1. 引言
中国铁路串点成线,连线成网,四通八达,覆盖面极广,如今已逐渐形成“八纵八横”的高铁网,交通大动脉越来越畅通。并且随着城市间人口流动性增强和由于经济发展带来的生活节奏的加快,人们对于交通速度也有着一定的追求。而铁路运输具备运量大、方便快捷、安全系数高等特点,通常会成为人们远途出行的首选方式。对铁路未来的客流量进行较为准确的预测,是铁路线路设计、场站规划、铁路运营的工作基础。通过算法模型预测出来的数据,是车辆运输规划和人员安排的决策依据,有助于在能够满足运输需求的前提下,减少资源的浪费,应对节假日期间客流突增的情况。因此,准确预测铁路客流量对于车站的长期发展具有非常重要的意义。尤其是在2020年1月,突如其来的疫情给铁路客运带来巨大冲击,中断了客流量逐年增加的趋势 [1] 。根据铁路营销信息网站的数据,秦皇岛站铁路客运量从2020年1月24日开始大幅下降,1月客运量累计39.4233万人次,较2019年同比下降12.20%,2月客运量累计3.6683万人次,较2019年同比下降90.81%。随着国内疫情有所好转,铁路客流逐渐增加,应用建立好的模型对未来客流进行预测,有助于疫情恢复阶段铁路运营工作的顺利展开。
目前,学者们对客运量的预测进行了深入的研究。如:蔡倒录等提出采用自回归移动平均模型(ARMA)预测新疆铁路客运量,拟合效果理想 [2] 。赵鹏等构建自回归综合移动平均模型(ARIMA)在对北京地铁站进行客流预测时具有很高的预测精度 [3] 。段然等考虑到客流量数据的周期性,选用季节性差分自回归滑动平均模型(SARIMA)对某铁路站点非节假日的客流数据进行短期预测,拟合效果良好 [4] 。王小凡等对青岛市铁路客运量分别建立多元回归模型和BP神经网络模型,通过比较证明了BP神经网络模型的预测效果更优 [5] 。桂文毅基于灰色线性回归模型预测哈尔滨铁路枢纽的客运量,经验证预测数据可靠 [6] 。由于客运量数据的特征较为复杂,仅用单一模型预测会有一定的局限性,对此许多学者构建组合模型,并证明其有效性和实用性。如:Gliovi等提出了基于人工神经网络和遗传算法的组合模型,预测塞尔维亚的铁路月客运量 [7] 。Li以IOWHA算子概念为基础,提出了基于ARIMA-REGRESSION的组合预测方法,对中国民航年客运量进行预测,证明比单一模型有更高的预测精度 [8] 。张蕾将支持向量回归(SVR)、SARIMA模型和霍尔特–温特斯模型(Holt-Winters)进行两两组合,讨论发现每种组合模型的预测效果均优于单一模型 [9] 。张玺君等提出了基于SARIMA-GA-Elman的组合预测模型,研究结果表明其预测效果和单一模型相比有明显提升 [10] 。
目前对铁路客运量预测的研究多为月统计数据和年统计数据,虽保证了较高的预测准确度,但降低了对相关部门制定短期规划的参考价值。并且疫情在很大程度 上影响了客运量数据的变化趋势。据此,论文采集了后疫情时期秦皇岛站日客运量数据,根据其具有线性特征和非线性特征,提出了采用SARIMA模型和Holt-Winters模型对客运量进行短期预测。随后运用方差倒数法,建立加权组合模型,并对三种模型的预测效果进行比较分析。
2. 数据来源及白噪声检验
本文研究使用的秦皇岛市铁路车站客运量数据来源于铁路营销信息网站。以2020年1月24日~2022年4月15日共812天的逐日客运量数据为样本数据,利用Rstudio软件绘制数据序列,如图1所示。从图中可以看出,后疫情时期的客运量整体上呈波浪式变化和先增后减的变化趋势,样本数据的均值、方差波动较大,初步判断该客运量序列非平稳且受季节效应的影响。

Figure 1. Timing diagram of daily passenger volume from January 24, 2020 to April 14, 2022
图1. 2020年1月24日~2022年4月14日逐日客运量时序图
对序列进行因素分解,来推断出各种因素对序列的综合影响,结果如图2。由因素分解图可以发现,该序列受季节因素和随机因素影响,有一定的周期性。但由于疫情期间,铁路相关政策在很大程度上会对客运需求产生影响,在短时间内使其发生较大变化,所以没有明显的长期趋势。同时,从因素分解图中也能看出,数据中的季节趋势没有取决于数据的变动,可认为客运量的日度数据具有一定的季节性特征,即在周日出现高峰,在周二出现低谷。故本文初步选择SARIMA模型和Holt-Winters模型分析样本数据,探索最适合拟合预测秦皇岛站铁路客运量的时间序列模型。
