1. 引言
骨干粒子群算法(Bare-bones Particle Swarm Optimization, BBPSO)在2003年首先被Kennedy提出 [1] ,与标准粒子群算法 [2] 相比,骨干粒子群算法的位置更新方程中没有速度项,在后续迭代过程中粒子位置更新服从高斯采样策略。由于骨干粒子群算法的简单性和强大的竞争力,它成为了最方便的粒子群算法,并逐渐引起了越来越多的学者的关注。不同学者对于BBPSO算法研究的侧重点也各有不同 [3] 。在理论研究方面,文献 [4] 运用数学归纳法证明了标准粒子群算法可以转化为骨干粒子群算法,且给出了BBPSO算法更为通用的形式;文献 [5] 中提出了一种带有自适应扰动值的BBPSO,并利用随机过程理论证明了改进算法的收敛性;文献 [6] 认为获得的保证种群均方收敛到全局最优的参数条件并不适用于所有函数,并提出了利用首达时来分析种群的收敛性。在应用方面,文献 [7] 通过将改进的骨干粒子群优化算法和被称为定向混沌搜索的局部搜索器相结合,解决了具有阀点效应的动态经济调度问题;由于大多数粒子群算法中采用的传统粒子更新机制和群初始化策略限制了其处理高维特征选择问题的性能,文献 [8] 提出了一种基于互信息的骨干粒子群算法的特征选择算法;文献 [9] 利用改进的骨干粒子群算法解决了评论员的分配问题。
虽然骨干粒子群算法在实现过程中省去了调节多个参数这一步骤,更易于实现,但和粒子群算法一样,其在多峰函数上寻优时,仍存在容易停滞、陷入局部最优的问题,导致求解的结果不够理想。为了进一步改善骨干粒子群算法的性能,学者们主要从改进高斯采样的均值或方差部分 [10] [11] 、引入突变算子 [12] 、与其他群智能算法结合 [13] [14] [15] 等方法出发,在提高粒子多样性的基础上,来改善粒子的全局和局部搜索能力。
针对骨干粒子群算法过早收敛,易于陷入局部最优的问题,本文提出了一种搜索中心随机,带有自适应扰动值,且在粒子停滞时依概率发生突变的自适应突变骨干粒子群算法(AMBPSO)。自适应扰动值的大小由每个粒子的收敛程度和种群的多样性共同决定,在扰动值中引入了sigmoid函数,使得扰动值最终收敛到0。根据高斯分布更新后的粒子,将依概率发生突变,突变概率由停滞次数所决定。采用9个经典的测试函数对所提出的算法进行验证,并与其他5种粒子群算法(PSO, BBPSO, ABPSO, SLBPSO, AWPSO)进行了比较。
本文的其余内容组织如下:第一部分介绍了传统的骨干粒子群算法;第二部分提出了改进的基于自适应突变的骨干粒子群算法(AMBPSO),并给出了详细的算法流程和参数选择方式;第三部分通过仿真实验验证了提出的算法的有效性;第四部分给出了文章的最终结论及未来展望。
2. 骨干粒子群算法
Clerc和Kennedy [16] 基于对标准粒子群算法中粒子运行轨迹的研究,得出了粒子以其个体局部最优和群体全局最优位置的加权平均值为中心进行振荡的结论。
根据这一结论,骨干粒子群算法 [1] 由Kennedy于2003年提出,其比粒子群算法更为简单、且基本无参数。骨干粒子群算法中粒子的位置采用高斯采样策略进行更新。通常,第i个粒子的位置表示为
,则粒子在搜索过程中的位置更新方程为
(1)
其中,
