1. 引言
不同于债券和基金,股票投资是一种高风险、高收益的投资方式。由于股价受经济波动、行业趋势、市场情绪和意外事件等多方面因素的影响,仅凭人为经验对股价进行预测准确度较低,因此如何准确地预测股价一直备受研究人员与投资者的关注。不少研究者尝试采用基本面和资金面分析 [1]、ARIMA [2] 和GARCH [3] 等传统的方法来预测股票价格。然而传统股票预测方法存在滞后性强、无法捕捉非线性关系和预测精度低等问题。近年来,随着机器学习技术的不断发展,研究者们开始尝试将机器学习技术应用在股票预测领域。Lv J.,等人设计了一个LightGBM优化的LSTM来实现短期股价预测 [4];Mukherjee, S.等人利用卷积神经网络(CNN)模型预测股票价格 [5]。
然而,现有的基于机器学习的股价预测方法忽略了不同均线之间的关联对股价的影响。例如,短期均线与一条或者多条中期均线交叉所形成的交叉点称为黄金十字,在金融领域里称为“金叉”。当出现这种信号时,则意味着股票价格即将上涨。这时,投资者可以在交叉点刚刚形成的时候买入;相反,短期均线和一条或者多条中期均线交叉所形成的交叉点称为“死叉”。当出现这种信号时,则意味着股票价格即将下跌。这时,应该立即将股票卖出。此外,均线与K线之间的位置关系也会对股市和个股价格产生影响。例如,在上涨行情中,5日、10日和20日均线自下而上依次顺序排列,向右上方移动,称为“多头排列”,预示股价将大幅上涨;在下跌行情中,5日、10日和20日均线自上而下依次顺序排列,向右下方移动,称为“空头排列”,预示股价将大幅下跌。针对现有的股价预测方法忽略不同K线和均线之间的关联对股价的影响而导致的预测精度不佳的问题,本文基于卷积自动编码器(Convolutional Autoencoder, CAE)和门控循环神经网络(Gate Recurrent Unit, GRU)模型提出了一种利用K线和均线特征的关联性预测股价的方法。其中,K线特征包括当日开盘价、收盘价、最高价和最低价。本方法通过烛台图的形式表征股票K线特征。CAE模块从绘制的烛台图中提取短期、中期和长期深度K线特征。本方法选取5日、10日和20日均线分别作为短期、中期和长期均线特征。GRU模块将短期、中期和长期深度K线特征的均线数据作为输入以学习当前交易日的深度K线特征与均线特征。本方法将学习的当前交易日的深度K线特征与均线特征和选取的基本面特征送入全连接层,得到预测的股价。
综上所述,本文相关的贡献如下:
1) 本文对每个数据样本以5日、10日和20日为单元进行划分,绘制烛台图并利用CAE模块分别学习短期、中期和长期深度K线特征。该方式保证CAE模块能够以不同的时间粒度提取准确的深度K线特征,为后续精确地股价预测奠定基础。
2) 本文将短期、中期和长期深度K线特征分别与短期、中期和长期均线数据堆叠作为GRU模块的输入以学习当前交易日的深度K线特征与均线特征。该方式使得GRU模块能够学习短期、中期和长期均线与K线的位置关系,有利于提高股价预测的精度。
3) 本文将CAE网络、GRU网络和未经划分的CAE + GRU网络作为对比对象,分析了本方法与其在MAE、MAPE和MSE评价指标的性能。实验表明,本方法在上证指数数据集上具有更好的拟合和泛化性能,能够有效地减小预测误差。
2. 相关工作
2.1. 传统的股票预测方法
