1. 引言
企业信用评估可以被看作通过模型分析企业信用数据来评估信用风险的过程,其本质是一个二分类问题。现实中标注样本类别的成本十分昂贵,信用数据中往往含有少量的标记数据和大量的未标记数据。在实际应用中如何有效利用大量的无标记样本和少量的有标记样本去除信用数据冗余性、挖掘数据结构无疑具有重要的实践意义。
特征选择是在不损失数据信息的前提下,去除冗余的可能会对模型产生负面影响的特征,使得最终所选的特征子集是最优的。基于特征子集评价策略的不同,特征选择可以分为:过滤式、包裹式以及嵌入式 [1] 。基于不同监督信息,特征选择可以分为有监督特征选择、无监督特征选择和半监督特征选择 [2] 。传统的半监督特征选择方法包括:基于伪标签的方法、基于图的方法 [3] 、基于SVM的方法 [4] 以及其他半监督特征选择方法 [5] 。
在信用评估领域中的特征选择方法以有监督特征选择方法为主,包括:方差、信息增益 [6] 、信息价值和Pearson相关系数 [7] 等。然而,有监督特征选择方法需要获得大量的具有标记信息的样本,运算成本高,无法对未知数据进行处理。数据添加标签成本巨大,耗费时间长,信用数据中的大量无标记数据被浪费,其隐藏的有效信息无法被合理利用。区别于有监督的特征选择算法,无监督的特征选择算法运算成本大幅降低,不需要事先对数据做标签,且能够挖掘数据的潜在特征,但训练样本的歧义性高。其中,拉普拉斯得分(Laplacian Score, LS)算法 [8] 是一种典型的无监督特征选择算法。
单一的特征选择方法从单一维度以某个特定的评价指标来对特征进行筛选,获得局部最优的特征子集,而集成多种特征选择方法的特征子集可以获得近似全局最优的特征子集。此外,集成特征子集还可以提高算法的稳定性,降低特征子集的不稳定性 [9] 。传统的特征集成方法包括:简单平均、加权平均、Borda计数法、投票法和SVM-Rank等 [10] 。Wang等 [11] 对特征选择算法进行集成时发现,对少数算法进行集成时模型的预测性能要优于集成所有特征选择算法的模型。
为了更好地对信用评估数据进行预测,针对存在标记样本和未标记样本的半监督数据,本文提出一种基于mRMR、XGBoost和拉普拉斯得分(mRMR-XGBoost-LS)算法的信用评估分类模型。在特征选择阶段,结合了过滤式泛化性能好、计算开销小、嵌入式算法效率高、性能好和无监督特征选择算法不需要数据标签的优点进行特征选择。首先,在半监督数据的有标记训练集上执行有监督的过滤式算法mRMR和嵌入式算法XGBoost,在有标记和无标记训练集上执行无监督的过滤型算法拉普拉斯得分法,分别得到特征的排序。其次,根据特征的排序分别赋予特征相应的权重,并简单求和得到特征最终的权重。最后,按照权重大小选出最优的特征子集。在分类阶段,分别基于XGBoost、LightGBM和CatBoost算法构建信用评估分类模型,以G值和F值来度量不同特征选择方法、不同分类算法下信用评估模型的分类性能。
本文将采用未筛选的特征子集和三种特征选择算法所构建的信用评估分类模型以及本文提出的基于mRMR-XGB-LS算法的信用评估分类模型进行研究对比,结果表明本文所提信用评估分类模型不仅大大减少了无关冗余特征,有效避免单一特征选择方法的不稳定性,而且还能对半监督数据进行有效处理,提高信用评估分类模型的泛化能力。
2. 相关理论
2.1. mRMR算法
本模板过滤法不依赖特征分类器,通用性强,特征子集冗余度较低,但所选特征子集在分类精确度方面通常低于包裹法和嵌入法。mRMR [12] 是一种典型的过滤式特征选择算法,该算法同时考虑特征之间的相关性以及特征与目标变量之间的相关性。mRMR以不同的方式对特征之间的相关性和冗余性进行衡量。用
