1. 引言
基站选址是通信网络规划的一项重要内容,在综合考虑信道质量、建设成本、覆盖约束以及其他约束条件下,规划基站数量和位置 [1] 。在实际网络规划中,考虑基站的建设成本和一些其他因素,有时候可能无法把所有弱覆盖区域都解决,这时候就需要考虑通信业务量的因素,尽量优先解决通信业务量高的弱覆盖区域。对于大范围区域基站的选址,一般建立两种基站,宏基站和微基站,选址要达到区域业务量为总业务量的百分之九十,基站建设成本最低即为合理选址。
对基站进行选择,两种基站的选择只有选择和不选择,因此可建立0~1整数规划模型。基站选址中优先选择服务量最大的基站,即在大量数据中寻找聚簇点,均值漂移算法适用于对低维数据求解目标函数。但是考虑到基站选址过程中智能算法往往是随机生成初始解集 [2] ,在实际场景中,通信业务量分布是不均匀的,比如校园区域的业务量往往较大,在基站的选址中要优先考虑此类区域。传统的均值漂移算法采用随机生成初始解集的方法在面对大量的不均匀数据集的时候会导致收敛速度变慢,甚至陷入局部最优 [3] [4] 。
为解决上述问题,本文提出一种基于聚类算法优化的均值漂移算法的移动通信网络站址规划优化算法。引入聚类策略,对信号弱覆盖点进行区域聚类,把距离近的弱覆盖点聚成一类,可以得到弱覆盖区域,对不同的弱覆盖区域分开管理使得可以更好的解决弱覆盖问题。试验结果表明:该方法可以以较低的建设成本满足基站选址的覆盖条件,且均值漂移算法的收敛速度更快,对基站的站址规划有着普适性。
2. 基本概念
为了方便理解基站选址原理和本文提出的算法,本节介绍以下原理和概念。分别是基站选址基本要求、均值漂移算法、DBSCA聚类算法。
2.1. 基站选址原理
对基站进行选择,基站的选择只有选择和不选择,属于0~1背包规划问题,在一定的重量范围内选择价值最高的物品,即优先选择服务量最大的基站,并通过启发式算法求解目标函数。为了便于计算,将通信业务量区域用很小的栅格进行划分,只考虑每个栅格的中心点,即任给一个区域,都可以划分成有限个点。每个点有一些属性值,包括:坐标,是否为弱覆盖点,业务量等。站址也只能选择区域内的点。设选择基站的覆盖范围为d,基站所规划的点的坐标为:
,则对于坐标为
的点,若
,则认为该点被该基站覆盖,否则认为该点没有被该基站覆盖。同时,实际中还需要考虑一个约束条件,即新建站址之间以及新建站址和现有站址之间的距离不能小于等于基站之间的门限。
2.2. 均值漂移算法
均值漂移算法可以用于聚类,因为每个均衡都有其自己有吸引盆地。设想在一个有N个样本点的特征空间初始确定一个中心点,计算在设置的半径为D的圆形空间内所有的点与中心点的向量计算整个圆形空间内所有向量的平均值,得到一个偏移均值将中心点移动到偏移均值位置重复移动,直到满足一定条件结束 [5] 。
2.3. DBSCA聚类算法
DBSCAN算法是一种基于密度的聚类算法,它主要原理是通过统计每个点邻域内包含的点个数来确定该点的密度,不像GMM (Gaussian Mixture Models)需要对数据进行模型假设,因而它可以发现任意形状的簇。另外,此算法也不需要复杂的数学计算,适用于处理大量的数据,这种算法可以较好地将弱覆盖点进行聚态分类。若两个个弱覆盖点的距离不大于d,则这两个个弱覆盖点应聚为一类,并且考虑聚类性质具有传递性,即若点A和点B是一类的,点B和点C是一类的,则点A、B和C都是一类的。
3. 基站选址模型建立
基站网络覆盖模型的优化描述:
是由有限集X及F的一个子集族F组成,X为基站覆盖区域集合,F为移动通信网络基站覆盖的区域集合 [6] 。子集族F的基站范围覆盖了有限集中的区X域,X中每一个服务区域至少属于F中的一个子集。即弱覆盖点
,基站点
。如何确定移动网络基站的选址位置,就是找出移动通信网络基站覆盖区域F中区域X的最小子集
,使得
。
假设共选择n个位置新建宏基站和微基站基站,宏基站覆盖半径30,微基站覆盖半径10,
为基站j的服务量,最大的总服务量为W,须达到的总业务量为Sum。引入0-1变量:
,
可得
(1)
(2)
同理引入0-1变量,表示处j的弱覆盖点是否被建立在i处的新基站覆盖,可得
(3)
其中
代表宏基站,
代表微基站。
设
为点i和点j之间的欧式距离,可得其表达式为
(4)
令
表示第i个基站的业务量,令
表示前i个基站中能选择的业务量为j的最大的总业务量。
如果选择第i个基站的业务量大于所需要的总业务量时,及
时,不选择i基站,此时选择前i个基站的总业务量和选择前
个基站的总业务量是一样的,即
(5)
