1. 引言
实体对齐是指对于异构数据源知识图谱中的多种实体,找到物理世界中的同一实体指代对象。随着信息技术的高速发展,网络资源也越来越多,知识图谱中的实体可以从网络百科页面抽取出实体,并对不同来源的实体进行对齐,构建高质量的异构知识图谱。实体对齐就是解决如何从各个来源的数据中找到同一实体,并对进行知识融合的答案。
传统的实体对齐主要是针对句法和实体结构采用相似度对齐的方法 [1] ,利用实体之间的标签或者字符距离映射到同一空间进行相似度对比。Bhamidipaty等研究人员通过人工标注的方法来标记不方便对齐的实体 [2] 。Laccoste等提出了SiGMa方法,该方法的本质是使用了贪心算法的思想,通过对实体属性和机构化信息进行局部搜索来完成实体对齐的任务 [3] 。Scharffe等学者通过匹配模糊实体字符串,对单词的关系使用分类来进行实体对齐 [4] 。Bizer等人通过使用规范的实体语法定义来进行对齐任务 [5] 。这类方法的缺点在于需要根据实体对齐任务有针对性地使用不同的相似度函数,因此会耗费大量的人力资源,同时极大地增加工作量。
随着知识图谱嵌入方法的快速发展,越来越多的研究人员开始使用知识图谱嵌入向量来完成实体对齐任务。这类方法主要思路是将知识图谱中实体和关系嵌入到同一个低维度的向量空间,并在该空间中通过向量来计算相似度系数 [6] [7] [8] 。翻译距离模型TransE首先被提出用于知识图谱的嵌入表达任务中,其表达方式是将每一个知识图谱三元组都表达成头实体向量和关系向量向尾实体向量的映射,但是该模型难以处理各种错综复杂的关系映射。于是,研究人员陆续提出一系列的翻译距离模型来进行改进 [7] 。IEAJKE模型则是利用共同嵌入的方式来进行对齐后再用迭代训练优化模型,其目的在于增强模型的实体对齐效果 [8] 。Guan等学者提出了SEEA模型,该模型使用自学习的方式来进行实体对齐 [9] 。Sun和其他学者建立模型利用迭代的方式进行实体对齐,把实体对齐任务变成分类任务进行求解 [10] 。Sun等人为了对多种特征进行利用,提出了一种实体对齐模型JAPE,该模型从知识图谱的结构嵌入方式和属性嵌入方式这两个两方面来学习实体特征,进一步优化实体对齐的准确率 [11] 。AttrE模型也是以知识图谱嵌入向量为基础,提出了一种融合实体结构信息与属性信息的方法 [12] 。He等学者使用属性三元组来实现实体对齐与属性对齐的信息交互,从而产生大量优质对齐实体对 [13] 。这说明实体的属性信息包含了很多未被挖掘的内容,但这些方法仍然不能充分地利用属性,知识图谱嵌入向量中还存在很多深层次特征,值得研究学者进一步研究。
2. 研究动机
RDGCN (Relation-Aware Entity Alignment for Heterogeneous Knowledge Graphs)基于关系感知双图卷机网络主要是通过构造对偶图来实现以关系作为顶点的对偶关系图,并通过对偶注意力机制来捕获原始的知识图谱和关系对偶图的之间的相互关系,然后通过多层的图神经网络来捕获邻居顶点的结构信息,增强感受野,然后再对通过最终表示结构来判断实体对中两个实体的相似度。
RDGCN使用关系对偶图的目标是为了捕捉实体之间的关系表示,通过以关系为顶点的对偶图通过对偶注意力机制来加强实体对齐的可靠性,并通过对偶关系图的关系注意力机制和原始图的图注意力机制来共同加强关系结构的特征表达,最后将融入关系注意力机制的实体表达送入到多层的图卷积神经网络中,通过图卷积对齐的思想实现实体对齐,因此RDGCN模型是属于实体对齐分类中的基于图神经网络模型的实体对齐算法,其本质还是使用了图神经网络算法模型来进行实体对齐,并在此基础上通过对偶关系图和注意力机制捕获关系结构的表达。