先对时间序列进行白噪声检验。采用LB检验,对该序列做延迟6阶、12阶、18阶的白噪声检验,结果如表1所示。P值均小于0.05,拒绝原假设,由此判断该序列非白噪声。
3. 模型建立与比较分析
3.1. SARIMA模型预测
绘制原始序列的ACF和PACF图,如图3所示。观察ACF图,发现自相关系数长期位于正值的一边,同时自相关图还隐约周期为7的波动规律。这两个特征常存在于具有周期性的非平稳序列中,并且与原序列的时序图(图1)的趋势和特点十分吻合。
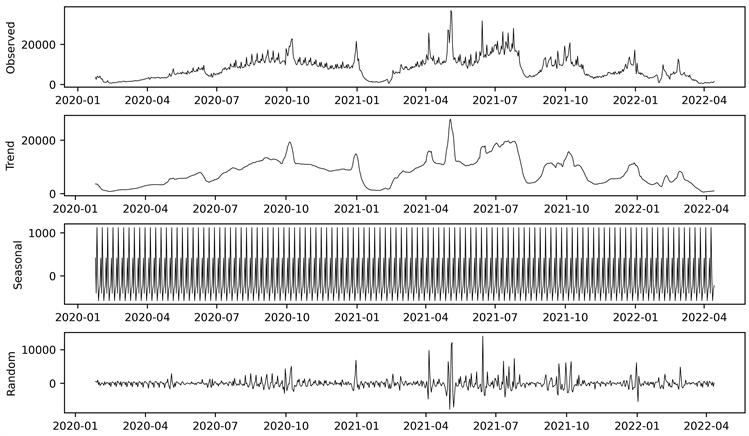
Figure 2. Factor decomposition diagram of sample data time series
图2. 样本数据时间序列因素分解图

Table 1. LB test results of the time series
表1. 时间序列的LB检验结果
由于序列没有明显的长期趋势,所以需要进行一阶7步差分来消除季节性。差分后的时序图、ACF图和PACF图如图4所示。相比于图1原始序列的时序图,变换后序列的均值和方差的波动明显减小,趋势更加平稳。ACF和PACF不呈周期性震荡,说明经过一阶季节差分,季节性已被消除。同时,ACF图呈现出稳定模型具有的“伪周期”特征。

Figure 3. ACF and PACF diagrams of the original time series
图3. 原始时间序列的ACF和PACF图


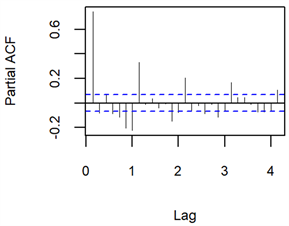
Figure 4. Timing diagram, ACF diagram and PACF diagram after the first order 7-step seasonal difference
图4. 一阶7步季节差分后的时序图、ACF图和PACF图
进一步对季节差分后的序列进行ADF检验,结果如表2所示。由统计量小于不同显著性水平下的临界值,P值接近于0,拒绝非平稳的原假设,可判断出此的序列平稳,可以满足建立SARIMA模型的平稳性需求。
Table 2. LB test results of the time series
表2. 时间序列的LB检验结果
SARIMA模型的表达形式为SARIMA(p,d,q)(P,D,Q)s。其中,在非季节性模型部分,参数p、d、q分别为自回归阶数、逐期差分阶数和移动平均阶数,在季节性模型部分,参数P、D、Q分别为季节性自回归阶数、季节性分阶数和季节性移动平均阶数,S为周期长度。SARIMA模型的一般表达式为:
其中,B为后移算子,
为一个白噪声序列,且
由平稳性检验结果可以确定d = 0,D = 1,S = 7。图4的ACF图显示,自相关系数在滞后5阶后减为0,则q取5。其在滞后7阶有明显的突起,则Q = 1。PACF图显示,偏自相关系数1阶后截尾,故p取1,其在延迟7阶、14阶和21阶时在2倍标准差范围之外,则P取3。初步对铁路客运量序列建立SARIMA(1,0,5)(3,1,1)7模型。
但图定阶法有较强的主观性,所以还要通过AIC准则进一步较为客观的判断模型阶数的优劣。AIC准则是将参数个数和拟合精度加权后得到的参数,AIC函数值越小,参数个数和拟合精度的配置越优。对SARIMA(1,0,5)(3,1,1)7模型的p、q、P和Q在就近范围内适当增减,综合考虑AIC值和预测误差的大小,将SARIMA(1,0,5)(5,1,0)7定为最优模型,此时AIC值为14593.96。对残差序列做延迟6阶的白噪声检验,得出P值为0.9994,大于显著性水平0.05,表明该模型显著成立,SARIMA(1,0,5)(5,1,0)7模型对客运量序列拟合效果良好。SARIMA(1,0,5)(5,1,0)7模型中各参数值如表3所示。
Table 3. Parameter values of the SARIMA model
表3. SARIMA模型的各参数值
综上,可以得到模型口径为:
使用SARIMA(1,0,5)(5,1,0)7模型预测2022年4月15日~2022年4月29日共15天的秦皇岛车站铁路日客运量。在计算出预测值后,使用平均绝对百分比误差(MAPE)来评估模型预测结果的优劣。因为平均绝对百分比误差在避免了正负误差相互抵消的同时,能够直观地体现出误差与真实值间的相对程度,反映预测的准确度,且不依赖于其他指标。MAPE越小,说明模型的预测效果越好。平均绝对百分比误差(MAPE)的计算公式为:
式中,
为第t期的真实值,
为第t期的预测值,
。真实值和预测结果如表4所示。
由表4可以看出,基于SARIMA模型的铁路日客运量预测值与真实值的最小相对误差为1.0585%,最大相对误差为27.4035%,其中4月24日的误差偏大,其他时间的误差适中,MAPE为8.9761%,总体的预测准确度较高。
Table 4. Forecast of daily passenger volume of railway stations by SARIMA model from April 15 to April 29, 2022
表4. 2022年4月15日~4月29日铁路车站日客运量SARIMA模型预测
3.2. 公式Holt-Winters模型预测
Holt-Winters三参数指数平滑法是Holt两参数指数平滑的延伸,其公式涵盖了时间序列的水平、趋势以及季节性构成,它包括加法模型和乘法模型两种,可以修匀含有季节效应的序列。借助指数平滑法,可以对长期趋势、趋势增量和季节变动做出估计,并能适当过滤掉随机波动的影响。因此,根据客运量序列具有季节效应,但没有明显长期趋势的确定性特征,选择使用Holt-Winters三参数指数平滑模型来预测序列未来发展。
由因素分解图2可以看出,客运量数据趋势附近的波动程度随时间的变化逐渐减小,所以选择使用乘法模型。Holt-Winters乘法模型的构造如下:
式中at是稳定成分,通过季节因子的修正消除季节变化的影响,为序列的拟合值;rt是趋势部分,为序列变化趋势的指数平滑平均数,将当前一期与上期的趋势增量做加权平均,是对趋势增量的估计;st是季节部分,为季节因子的指数平滑平均数,对当前季节因子和上一个相同季节的季节因子的加权平均,进一步改善季节变化对预测值的影响;k是向后平滑的期数。at、rt、st的计算公式如下:
式中yt是t时刻的真实值,α、β、γ为平滑系数,取值范围为(0,1),π为一个季节周期长度,对于客运量日度数据,π = 7。
以2020年1月24日~2022年4月15日的逐日客运量数据为原始数据,利用Rstudio软件对原始数据进行拟合,以平均相对误差最小为目标函数,经过多次的迭代求解,最终在α = 0.91,β = 0.06,γ = 0.28时,可以得到最优解。α值接近于1,表明近期观测值的权重较大,历史观测值的权重较小。β值接近于0,表明在整个时间序列上,趋势部分的水平和斜率没有发生太大变化。γ值在0~0.5之间,表明序列近期的观测值受到季节性的影响较小。使用该模型预测的2022年4月15日~2022年4月29日共15天的秦皇岛车站铁路日客运量,真实值和预测结果如表5所示。
由表5可以看出,基于Holt-Winters乘法模型的铁路日客运量预测值与真实值的最小相对误差为1.0520%,最大相对误差为27.7829%,其中4月16日~4月18日的误差偏大,其他时间的误差适中,平均相对误差为9.1912%,总体的预测准确度较高。对比前后两个预测模型的预测结果,可以发现,SARIMA模型的精度略高于Holt-Winters模型。
Table 5. Forecast of daily passenger volume of railway stations by Holt-Winters multiplicative model from April 15 to April 29, 2022
表5. 2022年4月15日~4月29日铁路车站日客运量Holt-Winters乘法模型预测
3.3. 组合模型预测
上述研究表明,通过建立的两个单一的时间序列模型预测均可以进行铁路客运量的短期预测,但由于不同模型的特点和局限性,会使得各个预测结果有显著差异。如果采用组合预测模型,就可以充分利用每个单一模型提取到的序列信息。在构建组合模型时,选择合适的权值,可以有效提高模型预测精度,常用的权值计算方法有等权值法、方差倒数法、方差–协方差法、最优加权法等。由于方差倒数法易于操作,且效果好,所以本文使用该方法计算单项模型的权重。一般情况下,每种单一预测模型的预测精度各不相同,而误差平方和作为判断模型预测精度的重要指标,它越大,说明该单一模型的精度越低,其在组合模型中的重要性就越低,应在组合预测中赋予较小的加权系数。
