1. 引言
全国出现多次疫情爆发事件,本文以长春市为例,疫情期间的蔬菜物资发放成为焦点问题,发放方式不当很有可能造成二次传播。为了利于以后的疫情防控工作,本文使用高斯插值和K-means算法对疫情期间物资的科学管理方式对疫情的影响进行探索,实现了对生活物资投放点数量,位置的优化,可以为以后大规模封控情况下居民物资有序发放提供参考。
2. 模型的建立与求解
本文用到的符号及含义如表1所示:
2.1. 高斯拟合
2.1.1. 高斯拟合概述
高斯拟合是使用形如
(1)
的高斯函数对数据点进行函数逼近的拟合方法,跟多项式拟合类比起来,多项式拟合使用的是幂函数,高斯拟合使用的是高斯函数系。上式(1)中:
为归一化系数,
为函数最大值位置,
为函数的幅宽度。
2.1.2. 高斯拟合结果
对长春市2022年3月26日之前未发放蔬菜包时的感染人数使用Matlab拟合工具箱进行高斯拟合,拟合后的函数为:
(2)
其中函数的各个系数如下所示:
利用拟合出的函数进行反预测,画出拟合后的函数图像,并画出长春市疫情开始时实际感染人数图像,用于二者对比,如下图1所示:
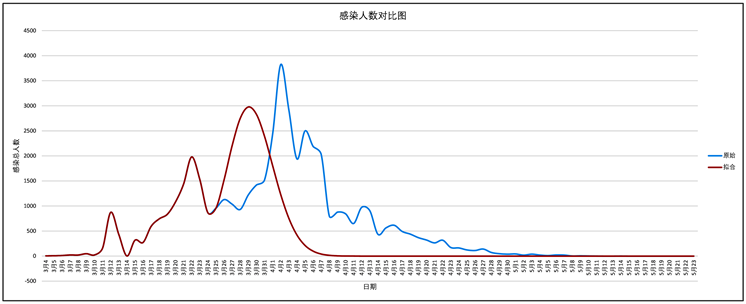
Figure 1. Comparison of the total number of infections
图1. 感染总人数对比图
红色线为通过高斯插值拟合出的函数曲线,蓝色线为题目所给的实际数据绘制的曲线。由对比图可看出,拟合函数的预测数据的走势与原数据的走势相同,拟合结果具有较高的正确性。由于发放蔬菜包导致人员之间的交流,发生了交叉感染,疫情持续时间增长,感染人员数量的清零时间明显延后,感染人员的最高数值从2976增加至3823,感染人数到达峰值的时间延后。发放蔬菜包时的人员流动导致疫情周期变长,对疫情有着一定的不良影响。
2.2. 算法概述
2.2.1. K-Means算法概述
K-means算法是硬聚类算法,是典型的基于原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则。K-means算法以欧式距离作为相似度测度,它是求对应某一初始聚类中心向量V最优分类,使得评价指标J最小。算法采用误差平方和准则函数作为聚类准则函数。K-means核心思想为:由用户指定K个初始质心(initial centroids),作为聚类的类别(cluster),重复迭代直至算法收敛。即以空间中K个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果 [1] 。由于整个长春市划分很多区,所有区的分布图如图2所示:
Figure 2. Distribution of districts in Changchun
图2. 长春市各个区分布图
2.2.2. MST算法概述
多生成树(MST)是把IEEE802.1w的快速生成树(RST)算法扩展而得到的。采用多生成树,能够通过干道(trunks)建立多个生成树,关联VLANs到相关的生成树进程,每个生成树进程具备单独于其他进程的拓扑结构;MST提供了多个数据转发路径和负载均衡,提高了网络容错能力,因为一个进程的故障不会影响其他进程。
MST性质:假设
是一个连通网,U是顶点集V的一个非空子集。若