为高斯分布的均值,
为高斯分布的标准差。
表示第i个粒子当前的局部最优位置,通常记为Pbest;
表示当前粒子领域内找到的全局最优位置,通常记为Gbest。
粒子的局部最优位置Pbest和群体全局最优位置Gbest的更新方程为
(2)
(3)
3. 基于自适应突变的骨干粒子群算法
3.1. 自适应扰动策略
根据粒子的位置更新方程(1)可知,粒子的搜索中心不够灵活,一定程度上限制了粒子的搜索区域。为了在早期增强粒子的全局搜索能力,在高斯分布的均值项中引入两个[0, 1]之间的均匀随机数。为了避免过多的粒子停滞,需要使高斯分布的标准差不为0。因此,改进的算法将自适应扰动值引入到了高斯分布的标准差部分。由于过大的扰动值会极大的影响粒子的收敛速度,使粒子难以快速达到收敛状态;扰动值过小则使得粒子仍易发生停滞,故设置该扰动值由在[0, 1]上的均匀分布数、粒子的多样性和收敛程度共同决定,这在一定程度上能使粒子的收敛速度和粒子的多样性维持平衡。
设第i个粒子所在的位置为
,后续迭代过程中粒子位置的更新方程为
(4)
其中,rand1、rand2和rand3是在[0, 1]上服从均匀分布的随机数;
和
是从所有粒子中无放回地挑选出来的任意两个粒子的局部最优位置;
为sigmoid函数;
表示要优化的目标函数;概率
。
上述位置更新策略中,扰动值
由随机的均匀分布数、两个随机挑选的Pbest的差、Gbest和
适应度值的差三者共同决定。由式(4)可知,不考虑rand3时,假设
保持不变,则当
时,该粒子的扰动值最大,以帮助粒子跳出局部最优。根据Pbest和Gbest的更新
方程,AMBPSO经过多次迭代,所有粒子都将收敛到同一个位置Gbest,即
,此时
,这也是保证种群收敛的必要条件之一。
3.2. 自适应突变策略
在粒子位置未停止更新时,所得到的Gbest的值仍可能为局部最优值,故仅依靠提出的自适应扰动策略难以确保粒子收敛到全局最优。因此,将自适应突变策略引入加了自适应扰动策略的骨干粒子群算法中。对于每一个粒子i,其都依概率发生突变,突变粒子的突变维数也由突变概率决定,设计了时变因子L来控制粒子的突变,来帮助粒子跳出局部最优。时变因子L的更新方程为
(5)
其中,
为最大迭代次数,且L随着迭代次数的增加而减小。
以粒子i为例,其发生突变的概率为
(6)
其中,t为迭代的次数;
为粒子停滞的次数,即
(7)
自适应突变的伪代码如下:
由表1可知,突变概率的大小影响了突变的速度,大的突变概率使粒子更容易发生突变,过小的突变概率会使粒子难以快速跳出局部最优。每个粒子都有一定的概率会发生突变,从而增加粒子的多样性,为粒子跳出局部最优做准备。为了缓解突变时对Pbest和Gbest的经验知识的破坏,粒子突变后的位置为随迭代次数自适应的Pb和Gb的加权平均值,且迭代前期粒子偏向于对自身经验的认知,增强了粒子的全局搜索能力;迭代后期粒子偏向于对群体经验的认知,进一步保证了粒子的收敛性。
3.3. 算法流程
基于自适应突变的骨干粒子群算法的具体步骤如下:
步骤1设置种群参数;
步骤2伪随机数法初始化粒子;
步骤3评估整个种群,更新粒子的个体最优位置Pbest和种群的全局最优位置Gbest;
步骤4根据式(4)更新每个粒子的位置;