Figure 1. Isomorphic entity alignment schematic
图1. 同构实体对齐示意图
因此本文在分析RDGCN模型时,实体对齐主要考虑在图卷积神经网络中实体嵌入向量的表达,如图1所示是多个需要待对齐的实体对,假设根据初始化种子条件知道,顶点A的实体与顶点a的实体已经对齐,顶点B的实体与顶点b的实体已经对齐和顶点C的实体与顶点c的实体已经对齐,用向量来表示就是
,
,
,其中
代表顶点A在经过图卷积聚合前的向量表示,而
代表顶点A在经过一次图卷积聚合操作之后的向量表示,由于通过训练种子得到已经对齐的实体对,因此也可以知道
,
,
,根据图神经网络的传播公式,如公式(1)可知
(1)
其中
是邻接矩阵和单位矩阵的和矩阵,
是度矩阵,W是权重矩阵,因此我们可以通过图神经网络的传播公式可以推断出各个层次间的实体向量表示关系,其中可知
,
,同理对齐实体中也存在
,
,因为实体对(A, a),(B, b)和(D, d)已经完成了对齐,因此可知实体E和实体e应该对齐,同时可知实体C和实体c应该完成对齐,因此可以通过这个实例看出,在部分实体已经对齐的情况下,如果待对齐的实体对邻居顶点的关系结构是同构的,那么可以使用图神经网络的方法来完成知识图谱的实体对齐。
同理,我们可以推断出,假如待对齐的实体对之间的邻居顶点关系图不是同构的,是否可以和上述方式一样的推断出实体对齐的实体对,如图2所示:
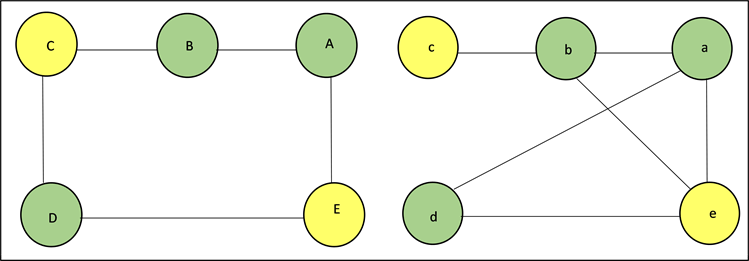
Figure 2. Heterogeneous entity alignment schematic
图2. 异构实体对齐示意图
当前我们已经部分实体对已经对齐,实体A,实体B和实体D与异构知识图实体a,实体b和实体d已经对齐,但是由于此时知识图是异构的,因此我们可以通过公式发现
,
,同理可以通过已对齐的实体知道
,
,
和经过一次图卷积后的向量关系
,
,
,不难得出异构知识图谱中实体E和实体e的实体对齐关系是相等的,但是对于待对齐实体对(C, c)就很难判断实体是否对齐,已知
,而此时
,通过实体对齐已知关系,我们并不能得出
,因此直观上来看并不能直接得到实体对齐的信息,虽然因为实体对的邻居结构相似,向量表示的相似度较高,可能最后通过结果计算可以判断出实体对(C, c)存在一定的相似度,但依然可以证明,只通过关系结构相似度来判断实体对齐存在片面性不足之处。
因此本文考虑使用知识图谱中的属性结构来辅助关系结构对实体对齐进行判断。但是使用属性信息又会存在一定的矛盾和冲突,常见的属性三元组一般表示为(实体名称,属性,属性值),但是知识图谱的属性值描述可能存在一定的差异性,因为属性值一般是使用字符类型进行存储的,一般是没有固定的格式规范的,例如(墨石公园景区,门票价格,60元起)和(墨石公园,门票价格,成人票60元),从中可以看出来虽然这两个属性三元组描述的事实约定是相同的,但是属性值不经过一定的约束和格式化,是无法进行使用的,因此本文考虑只使用属性信息来进行编码判断,不使用属性值进行约束。即构造属性图,两个实体之间不考虑关系之间的结构联系,只考虑属性之间的联系,两个实体之间如果有相同的属性,则在两个实体之间存在一条属性边,这条属性边的名称就是该属性的名称。如图2所示,使用到前面的关系结构图神经网络传播异构表示中,我们可以知道如果只使用关系结构很难知道实体C和实体c的实体对齐关系,但是我们引入了属性结构提取特征,可以提取到实体C和实体c中存在大量相同的属性,因此实体C和实体c的属性表征向量的相似度很高,并结合关系结构向量表征的相似度计算,就可以大大提高异构实体对的实体对齐相似度。
