1. 引言
交通标识识别是智能驾驶感知系统中的基础功能之一,对于路径规划以及行车安全具有重要作用,帮助智能驾驶汽车在行驶阶段做出准确及时的决策。在实车行驶过程中,视觉感知易受到光照环境、天气变化等条件的影响,出现漏检误检现象,无法满足智能驾驶安全需求 [1] 。随着深度学习的发展,网络层越深,参数量也越多,图像识别与目标检测得到了进一步的发展。现阶段,目标检测算法主要分为两大类,基于候选区域生成的一阶段方法和基于回归的二阶段方法。二阶段算法以Faster R-CNN为主,检测精度高,但检测速度慢,实时性较差。一阶段算法以YOLO系列和SSD算法为代表 [2] 。最新的YOLOv7-tiny模型,参数以及运算量都较小,实时性好,且有较高的检测精度,适用于低算力平台的智能驾驶机车,满足低阶的L2级别智能驾驶功能,因此本文将基于YOLOv7-tiny轻量级目标检测算法作为框架,增加小目标检测层,加强对小目标的检测能力。同时,引入TAM注意力机制,增加特征提取过程中网络的跨维度信息交互能力。
2. YOLOv7-Tiny算法介绍
YOLOv7-tiny是YOLOv7 [3] 的轻量模型,主要面向边缘GPU架构,相比YOLOv7,它的网络结构相对简单,计算量小,因此实时性出色,并且降低了对硬件的要求,更适用于移动端设备。YOLOv7-tiny的具体网络结构如图1所示。
3. YOLOv7-Tiny算法改进
3.1. 增加小目标检测层
深入分析YOLOv7-tiny目标检测算法,并针对应用于交通标志检测进行改进。交通标识检测效果不好的一个原因是目标样本的尺寸较小,较深的特征层无法学习到小目标的特征信息,因此提出增加小目标检测层对浅层特征图与深层特征图拼接后进行检测 [4] 。首先,在主干网络第3层就开始特征加强,获得尺寸为160 × 160的大尺寸特征图,以更好地实现小目标检测。其次,在颈部加强特征提取网络中增加一次上采样,同时增加一次特征融合,丰富小目标的图像信息。最后,针对主干网络第三层的特征提取层,增加目标检测头,在160 × 160尺寸的图像上,可以减少小目标的信息损失,提升检测效果。同时,
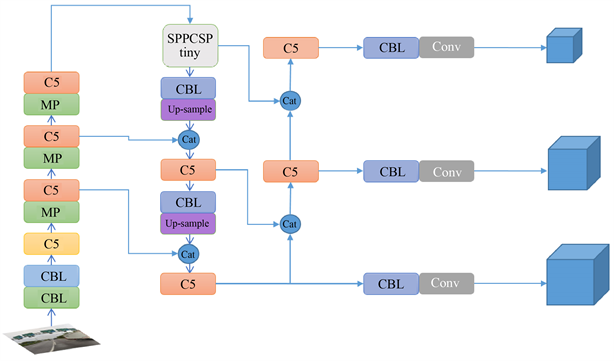
Figure 1. Diagram of YOLOv7-tiny network structure
图1. YOLOv7-tiny网络结构图
添加针对小目标的目标框,原小目标框参数为[10, 13, 16, 30, 33, 23],检测头数量为三个,改进后,检测头数量为四个,小目标框参数为[5, 6, 8, 14, 15, 11],可以让网络更加关注小目标的检测,进而提升检测效果。具体改进后的网络结构图,可参见图4。
3.2. 引入TAM注意力机制
TAM (Triplet Attention Module) [5] 是一种通过使用三分支结构跨维度交互来计算注意力权重的方法,TAM三重注意力机制将输入的张量进行旋转操作,然后使用残差结构建立不同维度之间的关系,同时以较小的计算量对通道信息以及空间信息进行编码。相对于通道注意力机制或空间注意力机制,TAM三重注意力机制可以很好地进行跨通道信息的交互,从而消除了通道和权重之间的间接对应,因此应用于目标检测模型中,有显著的性能改进。具体三分支结构如下图2所示。