步骤5计算粒子全局最优位置Gbest在迭代过程中的停滞次数;
步骤6计算粒子突变的概率及发生突变粒子的突变维度,进而更新粒子的位置;
步骤7重新评估种群,计算粒子的个体最优位置和种群的全局最优位置;
步骤8判断是否满足进化终止条件,若不满足则返回步骤4;若满足,则算法终止。
改进后的骨干粒子群算法的流程图如图1所示:
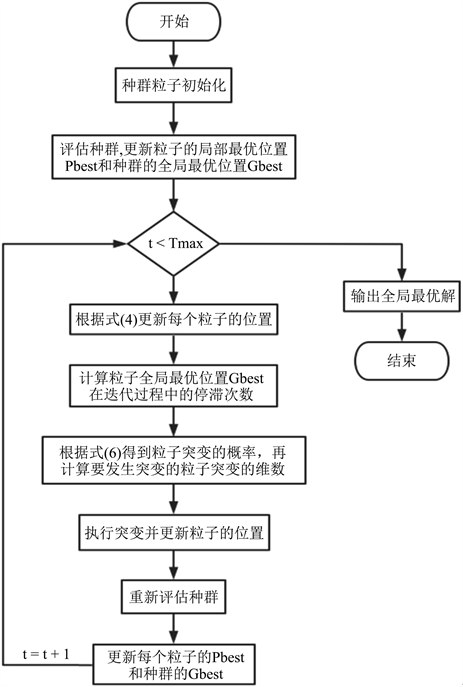
Figure 1. The flowchart of the AMBPSO algorithm
图1. 自适应突变骨干粒子群算法流程图
3.4. 参数选择
Sphere函数是最简单的测试函数,其只有一个全局最优解,故利用AMBPSO算法在Sphere函数上进行测试,以确定的prob的最佳值。实验过程中,将粒子的个数和问题的维度均设置为30,搜索空间为
。为了简化测试过程,每次迭代过程中所有粒子适应度值的标准差被用来计算粒子的多样性,各粒子当前位置和群体全局最优位置间的最大距离代表种群的收敛程度。实验结果如图2和图3所示。
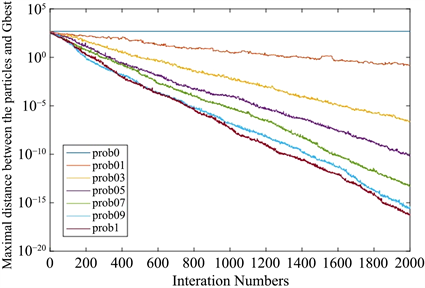
Figure 2. The maximum distance between particles and the global optimal position of the swarm
图2. 各粒子和种群全局最优位置间的最大距离
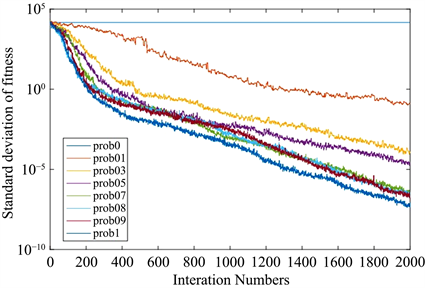
Figure 3. Standard deviation of the fitness of all particles in each iteration
图3. 每次迭代过程中所有粒子适应度值的标准差
由实验结果可得,当
,所有粒子和Gbest间的最大距离随着prob增大而减小。当
时,粒子的收敛程度和收敛速度都最大。由种群中所有粒子适应度值的标准差曲线可得,粒子的多样性也随着prob的增大而减小。当prob的值在0.7和0.9之间时,粒子的多样性曲线基本相同。经过多次试验可得,当prob的取值范围为[0.7, 0.9]时,实验结果达到最优。因此,在后续的试验过程中将prob设置为0.8。
4. 仿真实验
为了进一步验证改进算法的性能,将AMBPSO算法与五种典型的粒子群算法进行比较。所有用于对比实验的算法,其相关描述如表2所示。在进行对比实验时,将粒子个数设置为30,问题维度也为30,最大迭代次数设置为2000。对于每个测试函数,每种算法进行30次独立实验,避免随机性对实验结果的影响。

Table 2. Algorithms and descriptions for conducting experiments
表2. 进行实验的算法及其描述
4.1. 测试函数
为了测试AMBPSO算法在收敛速度和精度方面的提升,采用9个典型的测试函数对算法进行仿真实验。测试函数如表3所示。
4.2. 性能指标
在进行对比试验时,使用三个不同的指标 [5] [15] 来检验改进算法的性能。
第一个指标为每次实验所得种群收敛的精度的均值(Mean of AC,简写为Mean)。设测试函数的全局最优解为
,群体在第t次迭代时得到的全局最优解为Gb,则精度(Accuracy,简写AC)为