如何准确预测股价一直以来成为国内外研究者关注的热点。研究者们先后采用基本面和资金面分析、ARIMA和GARCH等传统的时间序列方法来预测股票的价格。Chen Y.J.等人考虑了公司财务状况、工业环境、宏观经济和金融新闻等因素,设计出一种基于基本面分析的股票市场预测方法 [6]。该方法可用于计算财务指标的权重,根据股票特征评估和选择个股;方坷昊利用ARIMA模型对股票进行预测,将得到的预测值归为原始变量组,并加入相关变量,再结合偏最小二乘回归进行建模分析。通过实验,利用该组合方法能够得到更好的修正模型 [7];周丹文对恒生指数近10年的收盘价进行分析,建立GARCH模型,模拟了该指数波动性变化 [8]。结果表明,在短期内,该模型拥有较好的预测效果。然而,传统的股票预测方法存在神经网络收敛速度慢、预测精度较低等问题。为了进一步提高预测精度,不少研究者利用机器学习技术进行股票预测。
2.2. 基于机器学习的股票预测方法
随着人工智能技术日渐成熟,越来越多的研究者采用机器学习技术来预测股价。Tabak B.M.等人利用K最近邻(KNN)和支持向量机(SVM)模型预测次日股价 [9]。通过实验对比分析,SVM模型具有更强的泛化能力;方昕等人首先利用粒子群算法提取股票数据的特征,然后用传统的随机森林算法和网格算法改进后的随机森林算法对沪深300和中证500指数进行预测 [10]。通过实验对比分析,改进后的随机森林算法预测精度显著提升;Xie L.提出了一种基于CAE的无监督学习框架来预测金融时间序列领域的每日股价趋势。其中,CAE主要通过编码和解码来提取高级语义特征 [11];Ni J.等人基于循环深度神经网络(RDNN)和DCC-GARCH模型开发了一种称为DCDNN的混合模型 [12]。该混合模型能够准确预测股票之间的相关性;Hung C.C.等人提出了DPP框架,该模型以烛台图作为输入,接着通过CAE提取股票具有代表性的特征,最后通过GRU预测价格走势 [13];綦方中提出了一种基于PCA和IFOA-BP神经网络的股价预测模型 [14],与其它模型相比,该模型具有更快的收敛速度和更高的预测精度;许雪晨等人利用预训练模型BERT对股票新闻文本进行情感分析,并通过LSTM模型预测股价走势 [15]。然而,现有的基于机器学习的股票预测方法忽略了不同K线和均线之间的关联对股价的影响。因此,希望通过考虑该因素使得预测精度得到进一步提升。
3. 方法
现有的基于机器学习的股票预测方法忽略了不同K线和均线之间的关联对股价的影响。为了解决该问题,本文提出了一种基于CAE和GRU模型的股价预测方法。该模型由CAE、GRU和全连接层组成。首先对每个数据样本以5日、10日和20日为单元进行划分,绘制烛台图并利用CAE模块分别学习短期、中期和长期深度K线特征;然后将CAE模块学习到的深度K线特征与均线特征堆叠作为GRU模块的输入以学习当前交易日的深度K线特征与均线特征;最后将选取的基本面特征和当前交易日的深度K线特征和均线特征送入全连接层,得到预测的股价。该方法的网络结构图如图1所示。

Figure 1. Network structure chart of stock price forecasting method based on CAE and GRU model
图1. 基于CAE和GRU模型的股价预测方法的网络结构图
3.1. 数据预处理
本文使用上证指数的开盘价、收盘价、最高价和最低价作为原始数据。数据集中的每个样本包含30个交易日内的开盘价、收盘价、最高价和最低价的数据。为了使得网络模型具备学习均线交叉以及均线与K线之间的位置关系对股价影响的能力,因此需要对原始数据进行预处理。