表示数据集S的第i个特征,度量S与类别c之间的最大相关最小冗余的两种方式如下:
(1)
(2)
研究表明 [12] 选择特征(2)式比(1)式更加有效,已有研究多选择式(2)进行研究 [13] [14] 。针对mRMR算法中的冗余性度量函数,罗康洋和王国强 [14] 构造两个新的选入第k个特征的评价函数:
FACQ (F-test AC quotient):
(3)
FDAQ (F-test DAC quotient):
(4)
其中,
(5)
为绝对值余弦度量。该评价函数能够更加容易的识别出变量之间的冗余信息,得到更为简洁的特征子集。因此,本文在构建集成型特征选择的方法时选择文献 [14] 中改进的mRMR特征选择算法。
2.2. XGBoost特征选择算法
本模板XGBoost [15] 的基础是梯度提升算法。相比于传统的梯度提升算法,XGBoost求解损失函数极值时使用泰勒二阶展开,另外在损失函数中加入了正则化项,使得算法收敛速度更快、求解效率更高。XGBoost算法在构建树的过程中,贪婪的选择能使分割后整棵树增益值最大的特征作为叶子节点,即对树分割时选择当前使得信息增益最大的特征。信息增益的计算如下所示:
(6)
因此,特征被分割的次数越多,其对树模型的增益越大,该特征重要度越大。XGBoost特征选择算法中对特征的筛选取决于各个特征对模型贡献的重要度,即特征用于树分割次数的总和。XGBoost通过统计特征在树模型构建过程中被用于分割的次数总和来确定特征的重要度,通过对特征的重要度从高到低排序进行特征选择。XGBoost算法作为典型的嵌入式算法,运算效率高,在以往研究中被广泛应用。
2.3. 拉普拉斯得分算法
没有标签信息指导的情况下,无监督特征选择方法通过引入相关性、数据流形和聚类等技术来筛选有效特征。无监督特征选择算法也可以分为过滤式、封装式和嵌入式三大类。
拉普拉斯得分算法 [8] 是由He等人于2005年提出的一种基于拉普拉斯特征映射及局部保留投影的无监督过滤式特征选择算法,实现方便、计算成本较低且效率较高。关键性假设是同一类别的数据样本相互靠近,不同类别的数据样本相距较远。目的是在特征选择过程中保持数据的局部几何结构。其步骤如下所述。
输入:样本资料矩阵X
,
其中第i行表示第i个样本,记为
;第j列表示第j个特征,记为
。
输出:特征的拉普拉斯得分
步骤1:构建样本的相似度矩阵
若样本
是样本
的p最近邻,
;否则
,则样本的相似度矩阵为
。
步骤2:构建拉普拉斯矩阵
令对角矩阵
,则拉普拉斯矩阵
,其中
。
步骤3:计算特征
的拉普拉斯得分
令
,
,则特征
的拉普拉斯得分
。
对于特征
,
越小,该特征越重要。
3. 基于mRMR-XGB-LS算法的信用评估分类模型
由于在拉普拉斯得分算法中,特征的拉普拉斯得分L越小,代表特征越重要。为了方便统一的计算和衡量,采用高斯函数将L进行转换,得到新的衡量特征的重要性
,则有:
(7)
当L越小,
越大,特征的重要性越大。
本文提出一种基于mRMR-XGB-LS算法的信用评估分类模型,在特征选择阶段结合了过滤式泛化性能好、计算开销小和嵌入式算法效率高、性能好,无监督特征选择算法不需要数据标签的优点。详细步骤如下。
输入:无标记训练特征
、有标记训练特征集
及其标签
,特征个数m,选择特征个数n。
输出:特征子集
和信用评估分类模型。
步骤1:计算特征的重要度并进行特征排序