假设观测对象为X,对其有m种预测方法。Xt为真实值序列中第t期的实际观测值,xit为第i种预测方法对第t期的预测值,wi为第i个单项预测模型在组合预测模型中的权重系数,则组合预测模型为
方差倒数法的权重系数计算公式为
式中,
,且
。
通过权重公式,分别计算出SARIMA(1,0,5)(5,1,0)7模型和Holt-Winters乘法模型的权重,结果为w1 = 0.61,w2 = 0.39,则铁路客运量的组合预测模型为
由该公式计算出组合预测模型的预测结果如表6所示。
Table 6. Forecast of daily passenger volume of railway stations by combining model from April 15 to April 29, 2022
表6. 2022年4月15日~4月29日铁路车站日客运量组合模型预测
从表6中可以看出,组合模型的最大相对误差、最小相对误差和MAPE都比单一模型更小。和SARIMA模型相比,虽然组合模型部分预测值的相对误差更大,但是后半段组合模型的预测精度有明显提高,MAPE减小了0.5885%。和Holt-Winters模型相比,除了4个预测值的相对误差更大,其余预测值的预测精度均为更优,MAPE减小了0.8036%。综上,与单一模型相比,由方差倒数法得到的组合模型的预测效果最好。
4. 样本量对预测效果的影响
考虑到铁路客运量数据包含的信息量大,样本量过多,会导致数据提取时间过长的问题,以下选择用不同的样本量对客运量进行预测,分析样本量对预测效果的影响。对2020年1月26日~2022年4月15日810个样本量的秦皇岛站铁路客运量数据,以30日为间隔,设置26个梯度样本量(60、90、120、150、180、210、240、270、300、330、360、390、420、450、480、510、540、570、600、630、660、690、720、750、780、810)。即从2022年2月14日的数据开始往前递推,用不同梯度的样本量,分别使用SARIMA模型、Holt-Winters乘法模型和组合模型预测2022年4月15日~2022年4月29日的客运量。
如图5所示,当样本量为60~480日时,随着样本量的增加,三个模型的MAPE的波动都非常大,且没有明显趋势。MAPE波动最大的为Holt-Winters模型,变化范围为9.0233%~36.3749%。MAPE波动最小的为组合模型,变化范围为8.1713%~17.8342%。当样本量大于480日时,三个模型的MAPE都趋于稳定,基本维持在10%以下,且组合模型的MAPE一直保持为三者中最低。同时可以看出,在26个梯度样本量中,有20个梯度样本量下为组合模型的MAPE最小,约占比77%,说明将SARIMA模型和Holt-Winters模型组合起来具有合理性,可有效提高预测准确度。

Figure 5. Comparison between sample size and MAPE in three predictive models
图5. 三种预测模型中样本量与MAPE的对比关系
由此可见,样本量对预测的准确度有明显贡献,当样本量达到480日以上时,三个模型基本都可以达到90%的预测准确度,并且使用组合模型进行预测,准确度最高。
5. 结论
本文结合研究背景和现状,提出了铁路客运量预测存在的问题。随着疫情的出现,秦皇岛站铁路客运量变化巨大,使用过去的预测模型显然不合理,所以针对后疫情时期的铁路客运量建立了新的时间序列模型。由于客运量序列具有明显的季节性和周期性,所以本研究建立了SARIMA模型和Holt-Winters模型。经过检验,两个模型预测出的结果都很接近真实值。且当样本量足够大时,若进一步使用方差倒数法,将以上模型组合起来,通过让正负误差相互抵消,还可以再提高预测准确度。
由此可见,对于客运量序列的预测,进行线性模型和非线性模型的组合,可以取得良好的预测效果。进一步的研究会考虑在此背景下,丰富单一模型的种类,让信息提取更加充分,为制定客运量的预测方法提供新思路。