本方法通过绘制烛台图反映股票的K线特征。烛台图可由开盘价、收盘价、最高价和最低价表示,如图2所示。烛台图描述了给定时间段内股票价格的波动情况。其中,每根柱线代表一个交易日的信息。烛台的不同颜色代表不同的含义,如果开盘价高于收盘价,实体将以白色填充;否则,实体将以黑色填充。
本方法将每4列描述一个交易日的K线特征,它通过将开盘价、收盘价、最高价和最低价转换为二维数组的方式绘制给定时间段为m天的烛台图。因此,烛台图的列数为4m。对于每一个交易日的K线特征,第一列代表开盘价;第二列代表高低价区间;第三列代表收盘价;第四列代表间隔列。烛台图的每行为给定时间段m天内最高价(记为
)与最低价(记为
)之间的均匀分割。假设某日的K线特征值为Ρ,本方法按照公式(1)所示的规则构建二维数组。
(1)
其中 指股票价格(0 ≤ k < 4m),l指天数(0 ≤ l < 4m)。
本方法绘制的给定时间段为5天的烛台图示例如图3所示。

Figure 3. Example of a candlestick chart for a given time period of 5 days
图3. 给定时间段为5天的烛台图示例
依据该方法,本文以5日、10日和20日为给定时间段分别绘制尺寸为20 × 20、40 × 40和80 × 80的烛台图来反映短期、中期和长期K线特征。
本文通过5日、10日和20日均线分别表示短期、中期和长期均线特征。其中,5日均线指连续5个交易日的收盘价的平均值。公式如(2)所示:
(2)
10日均线指连续10个交易日的收盘价的平均值。公式如(3)所示:
(3)
20日均线指连续20个交易日的收盘价的平均值。公式如(4)所示:
(4)
其中ci指的是第i天的收盘价。
除此以外,本文额外选取MACD、RSI、MOM和成交量四种基本面特征,研究其对于股价的影响。
3.2. 模型构建
本方法将上述提及的烛台图、均线以及基本面特征作为模型的输入。该模型首先对每个数据样本以5日、10日和20日为单元进行划分,绘制烛台图并利用CAE模块分别学习短期、中期和长期深度K线特征;然后将CAE模块学习到的深度K线特征与均线特征堆叠作为GRU模块的输入以学习当前交易日的深度K线特征与均线特征;最后将选取的基本面特征和当前交易日的深度K线特征和均线特征送入全连接层,得到预测的股价。
3.2.1. 卷积自动编码器
卷积自动编码器(CAE)是一种编码器–解码器架构的神经网络,被广泛用于图像和视频处理中的特征学习,但在股票预测应用中并不常见。本文采用的CAE具体结构及对应参数如图4~6所示。在编码过程中,本文使用多个二维卷积层和最大池化层从表征短期、中期和长期K线特征的烛台图中分别学习短期、中期和长期深度K线特征。在解码过程中,本文通过反池化操作重新构建烛台图,使得其与原烛台图尽可能相似。具体而言,本文采用的CAE模块的输入分别为5日、10日和20日的烛台图,它们的维度大小分别为20 × 20 × 1、40 × 40 × 1和80 × 80 × 1。本文采用的CAE模块的编码网络和解码网络由多个二维卷积层和最大池化层组成。其中,采用的二维卷积层和最大池化层的参数如图4~6所示。CAE模块通过编码过程分别从5日、10日和20日的烛台图中提取维度为5 × 5 × 64的深度K线特征。
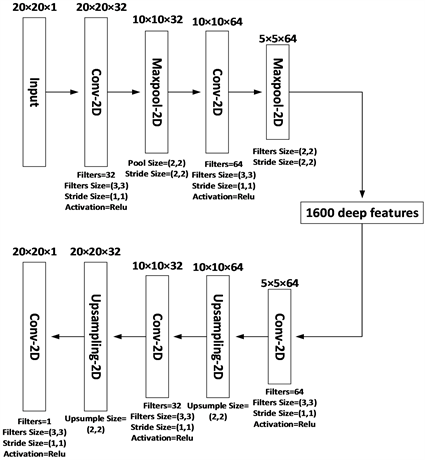
Figure 4. The specific structure and corresponding parameters of CAE with 5 days as the division unit
图4. 以5日为划分单元的CAE具体结构及对应参数
