锋线处达到最大。阵风锋从出生到消亡时间短,空间尺度小,给检测识别造成了很大难度。有关阵风锋的识别及各种特征分析的研究由来已久如表1所示,Uyeda早在1986年就开始了对阵风锋识别的研究,其在对阵风锋的多普勒雷达回波特征统计分析后,通过改进气旋识别算法,提出了基于阵风锋速度辐合线的识别算法。美国Troxel [1] 等人在1994年基提出了阵风锋识别史上具有里程碑意义的MIGFA算法,其以雷达数据结合阵风锋的气象学机理和时间空间等维度上的特征,在TDWR雷达和ASR-9雷达分别取得了75%的准确率和88%的准确率。后来的学者们以此为基础不断改进和完善,麻省理工学院林肯实验室的Smalley等(2005)利用模板函数法的方法实现了对线状回波的提取,目前该方法已经被当作美国新一代天气雷达NEXRAD中阵风锋识别算法的核心之一。随着中国多普勒雷达的增加,国内学者们也相继基于MIGFA算法提出了很多识别算法,郑佳峰等 [2] (2013)通过计算每个回波点的双向梯度来保留线状的回波,通过双向梯度法识别低仰角阵风锋。在此基础上也有学者引入了图像识别处理技术,冷亮(2016)引入了数学形态学,此外,徐月飞 [3] 等(2020)通过卷积神经网络提取阵风锋在雷达图像上的特征,提出了阵风锋的图像识别算法,也取得了74%的识别正确率。尽管CINRAD数据为阵风锋的研究和识别提供了大量有用的信息和阵风锋实例,由于地形、风暴母体、边界层环境等影响,窄带弱回波的长短、强弱、走向等特征变化多端,无明显规律性可循。加之阵风锋回波“窄带”和“强度弱”的特征,任何一种算法做推广时都需要针对当地的阵风锋数据特征做相应调整,考虑到阵风锋在不同地理环境下存在区域差异性,我国在气象业务上至今都还没有一个稳定的、成熟的阵风锋识别方法。

Table 1. The development history and accuracy comparison of the wind front recognition algorithm
表1. 阵风锋识别算法发展史及准确率对比
在雷达图像上以窄带回波这一特征对阵风锋进行定位及检测,本质上就是计算机视觉中的目标检测和识别以及图像分割问题。对于传统的数理方法,大都只能识别特定的大小形态的窄带回波,算法泛化能力十分有限,难以推广。为了弥补这种不足,提升在各种复杂回波里自动识别出阵风锋的窄带回波特征的能力和算法泛化性能。本文选取2013~2016四年里河南省各市的多普勒天气雷达数据,将Mask RCNN模型和resnet101主干网络引入阵风锋的识别中,采用多普勒雷达产品生成的雷达图,将图像载入到模型中,将resnet主干网络提取到的多层次特征图与生成的候选框载入RPN网络,进行分类和回归,再利用Mask分支进行分割。分类是用于检测出图像中有无阵风锋并给出分类概率,回归是为了能够准确划分出含有阵风锋的候选框,分割是为了在候选框里更精确的勾勒出阵风锋的位置,范围,大小和形态。最后对训练模型的收敛性进行分析,并评估算法的泛化性能。
2. 数据集建设
2.1. 数据集来源及分析
本文所采用的是多普勒天气雷达(CINRAD)在2013~2016四年里河南省各市(洛阳,驻马店,商丘,南阳,郑州,南阳,濮阳,三门峡)采集到的雷达体扫数据,如表2所示,,首先取0.5度仰角层的雷达PPI数据,用matlab将体扫数据生成为雷达反射率因子图集共63800张,图片尺寸为1667 × 1667,如图1。
Table 2. Statistics of radar data distribution and positive samples in Henan province from 2013 to 2016
表2. 2013~2016年河南各地区雷达数据分布及正样本数量统计
2.2. 数据集标注及预处理
将图片尺寸裁剪为1024 × 1024,逐一人工观察对比雷达图集,其中采集到有效阵风锋正样本860张。随后通过labelme工具,以多边形的样式进行手动逐点标注正样本,如图2。并逐一核对,获取json格式的标注数据集,存储标注名称为zff (阵风锋)以及对应的坐标点。
2.3. 数据增强