(8)
第二个指标为实验得到的精度的标准差(Standard Deviation of AC,简写Std)。由于算法中含有多个随机项,每次实验结果都具有随机性,故该指标用来验证算法寻优的稳定性。
第三个指标为实验的成功率(SR)。该指标指在算法迭代过程没有结束时,找到符合精度(在此设置为10−8)要求的全局最优解的概率。其表达式为
(9)
其中,
为实验成功的次数,n为总实验次数。同时,当
,进一步考虑找到全局最优解的平均函数评估次数(NFE),其表达式为
(10)
其中,FE为每次实验结果达到设置的收敛精度前的函数评估次数。
4.3. 结果与分析
如表4所示,通过平均AC值、AC的标准差和平均函数评估次数来评估粒子群优化算法的搜索能力,实验的成功率用于验证算法跳出局部最优的能力。表3中提到的所有测试函数用于测试算法是否能够获得其全局最优值。当达到最大迭代次数时,对于相同的测试函数,AC值越小,算法的收敛精度越高。
由表4可知,与其他五种算法相比,AMBSPO算法在测试函数
~
、
和
上的平均AC值最小。在测试函数
上,尽管AMBPSO算法的平均AC值不是最小的,但它明显小于标准PSO算法的平均AC值,并且它与BBPSO算法和ABPSO算法中的平均AC值非常相近。在测试函数
~
、
和
上,AMBPSO算法的标准差最小,这表明改进的算法在搜索这些函数的全局最优值时具有显著的稳定性。对于函数
、
和
,AMBSPO算法与其他大多数算法之间的标准差的差异不大,其所得结果的标准差处于理想的状态。
Table 4. Results of algorithms on nine test functions
表4. 算法在9个测试函数上的结果
为了更详细地验证AMBPSO的有效性,根据每次实验获得的AC值,利用显著性水平为0.05 (
)的双样本双尾t检验,对其他五种算法获得的结果和AMBPSO算法获得的结果进行了检验。在表5中,“+”表示AMBPSO算法显著优于对比的算法,“−”与之相反;“=”表明AMBPSO与比较的算法没有显著差异。故由表5可得,改进的算法在测试函数
,
,
和
上明显优于其他所有算法。在测试函数
和
上,AMBPSO算法优于除AWPSO算法外的其他四种算法。对于函数
,AMBPSO算法所得结果仅和SLBPSO算法在t检验结果上对比时没有显著优势。对于函数
,尽管三种算法(AWPSO、BBPSO、ABPSO)的AC值小于AMBPSO算法的AC值,但它们和AMBPSO算法没有显著差异,且AMBPSO算法显著优于PSO算法。对于函数
,AMBPSO算法的AC值显著小于除ABPSO算法外的其他四种算法,和ABPSO算法所得结果没有显著差异。通过比较平均AC值,可以得出AMBSPO算法在绝大多数测试函数上比其他五种算法达到更高的收敛精度。
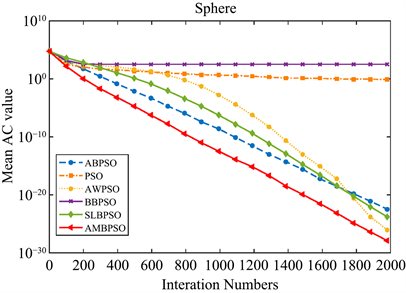
Figure 4. Convergence curve of the function F1(x)
图4. 函数F1(x)收敛性曲线
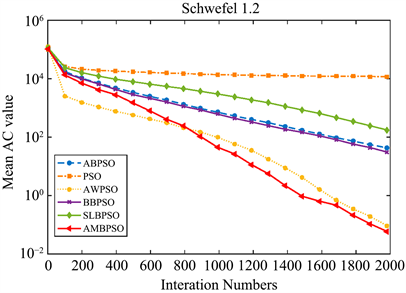
Figure 5. Convergence curve of the function F2(x)