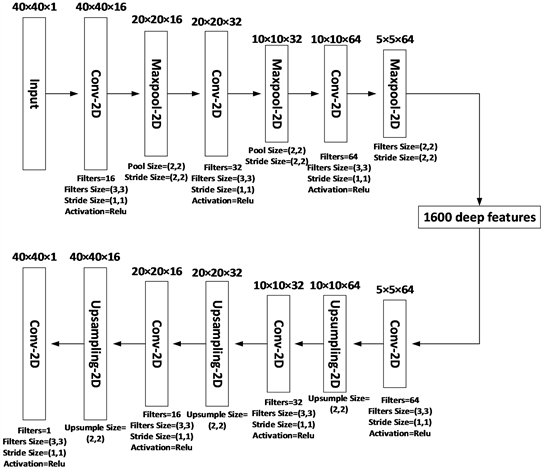
Figure 5. CAE specific structure and corresponding parameters with 10 days as division unit
图5. 以10日为划分单元的CAE具体结构及对应参数
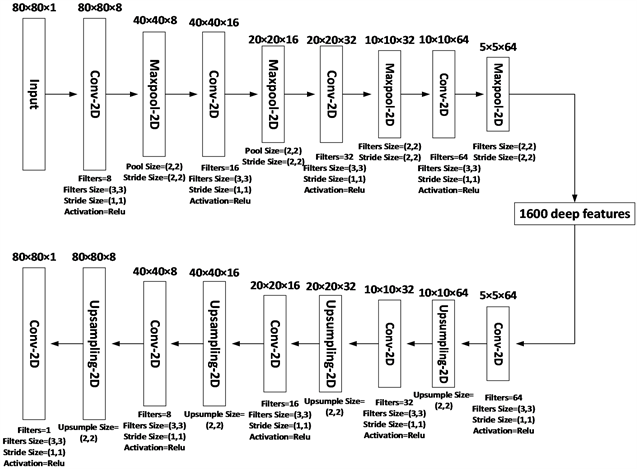
Figure 6. CAE specific structure and corresponding parameters with 20 days as division unit
图6. 以20日为划分单元的CAE具体结构及对应参数
3.2.2. 门控循环神经网络
相较于LSTM,门控循环神经网络(GRU)通过将输入门和遗忘门合并为更新门的方式进一步提高了运行效率。因此,本文采用GRU模块根据CAE模块提取的深度K线特征以及数据预处理得到的均线数据,学习当日的深度K线特征和均线特征以预测股价。具体而言,本文将CAE模块根据烛台图提取的短期、中期和长期深度K线特征分别与数据预处理得到的短期、中期和长期均线数据进行堆叠以作为GRU模块的输入。如图7~9所示,5日、10日和20日的GRU模块分别包含26、21和11个GRU单元。每一个GRU单元包含128个隐藏特征,激活函数选用tanh激活函数。GRU模块的输出为当前交易日的深度K线特征和均线特征。

Figure 7. Specific structure and parameters of GRU module with 5 days as division unit
图7. 以5日为划分单元的GRU模块具体结构及参数

Figure 8. Specific structure and parameters of GRU module with 10 days as division unit
图8. 以10日为划分单元的GRU模块具体结构及参数
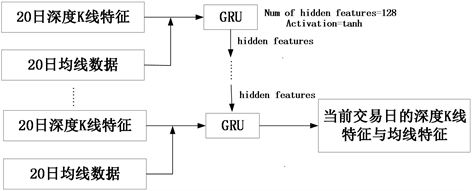
Figure 9. Specific structure and parameters of GRU module with 20 days as division unit
图9. 以20日为划分单元的GRU模块具体结构及参数
3.2.3. 全连接层
本文通过在GRU模块后连接一个全连接层以学习当日的股票价格。具体而言,如图10所示,该全连接层的输入为GRU模块学习得到的当日深度K线特征和均线特征以及预处理得到的基本面特征;输出为表征当日股价的1个神经元。本文选取Sigmoid函数作为全连接层的激活函数,其公式如(5)所示:
(5)
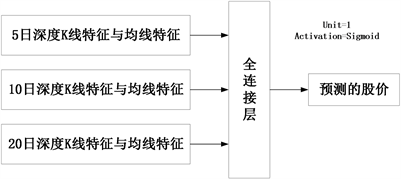
Figure 10. The specific structure and corresponding parameters of the full connection layer
图10. 全连接层的具体结构及对应参数
3.2.4. 损失函数
本文的损失函数由CAE模块的损失函数和全连接部分的损失函数组成。为了使得CAE模块能够通过编码器从输入的烛台图中学习到准确的深度K线特征,需要保证通过CAE模块解码器得到的烛台图与输入的烛台图尽可能相似。因此,本文选取二元交叉熵作为CAE模块的损失函数,其公式如公式(6)所示:
(6)
其中p指真实分布,q指预测分布。