3. 本文算法
3.1. 算法整体框架
知识图谱
是一个有向图,其中包括所有实体集合E、所有关系集合R、所有三元组集合T、所有实体属性A以及对应的属性值V。给定源知识图谱
,目标知识图谱
以及已对齐实体对种子
,其中
代表实体u和实体v等价,也就是两个实体对指向的是现实世界中同一个物体,实体对齐任务的主要目的就是找到两个知识图谱中等价的实体对。如图3所示:
本文根据RDGCN模型中没有对实体属性信息进行利用这一不足之处,提出了基于结合属性信息的对偶图实体对齐算法(Alignment Algorithm of Dual Graph Entities Combining Attribute Information, DAI)。DAI算法使用知识图谱的对偶图构造出关系图,关系图的顶点表示关系,通过多个注意力机制使得关系对偶图和原知识图谱进行信息的交换,然后通过带有高速路神经网络门控的双层GCN来合并邻居结点的结构信息,扩大感受野。DAI算法不仅使用对偶图来对关系信息进行提取,还使用了图卷积神经网络对实体的属性进行分析,将属性作为节点来及进行分析,得到属性结构信息的嵌入向量,最后再将关系嵌入向量和属性嵌入向量计算距离得分函数,得到实体是否一致的结果。该算法模型可以分为三个部分:1) 对偶图关系结构提取模块,主要是通过对偶图和注意力机制来计算实体的关系嵌入向量。2) 图卷积属性结构提取模块,主要是通过图卷积神经网络来计算实体的属性嵌入向量。3) 联合对齐模块,主要是通过关系提取模块和属性提取模块得到的结果来计算实体是否对齐。算法的模型示意图如图4所示。
3.2. 对偶图关系结构提取模块
对偶图关系结构提取模块主要是通过构造对偶关系图,然后通过注意力机制将关系图和原知识图谱进行信息交换,最后通过RGCN网络获取相邻节点的信息,并对干扰噪声信息过滤,将邻居信息聚合给实体向量。构造对偶关系的过程就是将源知识图谱
和目标知识图谱
放在一起作为输入知识图谱
,其中
的实体和关系就是
和
的实体和关系的总和。构造对偶关系图
时,应该遵守以下规则:
中的每一个关系在对偶图
中都有一个节点进行表示,因此
的节点集合就是
的关系集合。
如果在
中存在两种关系
和
共享同一个实体,那么在对偶图
中应该构建一条边
来连接这两个关系节点,其中这条边
的权重值
计算公式如(2)~(4),其中
和
分别对应的是关系
的头实体集合和尾实体集合。
(2)
(3)
(4)
构造得到对偶图
后,与原知识图谱
一起作为输入数据,进行注意力机制的信息交换。在DAI模型算法中,主要使用了两种注意力机制算法,分别是针对对偶图的对偶注意力机制和针对知识图谱的原始注意力机制。
1) 对偶注意力机制
将关系信息引入对偶关系图中,把关系信息和原始图相结合进行关系特征描述,并采用统一的向量来进行表示。将图注意力机制用于选代地得到对偶关系图与原始图中节点间的向量表示,在该向量表示中注意力机制有利于促进关系图与对偶图之间的信息交互,其中包括两层注意力机制,分别是对偶注意力层与原始注意力层。
其中对偶注意力机制首先构造
为输入知识图谱的对偶关系顶点表示矩阵,其中矩阵中的每一行都对应着对偶关系图中的一个关系顶点。利用原始注意力机制生成的节点向量特征来计算对偶注意力分数
(5)
(6)
在公式可以看到,
表示对偶关系顶点
处结合注意力分数的输出向量表示,
表示在顶点
的对偶关系表示向量;
表示顶点
的所有领域顶点集合;
表示对偶注意力机制的权重值,
表示为全连接层,
是指非线性激活函数ReLU,
指的是非线性激活函数Leaky ReLU;
代表的是从原始注意力层获取的关系