对于数据集的每个特征
,根据LS算法计算特征在所有训练集(
和
)上的重要度得到其特征排序为
;根据mRMR特征选择算法计算在有标记特征
上的重要度并得到其特征排序
;
利用XGBoost特征选择算法得到各个特征重要度并得到其特征排序
。
步骤2:计算特征的最终权重
根据特征排序
、
、
得到特征权重
、
、
,对其进行加和,得到特征总权重
,其中
(8)
步骤3:选择最优特征子集
对
进行排序,选择前
个权重最大的特征子集。
步骤4:构建信用评估分类模型
基于最优特征子集
,利用XGBoost、LightGBM和CatBoost构建信用评估分类模型。
信用评估分类模型的流程图如图1所示。
4. 实验结果与分析
4.1. 数据集和数据预处理
为了验证本文提出的基于mRMR-XGB-LS算法的信用评估分类模型的可行性,选取UCI中的Taiwanese Bankruptcy Prediction Data Set数据集和Kaggle上Financial Distress Prediction数据集进行试验研究。前者是预测公司是否破产的数据集,当类标签为0时,表示该公司正常;当类标签为1时,表示该公司破产。后者是预测样本公司是否陷入财务困境的数据集,当目标变量大于−0.5时,该公司应被视为健康(0);否则被视为财务困境(1)。这两个数据集中的其他数据为样本公司的财务特征和非财务特征。将两个数据集中财务困境或者破产的样本记为正样本,否则记为负样本。
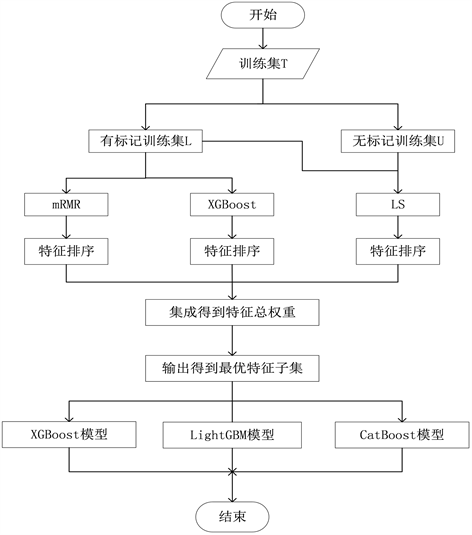
Figure 1. Credit evaluation classification model based on mRMR-XGB-LS algorithm
图1. 基于mRMR-XGB-LS算法的信用评估分类模型
对两个数据集进行数据预处理。首先,删去数据集中重复的样本和特征。其次,进行缺失值处理:删去数据中缺失程度大于1/3的特征;针对代表破产的样本,删去超过10个缺失值的样本。针对代表未破产的样本,删去所有含有缺失值的样本。接着,对于缺失值,使用每个特征的均值对其填充。最后,使用离差标准化来去除数据的量纲。数据处理后,结果如表1所示。
从两个数据集的分布可以看出,数据集特征较多,需要进行特征选择以去除冗余、无关的特征。
4.2. 实验设计
首先,将公开数据集按类别分层划分,抽取20%的样本作为测试集
,将80%的样本作为训练集T。其次,为了探究不同情况下本文所提出的基于mRMR-XGB-LS算法的信用评估分类模型的有效性,在训练集T中依照比例分层划分为有标记训练集L (包括样本特征
和样本类别
)和无标记训练集U (包括样本特征
和样本类别
),并将U中标签删去当作无标记样本。不失一般性,取L和U的比例分别为3:2、1:1、1:2、1:3和1:4。接着,在
上训练mRMR和XBoost特征选择算法,在
和
上训练LS。最后,分类器选择XGBoost、CatBoost和LightGBM。
为了选择不同特征算法的最优参数使其在测试集上达到最高的性能以及充分验证模型的有效性,对不同模型进行五折交叉验证,所有比例下同一模型的参数保持一致,将其评估指标的均值进行对比。对于分类算法的参数选择默认值,不对其进行设定。在本文算法中,LS中p近邻数是较为重要的参数。根据实验得到LS中的p值和最佳特征个数如下表2所示。

Table 2. Parameters of feature selection
表2. 特征选择参数
4.3. 分类评估指标