为了使得本文采用的全连接层能够准确地预测股价,需要保证通过训练得到股价的预测值与真实值尽可能相似。因此,本文选取MSE作为全连接层的损失函数,其公式如公式(7)所示:
(7)
其中,n为样本数,
为样本真实值,
为模型预测值。
4. 实验分析
4.1. 数据及模型参数
4.1.1. 数据来源
本文将近30年来(即从1992年1月1日至2021年12月31日)的中国上证指数作为数据集。其中,每个数据样本包含单个交易日的开盘价、收盘价、最高价和最低价。上证指数的交易数据从财经数据接口包Tushare (https://www.tushare.pro)获取。
4.1.2. 数据预处理
为了消除不同的量纲和量纲单位在特征数据计算时产生的差异,在训练前,本文将原始数据样本中的特征数据进行归一化处理,数据归一化的公式如(8)所示:
(8)
其中,Χ为股票的价格,
为股票价格的最大值,
为股票价格的最小值。
另外,由于财务报告的缺失、计算错误等原因,很可能造成数据的丢失,从而会影响数据分析的准确性。因此,缺失值的预处理非常重要。本文采用填充法对缺失值进行处理,如果当前交易日的某个特征数据为缺省值,则用前一个非缺省的特征数据值进行替换。
经过预处理后,数据根据比例划分为训练集、验证集和测试集。其中,前80%的数据作为训练集用来训练模型,之后10%的数据作为验证集用来调整模型的参数,最后10%的数据作为测试集用来评估模型的预测效果。
4.1.3. 评价指标
在实验过程中,为了评估模型的预测性能,本文主要使用三种不同的评估指标:平均绝对误差(MAE)、平均绝对百分比误差(MAPE)和均方误差(MSE)。三种指标的计算公式如公式(9)至公式(11)所示:
(9)
(10)
(11)
其中,n为样本数,
为样本真实值,
为模型预测值。
4.1.4. 实验环境与参数设置
本文的硬件实验环节为一台装备4个Intel(R) Xeon(R) Silver 4114 CPU @ 2.20GHz (40核CPU),4块16GB DDR4 memory (64 GB内存),4块WD Black 1TB硬盘和2块NVIDIA GTX 1660S GPU的高性能服务器。
本文的软件实验环境为Tensorflow-gpu 2.0.0下的keras 2.8.0深度学习框架,配置NVIDIA CUDA 10.0,cuDNN7.6.4深度学习库加速GRU计算,python版本为python3.7。在训练弱学习器时采用RMSprop作为优化器,学习率设置为0.001。模型采用200个epochs,每个batch的大小为64。
4.2. 上证指数预测结果分析
本文的数据集由三部分组成。其中,1992年1月1日至2015年12月31日的股价数据作为训练集;2016年1月1日至2018年12月31日的股价数据作为验证集;2019年至2021年12月31日的股价数据作为测试集。本文将CAE网络、GRU网络和未经划分的CAE + GRU网络作为对比网络模型,从而说明本方法在预测上证指数股价的有效性。具体实验结果如表1所示。

Table 1. Standard test system result data
表1. 标准试验系统结果数据
由表1可知,本文所提出的模型在各评价指标中都取得了良好表现,总体效果均优于其它对比模型。本文方法与CAE网络相比,在预测股价时考虑GRU获取的股价时间序列数据的特征,因此本文方法的预测效果较好;本文方法与GRU网络相比,在预测股价时考虑CAE从烛台图中提取的深度K线特征,因此本文方法的预测效果较好;本文方法与未经划分的CAE + GRU网络相比,在预测股价时考虑短期、中期和长期均线数据与K线特征之间的关联,因此本文方法的预测效果较好。