的嵌入向量表现。通过对知识图谱中的平均头实体和尾实体近似表示
的关系为
,
由原始注意力层求得,其公式如(7)所示:
(7)
和
指的是从原始注意力层中关系
第k个头节点和第l个尾节点的输出向量表示。
2) 原始注意力机制
本层是对原始知识图中应用图注意力机制,根据对偶关系图中的关系顶点表示来计算原始注意力得分
,其目的是通过对偶注意力层的关系向量表示来计算原始实体图顶点嵌入向量表示,如公式(8)所示。输入原始知识图中顶点的向量表示矩阵
,原始知识图中实体
的嵌入向量表示
的计算方式如公式(9)所示:
(8)
(9)
其中,
代表的是对偶关系图中获得的实体
与实体
之间的关系
的对偶表示,
代表原始知识图中实体
的所有领域节点的集合,
则是表示全连接层,
是原始注意力层的非线性激活函数。在该模型中,原始节点的初始表示向量矩阵是通过实体名来进行初始化的,这为实体对齐的有效性提供了重要依据。因此,实体嵌入向量的表示是通过叠加原始注意力层的输出向量和初始向量表示来进行修改的。
3) 合并结构信息
从GCN层的输出中收集最终的实体表示向量
,通过实体对之间的对齐距离作为得分函数,其公式如(10)所示,
(10)
其中,
表示知识图谱中实体
的嵌入向量表示,
表示知识图谱中实体
的嵌入向量表示,
则是代表两个实体
和
在
范数规则空间的距离。
3.3. 图卷积属性结构提取模块
属性结构提取模块是根据图卷积神经网络进行实体对齐的思想将实体属性进行单独提取分析。属性结构嵌入主要使用图卷积神经网络模型,构造实体属性矩阵,实体之间不考虑关系边的连接,将实体当作顶点,从而形成以顶点为实体,使用属性边连接起来的属性图,如果两个实体拥有同一个属性,那么这两个实体之间就有边进行连接,连接边称为属性边。因此在属性结构嵌入模块中只选用属性,不考虑属性值的影响,同时排除实体和实体之间的关系连接,因为实体之间的关系结构已经在关系结构模块进行了提取,因此在属性提取模块里,连接的是实体和属性的关系,实体相互间是没有关系边进行连接的,实体所有属性边的总数作为属性矩阵的维度。属性提取结构采用和关系结构相同的卷积过程,属性模块第一层的输入,用随机初始化的节点向量,其卷积过程如公式(11)所示,
(11)
其中,
代表属性图的结构信息,
代表l层的特征向量;
表示所有属性的数量;下标a表示属性结构的嵌入模块,
是l层的权重矩阵。
3.4. 联合对齐模块
通过上述两个提取模块计算出知识图谱的关系相似度,也计算完属性结构相似度后,还要合并整体计算出两个实体之间的相似度信息,首先计算出实体关系结构中实体对齐的结果,再计算实体属性结构中实体对齐的结果,分别得到两个提取模块的实体相似性后,然后通过对两个提取模块中实体相似度加权求和的方式,调节权重占比参数,以此设置关系结构与属性结构的比重大小,最后得到待对齐实体对之间的相似度大小,往往在实际数据训练中,因为属性边相似的实体会更多一些,因此属性提取相似度权重占比一般会比关系提取相似度权重占比小一些。公式(12)定义了实体相似度的得分函数,如下所示
(12)
其中,
,代表计算实体之间的距离大小,
和
分别表示实体对的关系嵌入向量和属性嵌入向量,
和
分别表示模型中关系嵌入向量和属性嵌入向量的维度大小。
和
是平衡两种嵌入方式相似度的重要超参数。
4. 实验与分析
4.1. 数据集介绍
为了本文在实体对齐对比实验中使用的是DBP15K数据集(见表1),该数据集是由南京大学提出的一个用于实体对齐的数据集,包含多种不同翻译语言的知识图谱对齐实例,该数据集是从DBpedia的知识图谱中抽取出来的一个子集,DBpedia是一个大规模的维基百科的语义网络,它包含着不同语言中丰富的语义信息,不同语言之间的对应都有链接。DBpedia的中文、英文、日文和法文版本的子集是通过一定选择规则获取的。