Figure 2. Illustration of three branches in triplet attention
图2. 三重注意力的三分支说明
如上图2所示,Triplet Attention主要包含3个分支,图中最下方的分支不进行旋转操作,捕获空间维度H和W的关系信息,使用残差结构,进行空间注意力权重计算,最后使用Sigmoid函数进行激活操作。中间的分支,保持空间维度W不变,进行旋转操作,捕获通道C维度和空间维度H的信息,进行通道交互。最上方的分支,则是捕获通道C维度与空间维度W的跨通道交互信息。最后将三分支进行单元和平均操作。
Z-Pool通过将平均池化和最大池化特征连接,使得张量的第0维减少到2维。这使得该层能够保留实际张量的信息,同时缩小其深度,从而进一步地减少计算量。具体公式如下所示:
(1)
其中,0 d是进行最大池化和平均池化操作的第0维。例如,一个形状张量(C × H × W)的Z-Pool结果是一个形状张量(2 × H × W)。
具体的TAM网络结构如下图3所示。右侧第一分支不进行输入张量旋转操作,首先输入张量经过Z-Pool,进行通道池化操作,随后进行7 × 7的卷积操作,随后进行BatchNorm归一化操作,最后使用Sigmoid激活函数生成空间注意力权重。相对于右侧第一分支,另外两分支首先进行Permute旋转操作,再进行后续的跨通道交互操作。
3.3. 改进后的YOLOv7-Tiny网络结构
在原YOLOv7-tiny主干特征提取网络增加一层浅层特征层,针对增加的浅层特征层,在加强特征提取网络中增加一次上采样操作,并与这一特征层进行特征融合操作,获得160 × 160的特征图。同时,针对增加的浅层特征层,增加了160 × 160的目标检测头。在主干特征提取网路中提取出的四个有效特征层上增加TAM三重注意力机制,以提升检测精度,具体网络结构如下图4所示。
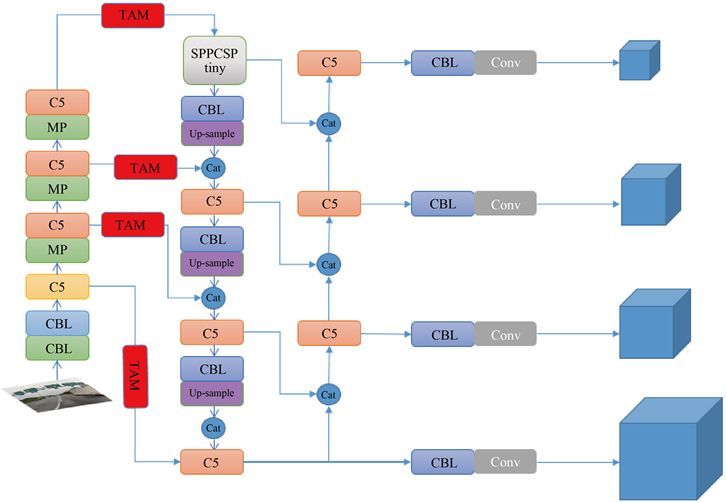
Figure 4. Diagram of YOLOv7-tiny network structure after improvement
图4. 改进后的YOLOv7-tiny网络结构图
4. 实验结果及分析
4.1. TT100K数据集
本文的实验采用交通标志数据集Tsinghua-Tencent 100K (简称TT100K) [6] ,该数据集包含221个类别,26349个目标,图像尺寸为2048 × 2048。该数据集存在两个问题:首先目标尺度小的问题,目标在图像中所占比例较小;其次就是类别不均衡的问题,有的类别多达两千多个,而有的只有几个、十几个。这些都对检测和识别带来了很大挑战。这里选择221个类别中数量最多的45个类别进行实验,并按照6:2:2的比例重新划分训练集验证集测试集 [7] 。
4.2. 实验环境及参数设置
实验环境:操作系统Ubuntu 20.04,深度学习框架Pytorch 1.10.0 + Cuda 11.3 + cudnn 8200,CPU为AMD EPYC 7642,内存80 GB;GPU为单块NVIDIA GeForce RTX 3090,显存为24 GB。