考虑到训练模型的数据规模需求数量较大,而所采集到的正样本数据量不足,故采用数据增强的方法改善这个问题,利用Data Aug for Object Segmentation中的Data Augment for Label Me方法将图像旋转,裁剪,加噪声后扩充了数据集的数量,如图3、图4,增强了数据的多样性,也增强了算法的鲁棒性,在业务中更能应对复杂情况。适用于Labelme的数据增强方法,可以完全将标签和原图一起增强,不会影响到标记信息的可靠性,增强后现共收集到有效正样本数据集23,777张。

Figure 2. From left to right shows the original image (the red part is the target area) and the marked sample
图2. 从左至右依次为原图(红色部分为目标区域)、标记样例展示

Figure 3. From left to right shows the original image, enhanced Figure 1 (flip up and down), and enhanced Figure 2 (Gaussian noise)
图3. 从左至右依次为原图、增强图一(上下翻转)、增强图二(高斯噪声)

Figure 4. From left to right shows the original image, enhanced Figure 1 (flip up and down + brightness reduction), and enhanced Figure 2 (Gaussian noise)
图4. 从左至右依次为原图、增强图一(上下翻转+降低亮度)、增强图二(高斯噪声)
3. 基于Mask RCNN的阵风锋检测算法
3.1. 模型整体架构
Mask RCNN模型由CNN [6] (卷积神经网络),RCNN(区域卷积神经网络) [7] ,Fast Rcnn [8] (快速卷积神经网络),Faster RCNN(更快的卷积神经网络),再到现在的Mask Rcnn,如图5。Mask Rcnn在2017年被何凯明提出,它的第一大亮点在于在Faster RCNN的基础上,从目标检测 [9] 拓展到了图像分割,从每个目标的边界框精确到了每个目标的像素级分割。Mask RCNN大体框架还是Faster RCNN的框架,可以说在基础特征网络之后又加入了全连接的分割子网,由原来的两个任务(分类+回归)变为了三个任务(分类+回归+分割)。Mask RCNN [10] 是一个两阶段的框架,第一个阶段扫描图像并生成提议(proposals,即有可能包含一个目标的区域),第二阶段分类提议并生成边界框和掩码。Mask RCNN在Faster RCNN中添加一个分支,用于输出二值mask,表示给定像素是否是一个物体的一部分。简而言之,不修改原始Faster RCNN架构,架构中的RoI Pooling选择的特征图和原图的区域没有完全对齐,因为Mask RCNN图像分割任务要求像素级,不像边界框,这样自然会导致不准确。创新点在于用机智地用RoIAlign方法调整RoI Pooling使对齐更准确。RoIAlign用双线性插值得到准确的像素对齐,这样就可以避免RoI Pooling产生的不对齐。当得到了类别的mask后,Mask RCNN用Faster RCNN生成的分类和边界框将他们结合起来,完成精确地分割,效果取得了进一步改进,如表3。
Table 3. Comparison of results on the coo data set for the Mask RCNN algorithm and other algorithms
表3. Mask RCNN算法和其他算法在coco数据集上的结果对比

Figure 5. Overall architecture of the Mask RCNN mode
图5. Mask RCNN模型整体架构
3.2. 特征提取网络

Figure 6. The Resnet-FPN structure
图6. Resnet-FPN结构