是一条具有最小权值(代价)的边,其中
,
,则必存在一颗包含边
的最小生成树。
本题以距离最小为目标建立模型
,其中
为i投放点到j投放点的距离。Prim算法过程为:假设
是连通图,TE是N上最小生成树中边的集合。算法从
,
开始,重复执行下述操作:在所有
,
的边
中找一条代价最小的边
并入集合TE,同时
并入U,直至
为止。此时TE中必有n-1条边,则
为N的最小生成树。
2.2.3. K-Means聚类结果
这里只以朝阳区为例,主要使用K-means算法对朝阳区的小区进行分簇,假设分为4簇 [2] ,随机在样本集
中随机选取四个样本,求出最优的均值向量(质心)。以朝阳区为例,首先需要画出朝阳区的小区散点图(其余小区的散点图以及分类图随附件发送),使用贪心策略寻找最优质心,算法描述如下 [3] :
根据上述算法求解出朝阳区最优的质心坐标,这四个质心坐标将朝阳区的所有小区分成四个簇,每个簇的质心与这个簇内的所有小区坐标距离最小,可以当作物资发放点。如下图3所示:
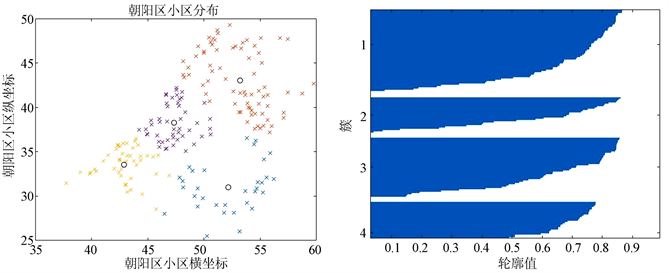
Figure 3. Results of 4 clusters and contour values of clustering effect in Chaoyang District
图3. 朝阳区小区分4簇结果及分簇效果轮廓值
从上图3可以看出,将朝阳区分成四簇,从上图3的轮廓值图可以看出分簇的效果较好。当分为6簇,8簇时,质心坐标及其轮廓值如下图4,图5所示:
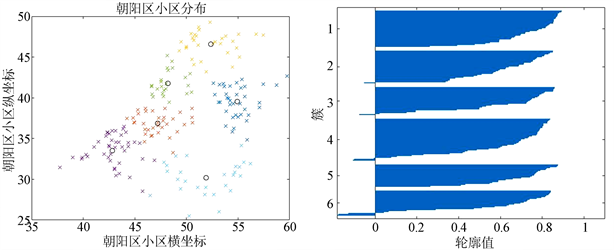
Figure 4. 6-cluster results and contour values of clustering effect in Chaoyang District
图4. 朝阳区小区分6簇结果及分簇效果轮廓值
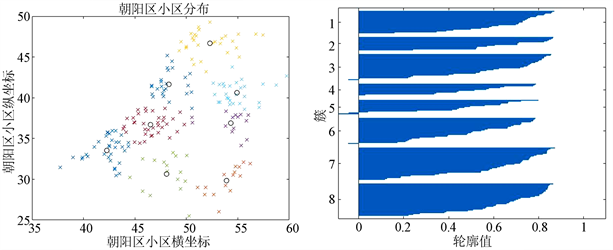
Figure 5. 8-cluster results and contour values of clustering effect in Chaoyang District
图5. 朝阳区小区分8簇结果及分簇效果轮廓值
根据上图4,图5可以看出,当分为4簇和6簇时,轮廓值较高,最大值都在0.85以上,表示分簇的效果比较好,当分为8簇,轮廓值在0.85以下,分簇效果不好 [4] ,所以本文各区分簇都以4簇为准。当分为4簇时,每个质心管理的小区数目太多,可以将分好的4簇基础上在利用K-means算法进行聚类,k值选择为6,结果如下图6所示:
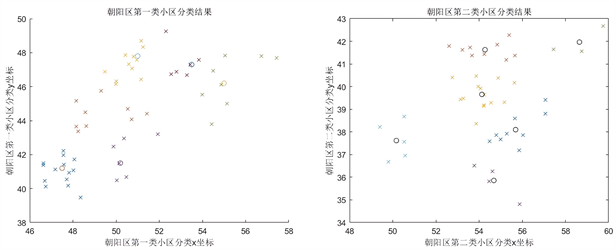
Figure 6. Re-clustering and center of mass of the first and second type of cells in Chaoyang District
图6. 朝阳区第一类,第二类小区再次分簇及质心示意图
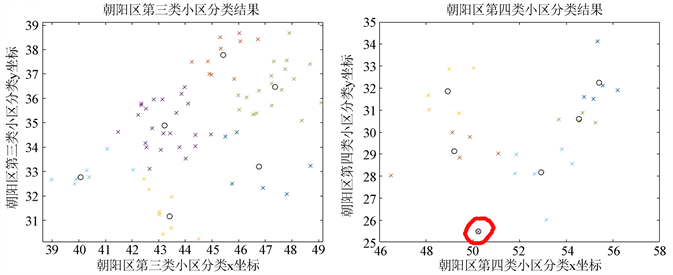
