1. 引言
生成式对抗网络(Generative adversarial network,简称GANs)自Ian Goodfellow [1] 等人提出后,越来越受到学术界和工业界的重视。随着对抗生成网络的发展,其在图像与视频的生成 [2] [3] [4] 、图像翻译 [5] 、图像修复 [6] 等领域都取得了巨大的成功。这些成功引起了人们对GANs广泛应用的兴趣,从数据增强 [7] 和领域适应 [8] 到图像转换 [9] 和照片编辑 [10] 。GANs的成功很大程度上依赖于大型数据集的可用性。
在实践中,常常遇到数据维度很高且数据量较少的情况。这种情况会致使GANs的性能显著降低,例如使用StyleGAN端对端生成图片时,使用20%的FFHQ (1024*1024分辨率)数据集得到的FID值为18.6,使用10%的FFHQ (1024*1024分辨率)数据集时得到的FID值为25.6 (FID越小越好),性能明显的下降。为了解决GAN性能下降的问题,最近提出了各种策略,包括使用预训练模型 [11] 、剪枝 [12] 和数据增强 [13] 。然而,尽管改善了结果,这些策略也都有限制。如果数据域保持相似,预训练模型的使用效果最好。剪枝需要进行多轮训练,以增加神经结构的稀疏性,然而这提高了训练成本。数据增强可以增强结果,但由于数据不足,其收益有限(见表3)。正则化是一种廉价且潜在有效的方法,Tseng等人 [14] 最近的工作采用了这种方法,控制判别器对真实图像的预测与生成图像之间的距离。
在本文中,我们研究了一种新的正则化方法来增强有限数据下的GANs训练。
2. 相关工作
生成对抗网络。已经提出了许多GAN变体来稳定训练并提高生成结果的感知质量。主要分为三个方向:1) 研究了不同的损失函数。2) 设计新的体系结构 [15] 。3) 各种归一化技术 [16] 。除此之外还设计了一些技术来产生更多样化的样本 [17] 并提高收敛性 [18] 。
GANs的正则化,正则化技术被广泛用于稳定训练,其中最具有代表性的就是WGAN。WGAN中最小化了真实分布和生成分布的Wasserstein距离,鉴别器(Discriminator, D)的正则项为1-Lipschitz,通过在真实数据和生成数据之间进行插值,惩罚鉴别器相对于输入数据点的梯度。Roth等人 [19] 鼓励鉴别器在真实数据和生成数据上的梯度范数为零。除梯度范数外,约束鉴别器是另一种常用的机制 [20] ,权值惩罚也是GANs常用的正则化方法 [21] 。
数据不足导致GAN训练变得更具挑战性。已经提出了一些方法来提高用有限数据训练的GANs的性能。较为常见的方法是使用数据增强,Jiang等人 [22] 使用生成的数据作为对真实数据的“增强”,而其他人则在真实实例上进行增强。Chen等人 [23] 利用修剪神经网络来提高性能。使用预训练模型也是一个不错的方法,使用与目标数据集相似度较高且数据量足够的数据集先进行训练,然后再训练目标数据集。本文的方法与这些方法的不同之处在于,主要考察梯度之间的范数差。设计的正则项主要是考虑真实数据在鉴别器上的梯度范数,与生成的数据在鉴别器上的梯度范数二者之间的差值(见图2)。且该正则项与绝大多数GANs兼容可同时使用。
本文的主要贡献有3个方面:
1) 本文设计了一种新的正则项,该正则项具有很强的兼容性,适用于多种模型,本文的正则项几乎不增加计算成本。
2) 使用新的正则项,有效地改善了图像的质量。在有限的数据集上对于图像质量有明显的提升,在数据量足够的数据集上生成的图像包含更多的细节。本文的正则项几乎不增加计算成本。
3. 方法
3.1. 生成对抗网络简述
生成对抗网络(GANs)由一个生成器(Generator, G)和一个鉴别器(Discriminator, D)组成,它们相互竞争。生成器
由参数
的调整使输入的一个简单的低维分布
(例如高斯分布)向包含有高纬度数据的
域学习,使二者最终形成一个复杂的映射。鉴别器
被训练区分真实数据
与合成数据
。生成器与鉴别器之间博弈过程可以由两个损失函数表示:
(1)
对于不同的生成对抗模型,使用的损失函数有所不同,例如
或者
。
3.2. 问题提出
Karras等人和Tseng等人在实验中发现数据量越少模型生成图像的质量越低,当数量低于一定的值时,模型无法收敛。具体来说,当使用100%、20%、10%的Flickr FaceHQ (FFHQ)数据集分别来训练DCGAN,在使用10%或者20%的数据集时能够发现FID值(越低越好)会呈现急速的上升。
本文认为,数据量较少时模型的损失函数无法获取合理的梯度指导,导致函数始终在局部最优点处徘徊或者直接错过了最优点。通过实验发现在不同的数据使用比例下,使用真实数据与合成数据,它们在判别器上梯度的范数之间的差值存在明显的差异。具体来说,数据量越小时二者的梯度的范数差值越大(见图1)。
3.3. 正则化方法
在数据量不足时,常见的解决方法有三种:数据扩充,模型架构改进,添加正则项。这三种方法中添加正则项相较于模型架构的改进,其优势在于可以节省更多的算力,因此添加正则项是成本更低的一种选择。