Mask Rcnn的第二大亮点则在于基础网络的增强。特征提取网络在RPN之前,采用的是resnet101 [11] +FPN(特征金字塔)。如图一所示,这种结构可以将各个层级的特征进行融合,使其同时具有强语义信息和强空间信息,FPN实际上是一种通用架构,可以结合各种骨架网络使用,比如VGG,ResNet等。Mask RCNN模型中使用了ResNet-FPN网络结构。ResNet-FPN包括3个部分,自下而上连接,自上而下连接和横向连接,如图6所示,下面分别介绍。
1) 自下而上
从下到上路径。可以明显看出,其实就是简单的特征提取过程,和传统的没有区别。具体就是将ResNet作为骨架网络,根据feature map的大小分为5个stage, stage2,stage3,stage4和stage5各自最后一层输出conv2,conv3,conv4和conv5分别定义为C2,C3,C4,C5中的每一层经过一个conv 1x1操作(1 × 1卷积用于降低通道数),无激活函数操作,输出通道全部设置为相同的256通道,然后和上采样的feature map进行加和操作。在融合之后还会再采用3 * 3的卷积核对已经融合的特征进行处理,目的是消除上采样的混叠效应(aliasing effect)。
2) 自上而下和横向连接
自上而下是从最高层开始进行上采样,这里的上采样直接使用的是最近邻上采样,而不是使用反卷积操作,一方面简单,另外一方面可以减少训练参数。横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合。具体就是对C2,C3,C4,C5中的每一层经过一个conv 1x1操作(1 × 1卷积用于降低通道数),无激活函数操作,输出通道全部设置为相同的256通道,然后和上采样的feature map进行加和操作。在融合之后还会再采用3 * 3的卷积核对已经融合的特征进行处理,目的是消除上采样的混叠效应(aliasing effect)。总结一下,ResNet-FPN作为RPN输入的feature map是P2,P3,P4,P5,P6。
3.3. 锚框生成
基于FPN的特征图[P2, P3, P4, P5, P6],介绍下MASKRCNN网络中Anchor锚框的生成,根据源码中介绍的规则,遍历P2到P6这五个特征层,以每个特征图上的每个像素点都生成Anchor锚框,每个像素点生成的锚框根据框的面积相同,设置不同的长宽比率RATIO = [0.5, 1, 2]完成了三种变换,因此每个像素点可生成3个框。Anchor的生成是围绕中心点的,个数等于特征图像素个数。Anchor框的坐标最终须要归一化到0~1之间,即相对输入图像的大小。
Table 4. From left to right, is the feature graph size, number of anchor boxes, step size, and custom anchor frame size
表4. 从左至右依次为特征图大小、锚框数量、步长、自定义锚框大小
如表4所示,由RPN_ANCHOR_SCALES可知,分辨率越大的特征图上RPN_ANCHOR_SCALES反而越小,说明用于检测小目标效果更好,因为其包含的语义信息更多。在此基础上,考虑到阵风锋也是属于小目标范畴,我们将RPN_ANCHOR_SCALES大小相较于原标准缩小1/2来更精确的检测。
3.4. 损失函数
定义多任务的损失:Loss = Lcls (分类) + Lbox (检测) + Lmask (分割)。损失函数是Lcls和Lbox是Faster RCNN中的损失函数,而Lmask则是mask分支中的sigmoid二分类损失。这样做的好处就是将mask损失和分类损失独立开了,互相不影响。
Lcls:基于Softmax函数的交叉熵损失函数,Softmax函数只要是将前向传播计算的得分归一化到0~1之间的概率值,Softmax函数公式:
基于Softmax的交叉熵公式:
Lbox:
SmoothL1函数:
对应的损失函数:
Lmask:对于每一个ROI,mask分支定义一个Km2维的矩阵表示K (类别)个不同的分类对于每一个m * m的区域。对于每一个像素,都是用sigmod函数求交叉熵,得到平均交叉熵误差Lmask。对于每一个ROI,如果检测得到ROI属于哪一个分类,就只使用哪一个分支的交叉熵误差作为误差值进行计算。这样的定义使得我们的网络不需要去区分每一个像素属于哪一类,只需要去区别在这个类当中的不同分别小类。最后可以通过与阈值0.5作比较输出二值mask。这样避免了类间的竞争,将分类的任务交给之前的classification分支。简而言之就是先确定这个RoI是哪个类,然后网络本来是生成了K个类的mask,现在只取其中那个类的mask,然后一个一个像素对应,最后使用平均二值交叉熵损失计算loss:
4. 双维度注意力机制
雷达图原图大小1667 × 1667,阵风锋检测框平均大小约为97 × 68,根据相对尺度定义,目标尺寸的是原图像尺寸大小的0.1,属于小目标范畴。尺度小,分辨率低,形态不一,语义信息匮乏,可利用特征少。在考虑到阵风锋是属于小目标范畴,我们需要立足于小目标检测作出进一步改进;因此在MaskRCNN模型的Resnet残差网络加入SE注意力模块和CBAM注意力模块,希望能更多的注意到阵风锋区域的特征。
4.1. Squeeze-and-Excitation (SE)注意力模块

Figure 7. The identity block module + SE attention mechanism in Resnet
图7. Resnet中的identity block模块+SE注意力机制
如图7所示,在主干网络resnet网络中的identity block模块中打断与最后一个卷积层的连接,加入SE注意力机制,更多的通过SE模块获取通道维度中的特征信息。经过identity block模块最后一层前的卷积操作作为输入特征,维度为(C, H, W)。再通过Squeeze操作,全局平均池化(Global Average Pooling, GAP)将H和W维度的值变为一个值,此时的特征维是(C, 1, 1)。
然后Excitation操作表示两次全连接层,全连接层最后的通道数与特征的通道数相同都为C,最后用Sigmoid限制到[0, 1]的范围。最后融合操作得到精炼后的特征。
4.2. Convolutional Block Attention Module (CBAM)注意力模块

Figure 8. The conv block module + CBAM attention mechanism in Resnet
图8. Resnet中的conv block模块 + CBAM注意力机制
如图8所示,该注意力模块(CBAM),可以在通道和空间维度上进行Attention。其包含两个子模块Channel Attention Module (CAM)和Spatial Attention Module (SAM)。
其中CAM相比SE,只是多了并行的Max Pooling层。增加一种多一种信息编码方式,加强信息全面性。
在SAM分支里,将CAM模块输出的特征图作为本模块的输入特征图。首先做一个基于channel的global max pooling和global average pooling,然后将这2个结果基于channel做concat操作。然后经过一个卷积操作,降维为1个channel。再经过sigmoid生成spatial attention feature。最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。
依然选择resnet的conv block模块在激活层前接入CBAM模块,特征是依次经过了通道注意力模块和空间注意力模块,最后生成的特征为精炼后的特征。CBAM结构其实就是将通道注意力信息和空间注意力信息在一个block结构中进行运用。
5. 识别效果评估和典型个例分析
5.1 效果统计及对比评估
本文基于迁移学习的框架,将数据集以9:1的比例划分训练集和验证集,此外预留100张作为测试集。网络利用预训练权重mask_rcnn_resnet101_atrous_coco来初始化操作,在主干网络结合效果最好的CBAM注意力机制,识别类型修改成1类,输入图像大小由1667 × 1667 resize为1024 × 1024 pixel,由于识别对象仅为一类,IoU阈值改为0.3,RPN的非最大抑制得分阈值设为0,最大候选框的数量设置成300,优化器采用Adam的优化算法,卷积阶段步长设置成16 pixel。初始学习率设为0.0001,用验证集损失函数作为monitor,patience设为3,factor设为0.5。如图9所示,整体训练50个epoch,batchsize设为8。学习率最终下降到0.0000001,损失函数整体趋于平滑的收敛,最终降到了0.007,还是取得了较好的收敛效果,AP值也达到了0.778,精度较高。