参数设置:图片输入大小640 × 640,训练时采用Adam优化器,初始学习率0.001,采用余弦退火衰减策略调整学习率,动量大小0.937,权重衰减系数为0.0005,批处理尺寸(Batchsize)设为64,迭代300个epoch。
4.2.1. 实验结果
改进后的YOLOv7-tiny模型训练结果如下,准确率(Precision)为0.831,置信度为0时的召回率(Recall)为0.802,平均精度值(mAP)为0.842,训练结果如下图5所示。
由于原图像尺寸为2048 × 2048,图幅较大,交通标识所占尺寸较小,为便于更加直观对比,截取原始图片中交通标识部分进行对比分析。由于复杂路口交通标识密集,目标框重叠,因此在模型进行检测过程中,置信度值设置为0.5,因此置信度值低于0.5的目标框将不再显示。图6展示了模型在复杂路口检测结果,图7展示了在高速路段的检测结果,详细对比可参照下方图片。从对比图片中可清晰看出,改进后的模型检测精度有显著提升。
4.2.2. 实验对比
为验证算法模型的可靠性以及准确性,本文采用平均精度值mAP作为评价标准。平均精度值mAP为模型对各类别检测精度AP的平均值,代表模型的整体检测精度 [8] 。首先与相近参数量及计算量的YOLOv5s进行对比分析。由表1可见,YOLOv7-tiny相对于YOLOv5s对于交通标识的检测平均精度提升了接近2%。改进后的算法模型,相对于YOLOv5s平均检测精度提升了6.13%,相对于YOLOv7-tiny提升了4.21%,对于交通标识这类小目标有显著改进。
根据表1中数据对比,以及图8的结果展示,YOLOv7-tiny轻量级目标检测模型以及改进后的模型显著提升了交通标识类的小目标检测精确度。

Figure 6. Comparison of detection results at complex intersection
图6. 复杂路口检测结果对比

Figure 7. Comparison of detection results in highway
图7. 高速路段检测结果对比
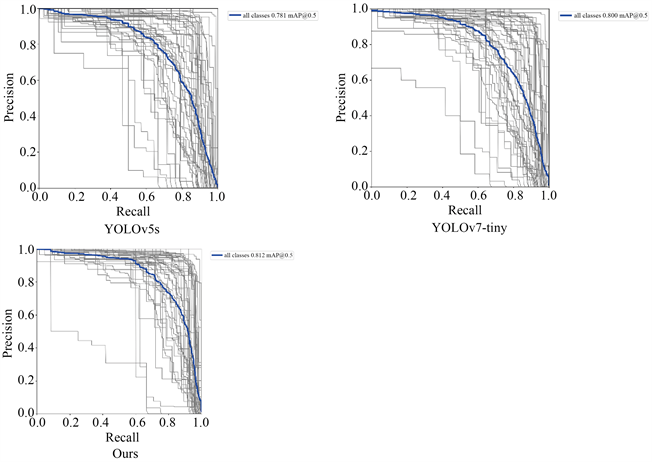
Figure 8. Comparison of results from different models
图8. 不同模型结果对比
针对TAM三重注意力机制以及增加小目标检测层对于模型的影响,通过消融实验验证,两者都可以提高模型的检测精度,具体检测精度值可参见下表2,将两者同时引入YOLOv7-tiny模型中,可以显著提高模型的检测精度。
5. 结论
本文针对轻量级目标检测网络YOLOv7-tiny改进,在原主干特征提取网络增加浅层特征层,以提高小目标的检测能力,同时针对这一浅层特征层增加一次上采样操作,并进行特征融合操作,丰富小目标的信息,同时增加目标检测头,以及对应的小目标检测框,提高小目标的特征提取能力。增加特征提取层之后,在主干网络获得的四个有效特征提取层中引入TAM三重注意力机制,利用其三分支结构,实现跨维度的权重信息交互,进而提高小目标检测的精确度。经过试验验证分析,相对于经典网络模型YOLOv5s,改进后的平均精度提高了6.13%,相对于原模型,平均精度值上升了4.21%。改进后的模型延续了YOLOv7-tiny出色的实时性特性,同时具有更出色的小目标检测效果,适用于低计算能力的移动端设备。