当选择第i个基站的业务量小于所需要的总业务量时,选择第i个基站时的业务量与前
个基站的总业务量并没有达到所期望的最优总业务量,所以在选择第i个基站和不选择第i个基站之间的总服务量之间选取最优结果,即
(6)
其中的
表示不选择第i个基站的总业务量,即选择前
个基站的业务类。
表示选择了第i个基站,能选择的最大业务量减少了
,但是总业务量增加了
。
由此可得递推关系式
(7)
(8)
可以得到初始条件
,即选择前i个基站但服务容量为0和选择0个基站但服务量为j的背包价值都为0;确定好动态规划函数后,考虑函数每一次迭代的情况。
当函数迭代完成之后,
为总业务量为W的背包选择前n个基站。
通过上面的模型可以得到基站建设成本的最优解,还需要知道选择了哪些基站,所以进行回溯找到解的组成。
时,说明没有选择第i个基站,则回到
;
时,说明选择了第i个基站,该基站为最优解组成的一部分,随后回到没有选择该基站之前,即回到
;一直遍历到
结束为止,所有基站的组成都可以解得出来。
实际情况中,每个基站的信号覆盖并不是完全的圆形覆盖,而是每个站上有三个扇区,每个扇区指向一个方向。每个扇区在主方向上覆盖范围最大(半径方向),在主方向左右六十度的范围内可以覆盖,覆盖范围按线性逐渐缩小,在六十度的时候,覆盖范围为主方向覆盖范围的一半。超过六十度,则无法被该扇区覆盖。需要考虑每个站的任意两个个扇区的主方向之间的夹角不能小于四十五度,考虑现网基站的坐标点,新建站址之以及新建站址和现有站址之间的距离的门限是10。
设主方向的方向轴顶点上的坐标为
,已知基站坐标为
,根据欧式距离公式可得微基站扇形主方向最高点欧式距离为
,宏基站扇形主方向最高点欧式距离为
,则
(9)
(10)
设弱覆盖点
与原点的欧式距离为
,弱覆盖点与基站扇形主方向最高点的欧式距离为
.可得
(11)
(12)
设
和
之间的夹角为
,由余弦公式和反三角公式可得
(13)
每个站的任意两个扇区的主方向之间的夹角不能小于45度,设每个站的任意两个扇区的主方向之间的夹角为
,假设第i个扇形的主方向直线斜率为
,第j个扇形的主方向直线斜率为
,可得
(14)
(15)
两条直线之间的角度即两条直线之间的转向角,由正弦公式和反三角公式可得
(16)
由已知在主方向左右60度的范围内可以覆盖,覆盖范围按线性逐渐缩小条件,且在60度的时候,覆盖范围为主方向覆盖范围的一半这两个条件,我们可以得到与主方向轴尖角60度角半径R的线性表达式,设
(17)
其中k为半径R的线性衰减系数,
为半径R的自变量,r为基站扇区主方向最大覆盖距离,宏基站时
,微基站时
。由在60度时覆盖范围为主方向覆盖范围的一半该条件我们可以知道当该基站为宏基站时的
,
,解得
(18)
(19)
进一步考虑,把扇区的覆盖形状当成三棱形处理,以基站的站址为旋转中心进行三棱形旋转,旋转过程中以扇区覆盖的总业务量最大作为扇区旋转的停止点。设扇区旋转角度为
,则半径衰减公式变化为
(20)
在基站上任意取一个扇区做旋转变换,假设扇区主方向旋转角为
时得到第一个扇区的业务量最大,
即得到第一个扇区位置,
。第二个扇区的
取值变化为
;同理,当第二个扇区在旋转过程中得到覆盖区域内最大的业务量停止旋转,即确立了第二个扇区的位置;第三个扇区的
取值变化为
。扇区经过三次的旋转求和对比,便可以确立下每个基站的三个扇
区最佳位置。
综上所述,我们可以得到基站选址基本模型:
(21)
(22)
s.t
(23)
(24)
(25)
(26)
(27)
(28)
(29)
(30)
(31)
(32)
(33)
4. 基于DBSCA聚类算法优化的均值漂移算法
4.1. DBSCAN算法分析
DBSCAN算法是一种基于密度的聚类方法,可以找到样本点的全部密集区域,并把这些密集区域当作一个的聚类簇。如图1所示,相同颜色代表是在同一个聚类簇。DBSCAN的优势之一是它能够找到任意形状的聚类,这与其他聚类算法(例如k-means聚类算法)不同,后者假设聚类是球形的。此外,DBSCAN不需要事先指定聚类的数量,使其成为探索性数据分析的合适算法。
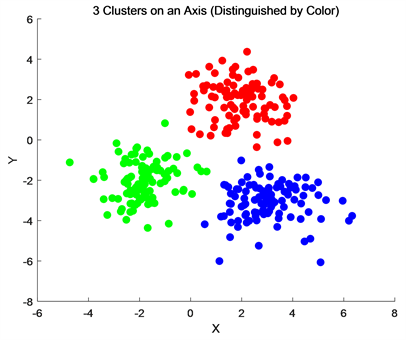
Figure 1. Each dense area clustered cluster graph
图1. 每个密集区域聚类簇图
领域半径和最少点数目这两个参数可以刻画密集程度,当领域半径R内的点的个数大于最少点数目时,就是密集。如图2中圆形区域即为领域半径
,最少点数目为13。