综上所述,本文利用CAE模块提取的短期、中期和长期的深度K线特征以及GRU模块学习的短期、中期和长期均线数据与K线特征之间的关联进行股价预测。因此,本文方法的预测效果很好,更接近真实值,预测误差更小。
图11~14分别为本文方法、CAE网络、GRU网络和未经划分的CAE + GRU网络在上证指数测试集上的股价预测结果。其中,横坐标表示测试集数据样本的索引,纵坐标表示经过归一化处理后的股票收盘价数值。由图可以看出,本文所研究的模型在预测值与实际值的拟合度上表现较好,其预测性能明显高于其他对比模型的预测性能。该模型不仅能获取股票未来趋势,而且在股票的总体总势变化较大的拐点预测正确。因此,通过参考股价收盘价的预测值进行股票交易,能够有效提高股民的收益和降低投资风险。
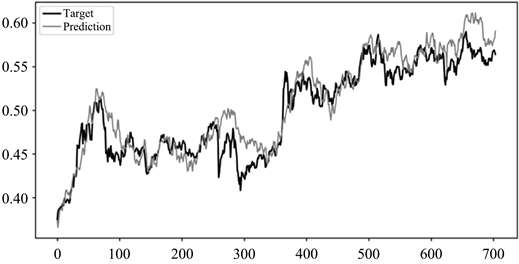
Figure 11. Effect chart of CAE network’s stock price forecast on the Shanghai stock index test set
图11. CAE网络在上证指数测试集上的股价预测效果图
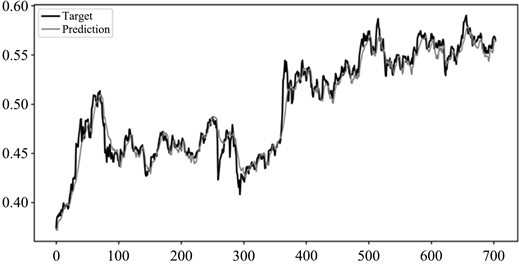
Figure 12. Effect chart of GRU network’s stock price forecast on the Shanghai stock index test set
图12. GRU网络在上证指数测试集上的股价预测效果图
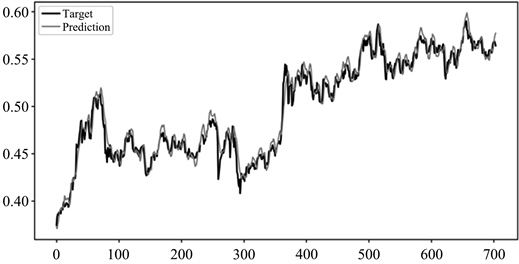
Figure 13. Effect chart of stock price forecast of undivided CAE + GRU network on shanghai stock index test set
图13. 未经划分的CAE + GRU网络在上证指数测试集上的股价预测效果图
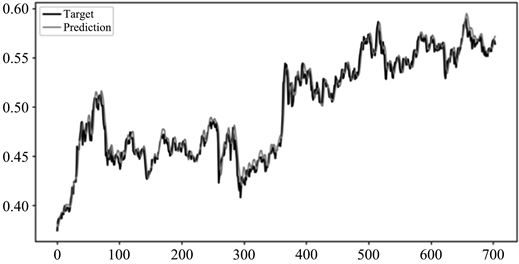
Figure 14. Effect chart of stock price forecast based on the test set of Shanghai stock exchange index
图14. 本文方法在上证指数测试集上的股价预测效果图
5. 结语
本文基于CAE和GRU模型提出了一种利用K线和均线特征的关联性预测股价的方法。
本方法首先将训练样本中的K线数据按照5日、10日和20日的划分单元进行划分,并根据划分后的K线数据绘制烛台图;其次,本文采用的CAE模块根据绘制的烛台图数据提取短期、中期和长期的深度K线特征;然后将提取到的深度K线特征分别与短期、中期和长期均线数据堆叠作为GRU模块的输入以学习当前交易日的深度K线特征和均线特征;最后本文将选取的基本面特征和当前交易日的深度K线特征和均线特征送入全连接层,得到预测的股价。由实验结果可知,本文所提出的方法相较于CAE网络、GRU网络和未经划分的CAE + GRU网络具有更高的拟合度和预测精度。但是总体的预测性能还需要进一步的提升,后期将在股市预测模型中仍需考虑网络舆情、经济水平和国家政治等因素来更好地反映股票价格的涨跌情况,进一步为投资者提供合理有效的参考。
基金项目
国家自然科学基金面上项目(62076137)。