由于本文所选择数据集是高维不平衡的数据集,通常可以构建混肴矩阵,利用正类(少数类)样本召回率
、正类(少数类)样本查准率
、G-means (G)值和F-value (F)值来衡量模型性能。具体定义见表3:
(9)
(10)
(11)
(12)
(13)
其中,
衡量了违约样本被正确预测的概率,
衡量了非违约样本被正确预测的概率。G值综合评估了模型对两种类别的样本预测正确的性能,G值越大,代表模型整体的性能越强。F值综合考虑了违约样本的召回率和精准率,F值越大,表明模型对违约样本的识别能力越强。此外,ROC曲线下的面积AUC也常用来衡量分类模型的性能。
4.4. 实验结果分析
利用XGBoost、LightGBM和CatBoost三种算法,分别通过使用原始特征集、改进的mRMR特征选择算法、XGBoost特征选择算法、LS算法以及mRMR-XGB-LS特征选择算法(简记为m-X-L)构建信用评估分类模型,对比不同模型的性能以验证本文所提出的基于mRMR-XGB-LS算法的信用评估分类模型的有效性,其中LS使用的是包含有标记和无标记数据的所有训练集。结果如表4~6所示,粗体表示精度最高。
Table 4. Comparison of G values of XGBoost, LightGBM and CatBoost models
表4. XGBoost、LightGBM和CatBoost三种模型的G值对比
Table 5. Comparison of F values of XGBoost, LightGBM and CatBoost models
表5. XGBoost、LightGBM和CatBoost三种模型的F值对比
Table 6. Comparison of AUC values of XGBoost, LightGBM and CatBoost models
表6. XGBoost、LightGBM和CatBoost三种模型的AUC值对比
由表4和表5可以看出:在大多数情况下,本文所提出的基于mRMR-XGB-LS算法的信用评估分类模型的G值和F值不仅高于LS、mRMR和XGBoost三种特征选择下的信用评估分类模型,而且高于原始特征数据集。此外,在各个数据集和信用评估分类模型下,本文模型的G值和F值的均值都是最高,这说明本文所提出的基于mRMR-XGB-LS算法的信用评估分类模型稳定性强,可以有效剔除冗余、无关的特征,且能够有效利用无标记样本识别出少数类样本,提升模型总体性能。由表6可得,虽然本文算法的AUC值排名并不靠前,但总的来说与其他算法相比,差距不大,分别维持在0.94和0.92左右,这也从侧面表明了本文模型的优越性和稳定性。
5. 结论
信用评估的实际应用中,数据集中存在着大量标签不完整的数据,单一的有监督特征选择方法和无监督特征选择方法都各有其局限性。为此,本文提出一种基于mRMR-XGB-LS算法的信用评估分类模型,能够利用半监督数据有效筛选特征构建模型。筛选后的特征子集更加准确,避免了单一特征选择方法无法有效筛选出冗余、无关特征及单一特征选择方法性能的不稳定性。此外,在多个数据集和信用评估分类模型中,基于mRMR-XGB-LS算法的信用评估分类模型的G值和F值均为最高,显示了本文所提方法的优越性。
今后有待进一步研究的工作包括:
1) 现有的研究大部分是针对分类问题提出的,针对回归问题的半监督特征选择方法是一个有意义的课题。
2) 本文是基于单一模型对数据进行分类的,如何构建有效的集成信用评估分类模型以克服单一模型的不足,提高模型的稳定性和鲁棒性是一个值得研究的课题。