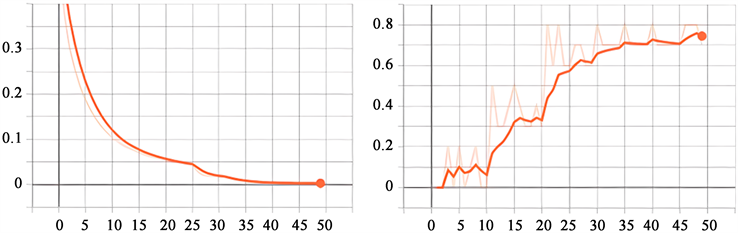
Figure 9. From left to right shows the loss function values of Mask Rcnn + CBATM, and the AP values change with the number of iterative steps
图9. 从左到右依次为Mask Rcnn + CBAM的损失函数值,AP值随着迭代步数的变化
本文在Tensorflow的深度学习框架下,为了评估模型是否出现过拟合情况,本文利用训练好后的模型对100个全新的的CINRAD雷达因子反射率图进行了识别以评估模型的泛化能力。在以往的阵风锋识别算法里(包括传统方法),只有极少数文献将算法应用到了文献自身所用之外的数据,大部分都没有进行新数据的验证和泛化能力评估。本文在测试阶段选用的2013年的8月2日的商丘、合肥地区雷达检测出3个体扫数据;2014年7月1日和7月3日郑州地区,7月4日商丘,地区,雷达共检测出13个体扫数据;2015年7月14日濮阳,7月24日濮阳,8月22日洛阳,8月29日南阳,共检测出11个体扫数据;2016年6月5日南阳,6月13日南阳,7月4日洛阳,7月4日南阳,7月9日南阳,7月9日洛阳,7月26日南阳,8月25日南阳,共检测出13个体扫数据。在100张雷达图中,共有66条阵风锋结果,其中正确识别其中的53条,误判11条且主要由干扰波导致,漏判13条。对batchsize,图片尺寸大小,学习率上,迭代步数等参数上进行微调,以及考虑到阵风锋检测属于目标检测领域,在检测框内又做出了形态分割,所以采取Yolov5 [12] 、Faster RCNN模型和Unet模型,在同一批数据集上进行训练及测试,用来对比评估Mask RCNN模型的实验效果。指标如表5,结合实际中小尺度天气预警现象业务运用,以识别准确率为准绳,综上Mask RCNN及结合CBAM注意力机制还是取得了更好的效果。
Table 5. Mask RCNN and other experimental indicators on the same dataset
表5. Mask RCNN与其他实验指标在同一数据集上对比
5.2. 典型个例分析
如图10所示,这是取自于2016年7月26日南阳地区检测到的阵风锋雷达图,可见图中阵风锋位于雷达图中间偏上部分,由图可见模型成功检测出出阵风锋所在位置并给出判别概率为0.81,并在检测框内较好的分割出阵风锋的具体形态。
6. 总结和展望
本文从CINRAD雷达资料入手,在利用阵风锋通常伴随着强雷暴,并且在雷达反射率因子图上表现为一条窄带回波这一重要特征,结合目标检测和图像分割领域中的Mask RCNN模型,在迁移学习的基础上,进行微调参数及数据接入。在经过50个epoch迭代后,模型取得了较好的拟合效果,训练损失函数最终收敛至0.008。利用50张新数据雷达图对算法进行泛化能力评估,最终识别准确率为80.3%,误判率16.7%,漏判率19.7%,可得到模型泛化能力良好,未出现过拟合情况。
由于数据数量的匮乏,数据质量的控制以及数据人工标记等原因,此算法在训练及测试过程中,仍然存在着漏判或识别不完整以及将干扰波误判为阵风锋等问题。由于各区域地理环境以及雷达指标存在差异性,阵风锋特征单一,因此还需要根据雷达资料的实际情况具体更正。但是随着各地雷达的完善以及样本数据的补充,考虑到深度学习可以通过对新数据的训练不断优化自身参数,在以后的工作中,将继续通过人工在新的雷达数据上进行标记,来加入到数据库中并进一步训练,来不断提升模型的检测和分割能力。
基金项目
四川省科技计划项目(编号:2023YFQ0072,22QYCX0082)。