为了使模型在小样本下也能获取更加合理的梯度指导,能够获得更高质量的产出,本文提出一种新的正则化方法。梯度的范数差的数学表达式为:
(2)
其中
来自于生成器合成的数据即
,
是来自于真实的数据。为了表述方便,我们称梯度的范数差为梯度差。
(3)
在(3)式中
为判别器的正则项,
是一个非负的超参数,数据量越少该参数大。t为模型的迭代次数,考虑到梯度的突增或者突减而导致的误差,本文使用均值的手段来缓解误差所带来的影响。具体来说,就是考虑其前两次迭代的梯度值求和然后求其均值。
是真实图像的梯度值,
是来自生成图像的梯度值。具体流程图如图2。
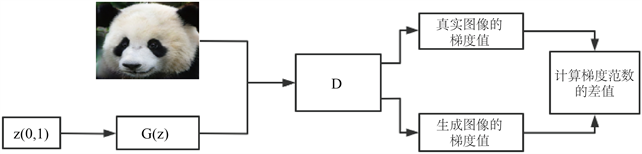
Figure 2. Gradient extraction flowchart
图2. 梯度提取流程图
4. 实验
4.1. 实验环境
本文配置的环境python3.7 + pytorch1.8.0 + cuda11,使用一张RTX-TITANX显卡(为了满足大多数模型的显存需求)。
数据集:在单一种类生成实验中,在256 × 256分辨率下,测试了动物脸狗和猫、100镜头奥巴马、熊猫和脾气暴躁的猫。在1024 × 1024分辨率下,测试了Flickr FaceHQ (FFHQ)、牛津花、WikiArt的艺术画、Unsplash的自然景观照片、Pokemon、动漫脸、头骨和贝壳。这些数据集旨在涵盖具有不同特征的图像:写实照片、图形插图和类似艺术的图像。在多样性实验中使用CIFAR-100数据集。
除开CIFAR-100数据集外,模型主要使用256*256与1024*1024这两个分辨率的数据集。其原因主要有一下几点1):首先这两种分辨率是常用的图片分辨率。2) 使用256*256作为先验数据集验证模型的改动是否有效,有效后在使用高分辨率的图片训练模型可以有效的减少计算量。3) 1024*1024分辨率代表了图像生成的绝对质量,是对模型生成能力最大考验(图像超分辨率下除外)。
评估指标:1) 我们采用Fréchet起始距离(FID)来度量模型生成的图片的质量,FID量化生成图像和真实图像的分布之间的距离。对少于1000张图像的数据集(大多数只有100张图像),我们让G生成5000张图像,并计算合成图像和整个训练集之间的FID (FID值越低表示生成的图像质量越高)。2) 使用IS (inception score)值,IS值可以体现模型生成图像的质量的好坏与多样性的丰富程度(IS值越高越好)。
4.2. 实验
在该实验中选取具有代表性的三个模型:1) 最先进的(SOTA)无条件模型StyleGAN2,2) BIGGAN模型。3) WGAN模型。在选取的三个模型中使用正则项
进行对比。所有的模型均迭代100,000次,批次大小为16。
通过表1的对比试验,容易发现在添加了正则项的模型与未添加正则项的模型在数据量较少的部分提升是显著的。当数据量达到一定的规模时,提升的效果逐渐减弱,这是符合预期的结果。在数据量充足时,有足够多的数据支撑模型原本的损失函数去求其梯度值,得到的梯度值是较为稳定使得模型的能有较为稳定的输出。

Table 1. FID comparison of some datasets at 1024*1024 resolution
表1. 1024*1024分辨率部分数据集的FID比较
在上述的实验中,对比的模型本身就是较为优秀的模型。为了进一步体现本文的正则项
的效果,将使用更少的数据量(几百张)来进行消融实验(见表2)。
由表2的结果可知,
的在数据量越少的情况下展现的效果是越明显的。值得注意的,在数据量较少的情况下对于
的选择就比较重要了。例如,在表3的实验中取定
。这样取值主要是本文认为一般的损失函数以及正则项不能很好的反应出梯度变化的趋势,更多的是保证模型的收敛以及稳定性。本文提出的正则项可以直观的体现出数据量带来的影响,那么在数据量较少的情况下提升其在损失函数中的占比是有助于模型更快更好的收敛的。
Table 2. FID comparison of a few sample data sets at 256*256 resolution
表2. 256*256分辨小数据集的FID比较
CIFAR-100数据更具挑战性,因为它包含100个类别,每个类别的图像更少。在表3中,由IS值作为主要的多样性指标,就结果来看增加正则项对于IS值是有正面影响的。
Table 3. FID value and IS value at 64*64 resolution
表3. 64*64分辨率下的FID值与IS值
5. 结论
本文提出的正则化方法是一种基于梯度之间的范数差来设计的,该方法的优势在于它能匹配模型本身已经设计好的损失函数(正交)不需要修改原函数。其次,该正则化方法能够有效的缓解由数据量不足导致的模型性能的显著下降,并且该方法几乎不会增加计算的成本。不足之处在于,本文试图从理论的角度来分析该正则化方法,但是,由于对数据批量处理的执行方式,对所研究的损失进行理论分析极具挑战性,本文找不到一个具有严密逻辑性的数学解释。
NOTES
*通讯作者。