Figure 7. Re-clustering and center of mass of type III and type IV cells in Chaoyang District
图7. 朝阳区第三类,第四类小区再次分簇及质心示意图
当在朝阳区第一次分簇的基础上再次分簇时,在图7中出现了单个小区为一簇的情况,如标记所示,这是K-means算法本身的局限性导致的,解决这种问题的方法可以改变K值来增加或者减少分簇情况或者多次运行程序来解决 [5] 。利用K-means算法对长春市朝阳区所有小区进行分簇后,得到簇心坐标,可作为合理的蔬菜投放点,簇心坐标和其管理的小区坐标如下表2所示:

Table 2. Coordinates of vegetable drop-off locations in Chaoyang District
表2. 朝阳区蔬菜投放位置坐标
利用K-means算法求解出最佳的物资投放点位置,结合长春市朝阳区各个小区坐标和长春市道路坐标发现,使用K-means算法得出的质心坐标并不存在与小区坐标冲突,并且大部分都靠近道路附近,那些不靠近道路坐标的质心点可以在附近择优选择最近的道路作为物资投放点。
根据上述得出的质心坐标,结合MST算法,以各个投放点之间的距离为目标,建立投放点之间最小
距离为数学模型
,(其中
为i投放点到j投放点的距离)求解出的最佳运输路线结果如图8
所示:
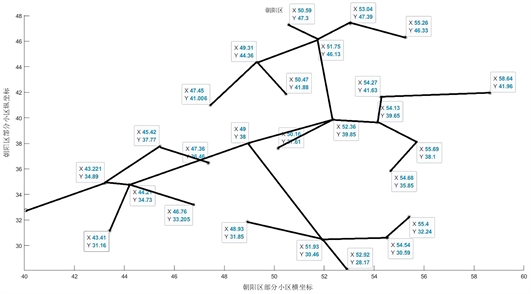
Figure 8. Map of optimal material delivery in Chaoyang District
图8. 朝阳区最佳物资输送图
为了验证得到的模型的普适性,以长春市其他城区小区坐标为例,下面以长春市宽城区为例,利用上述的模型得出物资投放点坐标,如表3所示,并利用MST算法得出物资运输路线图,如图9所示。
Table 3. Coordinates of vegetable placement locations in Kuan Cheng District
表3. 宽城区蔬菜投放位置坐标
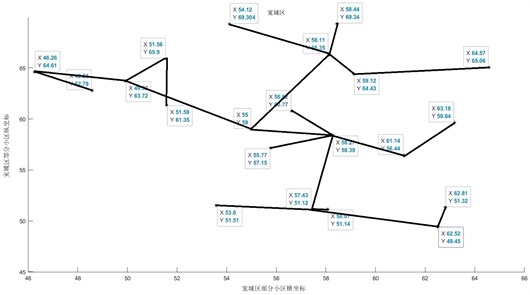
Figure 9. Map of the best material transport in Kuancheng District
图9. 宽城区最佳物资输送图
从上述求出的质心坐标并结合宽城区的小区坐标以及长春市交通道路坐标,各个质心坐标与宽城区的小区坐标并不存在冲突,通过K-means得出的质心坐标和MST相结合,画出物资配送路线图,可作为以后发生困难时的运送物资参考路线。
3. 总结
本文以长春市朝阳区为例,鉴于疫情期间的蔬菜物资发放点不合理,发放方式不当容易造成二次传播的问题,首先采用高斯拟合的方法,对假设如果不统一发放蔬菜包的问题进行评价,通过最后拟合出的函数可以看出,疫情期间蔬菜物资发放点不合理,发放方式不当的问题确实加速了病毒的传播。然后以朝阳区为例,对物资投放点不合理的问题,采用K-means算法对朝阳区所有小区进行分簇,得到的簇心坐标可以作为理论上的生活物资投放点,并结合MST算法,得出物资运输路线图。为了得出模型的普适性,本来以长春市宽城区为例,通过上述模型,同样得出了较为合理的物资投放点坐标以及物资运输路线,为以后发生类似情况时,提供了参考。