图5. 函数F2(x)收敛性曲线

Figure 6. Convergence curve of the function F3(x)
图6. 函数F3(x)收敛性曲线
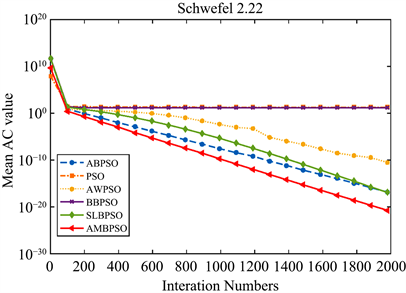
Figure 7. Convergence curve of the function F4(x)
图7. 函数F4(x)收敛性曲线

Figure 8. Convergence curve of the function F5(x)
图8. 函数F5(x)收敛性曲线
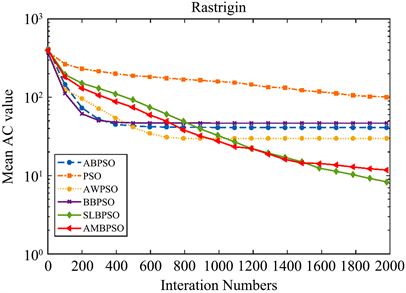
Figure 9. Convergence curve of the function F6(x)
图9. 函数F6(x)收敛性曲线
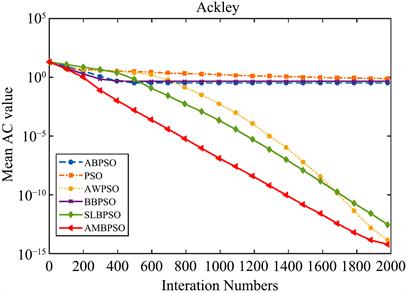
Figure 10. Convergence curve of the function F7(x)
图10. 函数F7(x)收敛性曲线
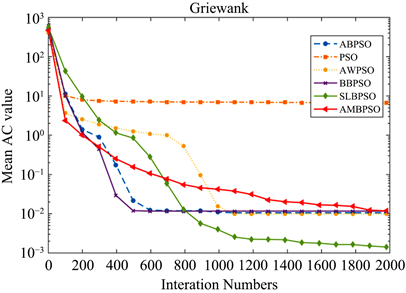
Figure 11. Convergence curve of the function F8(x)
图11. 函数F8(x)收敛性曲线
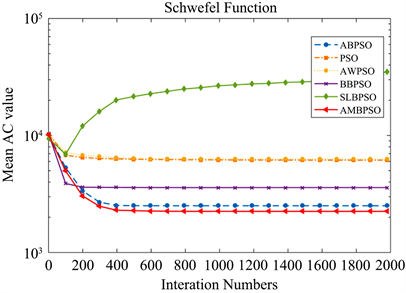
Figure 12. Convergence curve of the function F9(x)
图12. 函数F9(x)收敛性曲线
实验的成功率SR对评估算法效果同样非常重要。从表4中可以看出,只有AMBSPO算法在测试函数
上达到60%的成功率,而其他算法在达到最大迭代次数时无法收敛到指定的精度。测试函数
是多峰函数且具有广泛的局部极小值,这是实验无法实现100%的成功率的原因,但AMBSPO算法获得了最大的SR,且远远超过了其他算法。对于函数
和
,AMBPSO、AWPSO、ABPSO和SLBPSO算法的实验成功率均达到100%,但通过比较它们的平均函数评估次数,可以看出AMBPSO算法的收敛速度比其他算法快得多。对于函数
,AWPSO、SLBPSO和AMBPSO算法达到100%的成功率,但AMBPSO算法的平均函数评估次数为3.3460E+04,比AWPSO和SLBPSO算法的平均函数评估次数少近10,000次,表明AMBPSO算法的收敛速度明显快于其他两种算法。六种算法在每个函数上的收敛曲线如图4~12所示。横轴表示迭代次数,纵轴表示平均AC值,可以清楚地显示每个算法的收敛速度。显然,AMBPSO算法的收敛速度和收敛精度明显优于其他算法。尽管SLBPSO算法在函数
和
上比AMBPSO算法获得更好的平均AC值,但AMBPSO算法的实验成功率远高于SLBPSO算法。

Figure 13. Comparison of statistical results on function F1(x)
图13. 函数F1(x)上实验结果统计值比较

Figure 14. Comparison of statistical results on function F2(x)