Table 1. Data set DBP15K information
表1. 数据集DBP15K信息
4.2. 实验结果与分析
4.2.1. 预测结果对比
实验结果如表2所示,可以明显看出来经过改进后的结合属性信息的对偶图实体对齐算法DAI提升效果较为明显。
Table 2. Comparison results analysis of different entity alignment methods
表2. 不同实体对齐方法对比结果分析
可以从表中的结果看到使用了属性结构提取特征的对偶图实体对齐算法DAI相比于原来的RDGCN算法有了不错的提升效果,由于属性提取特征采用的是属性名称的方式来对比的,因此实体之间的类型种类越多,不同实体之间的包含属性差别越大,属性提取的比较效果越好。JAPE模型同样也是使用关系结构特征和属性结构特征的模型,在关系结构特征提取中使用的是TransE模型来进行判别,而属性结构特征是使用Skip-gram模型,来获取不同属性之间的相关性。而GCN-Align模型是使用图神经网络来使用属性特征和关系特征进行实体对齐的模型,RDGCN是使用对偶图来构造关系特征图的,并使用注意力价值加强关系特征提取的模型。图5是上述实体对齐方法的Hits@K可视化对比结果,主要是取了Hits@10和Hits@50的结果进行对比。
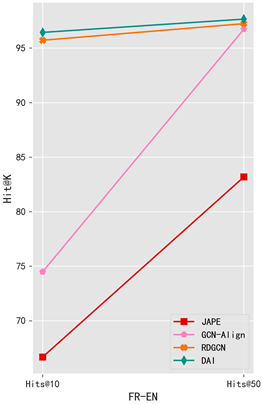
Figure 5. Experimental results of Hits@K comparison with different modeling approaches
图5. 不同模型方法的Hits@K对比实验结果

Figure 6. Experimental results of MRR comparison of different modeling approaches
图6. 不同模型方法的MRR对比实验结果
可以从可视化的对比实验中看到改进后的DAI算法比RDGCN算法在模型中有不错的提升,尤其是在Hits@10的时候,提升程度较大;Hits@50达到了一个瓶颈,提升程度并不是特别明显,但相较于原算法和其他的属性提取算法的结果仍有着不错的提升效果。
通过不同方法的MRR指标可视化展示,见图6可知,DAI相比较于ORGCN在平均倒数秩上的差别不大,有略微提升,可能主要还是因为该数据集中的实体属性区分不大,多个不同实体中包含多种同样的属性关系,综合总体来分析可以看出结合属性信息的对偶图实体对齐算法具有不错的改进效果。
4.2.2. 超参数选择实验
本文将结合属性信息的对偶图实体对齐算法与其他同类型的算法进行对比实验,设置关系对偶注意力层和原始注意力迭代交互两轮,即进行两轮对偶关系信息的提取。第一轮交互主要是提取关系注意力的信息结构,减少原始注意力机制的叠加,因此混合向量权重参数为0.1,第二轮交互增加原始注意力机制的占比,混合向量权重参数为0.3。嵌入向量的维度为300,学习率为0.003,训练迭代次数为600次,关系结构提取参数为0.9,属性结构提取参数为0.1。
5. 发展与展望
本文使用的是基于属性增强的对偶图实体对齐算法,该算法通过属性增强信息能够辅助关系知识图谱的实体对齐,但是本算法只使用了实体的属性类型,没有使用属性值的具体信息,因为实体的属性值基本都是字符信息的输入,没有一定的规范化格式,在算法中不太好直接使用,以后的研究中希望能够将属性值的信息进行规范化,并与属性类型结合起来,共同辅助关系知识图谱的实体对齐。