Figure 2. Two algorithm parameters diagram in DBSCAN
图2. DBSCAN中2个算法参数图
样本点分为核心点,边界点和噪声点。领域半径R内的样本点数量大于等于最少点数目的点称为核心的点,不属于核心点但在某个核心点的领域内的点属于边界点,既不是核心点也不是边界点的样本点为噪声点。如果P为核心样本点,Q在P的R邻域内,那么称P到Q密度直达。任何核心点到其自身密度直达,密度直达不具有对称性,如果P到Q密度直达,那么Q到P不一定密度直达。如果存在核心样本点
,且P1到P2密度直达,P2到P3密度直达,……,
到
密度直达,
到Q密度直达,则P1到Q密度可达。密度可达也不具有对称性。如果存在核心样本点S,使得S到P和Q都密度可达,则P和Q密度相连。密度相连具有对称性,如果P和Q密度相连,那么Q和P也一定密度相连。密度相连的两个点属于同一个聚类簇。
如果两个样本点不属于密度相连关系,则两个点非密度相连。非密度相连的两个样本点属于不同的聚类簇,或者其中存在噪声点。
4.2. DBSCAN算法伪代码
DBSCAN算法伪代码见表1。

Table 1. Pseudocode of DBSCAN algorithm
表1. DBSCAN算法伪代码
4.3. 均值漂移算法
4.3.1
. 算法基础公式
均值漂移的过程为不断重复计数距离均值,移动中心点,设Sh为以x为中心点,半径为h的二维圆形区域,k为包含在Sh范围内点的个数,
为包含在Sh范围内的点,则偏移均值公式为
(34)
设
为t时间下求得的偏移均值,
为t时间下的中心,则一定距离之后的中心点所处位置计算公式为
(35)
4.3.2. 算法原理及适用性分析
通过对随机选择的点周围指定半径r内的数据进行求和和记录,从而找到随机局部区域的密度极值(峰值)的方法。通过上下左右移动指定的距离
并取五个点之间的最大值重复该过程,直到中心点为最大值。将得到的密度最大点作为基站点,计算覆盖业务量。重复上述过程,直至中心点为最大值,此时该点成为该局部区域的密度极大值点。
在特征空间中初始化随机起点
,通过对点周围指定半径内的数据求和来计算的密度:
,半径内的所有数据点
求和,其中K是核函数。将起点
向最大密度梯度的方向
移动:
,其中
为步长,
为
处的密度梯度。直到中心点是最大密度或满足停止条件:
,最后收敛的点
为密度极值(峰值),可以作为基站点。
根据上述原理,可以利用均值漂移算法求出随机局部区域的密度极值点,确立该点为基站点,算出覆盖业务量,更新弱覆盖点、已有基站信息;再次求极值点,将所有新建基站覆盖业务量求和;当业务量达到总业务量的90%便停止迭代。
4.3.3. 均值算法流程图
利用聚类之后的弱覆盖点作为随机初始解集进行求解,算法流程图如图3所示。
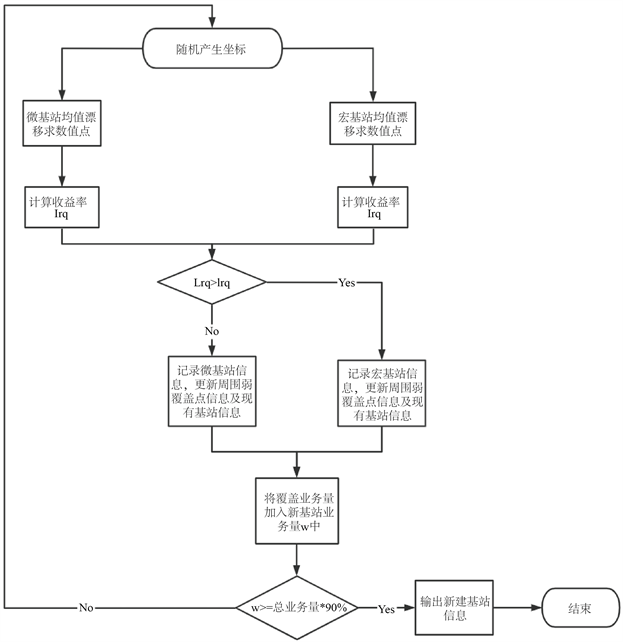
Figure 3. Mean shift algorithm flowchart
图3. 均值漂移算法流程图
5. 试验分析
5.1. 聚类结果
使用DBSCAN算法进行18万组弱覆盖点数据的处理之后,结果用时1371秒将数据分成627类,其全体的分类如图4表示。图5~8表示的为部分聚类簇取样表示,其间隔为100。图9为某城市某区域的现网覆盖情况,其中红色的区域表示为弱覆盖区域。