图14. 函数F2(x)上实验结果统计值比较
在每个测试函数上实验结果统计值的雷达图如图13~19所示。对于函数
,AMBSPO算法获得的最小AC值为0。对于函数
,所有算法获得的最小AC值均为0。因此,算法在这两个测试函数上获得的结果不再绘制雷达图。由图13~19可得,AMBSPO算法在几乎所有函数上的性能都远远优于其他算法,特别是在最小AC值、平均AC值和标准差方面。对于函数
,虽然AWPSO算法的最小AC值最小,但其最大AC值远大于AMBPSO算法,且AMBPSO算法的平均AC值小于AWPSO算法,最大AC值是所有算法中最小的,这表明了AMBPSO算法的稳定性。对于函数
,SLBPSO算法虽然得到了最小的AC值,但它的最大AC值也远大于比其他算法。此外,在函数
上SLBPSO算法的平均AC值和标准差也大于其他算法,说明SLBPSO算法非常不稳定。因此,通过比较四个统计量的值,可得AMBPSO算法比其他算法具有显著优势。
综上所述,AMBPSO算法总体上比其他五种算法具有更快的收敛速度和更高的收敛精度。

Figure 15. Comparison of statistical results on function F3(x)
图15. 函数F3(x)上实验结果统计值比较

Figure 16. Comparison of statistical results on function F4(x)
图16. 函数F4(x)上实验结果统计值比较
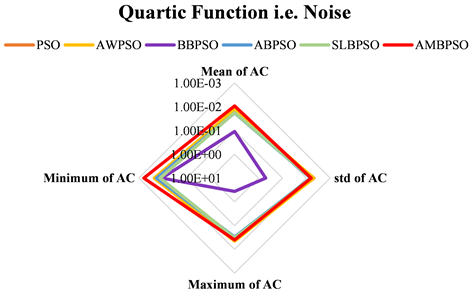
Figure 17. Comparison of statistical results on function F5(x)
图17. 函数F5(x)上实验结果统计值比较
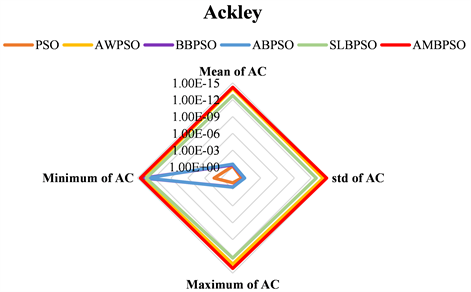
Figure 18. Comparison of statistical results on function F7(x)
图18. 函数F7(x)上实验结果统计值比较
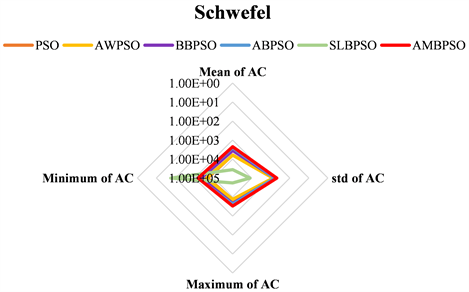
Figure 19. Comparison of statistical results on function F9(x)
图19. 函数F9(x)上实验结果统计值比较
5. 结束语
针对骨干粒子群算法易陷入局部最优、收敛速度较慢的问题,本文提出了一种自适应突变骨干粒子群算法。通过在粒子的位置更新方程中引入自适应扰动值,增加了粒子的多样性,帮助粒子跳出局部最优。同时,设计了一种突变策略,使粒子按照适当的概率发生突变。突变过程中引入了具有下降趋势的时变因子,以平衡粒子的勘探和开发能力。采用9个经典测试函数对所提出的算法进行了验证,并将提出的AMBPSO算法和PSO,AWPSO,BBPSO,ABPSO,SLBPSO算法进行了比较。实验结果表明,AMBPSO算法的寻优能力在多种类型的函数上均优于其他粒子群算法,且提出的算法扩大了粒子群的搜索范围,显著提高了粒子在搜索全局最优解时的收敛速度和收敛精度。如何利用严谨的数学理论推导分析算法的收敛性将是下一步的主要工作。
NOTES
*通讯作者。