Figure 4. Cluster map of all weak coverage points
图4. 所有弱覆盖点聚类图
Figure 5. Partial clustering effect image
图5. 部分聚类效果图

Figure 6. Partial clustering effect image
图6. 部分聚类效果图

Figure 7. Partial clustering effect image
图7. 部分聚类效果图

Figure 8. Partial clustering effect image
图8. 部分聚类效果图

Figure 9. Current network coverage map of a certain area in a city
图9. 某城市某区域现网覆盖图
使用聚类之后的聚类中心代替原有弱覆盖点,可以得到高质量的均值漂移算法初始解集。
5.2. 均值漂移算法求解模型结果
经过多次使用均值漂移的结果对比,得到宏基站的选址和微基站的选址,其可视化结果如图10所示。图中小圆代表微基站,大圆代表宏基站。

Figure 10. Visualization of base station location selection map
图10. 基站可视化选址图
5.3. 算法适用性优化
考虑到有两种基站可供选择,确立可在同一随机区域将r定义为10和30,对应的
定义为20和60;同时进行漂移求极值点,求出对应收益率
和
比较两个收益率,留下较大的。这样可以尽可能减小成本,增大效益。
基站选址与已有基站之间的欧式距离必须大于10,所以在进行均值漂移时,需要判断是否能建基站;若不能,则将此点覆盖业务量记为0。采用DBSCAN算法对初始解集进行聚类之后,均值漂移算法的迭代次数明显下降,传统均值漂移算法和优化后均值漂移算法效果对比图如图11所示。

Figure 11. Comparison of the effects of two algorithms image
图11. 两种算法效果比较图
6. 结论
基站选址是当今通信服务的一个重要环节,本文对基站选址问题进行了分析,以区域总业务量达到最大以及基站建设成本最低为指标建立了最优化模型,并提出一种基于DBSCAN聚类算法优化后的均值漂移算法,求解最优基站建设方案。试验结果表明,本文提出的方法能有效提高优化效率,对基站选址具有一定的实用性。