1. 引言
随着中国工业化、城市化进程的快速发展,城市人口迅速膨胀,能源、交通规模持续扩大,产业结构不合理,能源消耗量大、利用率低等导致中国空气质量急剧下降。以可吸入颗粒物、二氧化硫、氮氧化物等为主要污染物的大气环境污染问题日趋严重,持续恶化的空气质量状况已经严重威胁到了公众的身体健康和国家经济的可持续发展。对空气质量进行全面、科学、准确的分析和预测,对于公众有效规避大气污染导致的健康损害,政府环保部门加强污染源监管和提高重污染日应急能力等方面都具有重要的理论意义和实用价值。
根据《环境空气质量标准》,用于衡量空气质量的常规大气污染物共有六种,分别为二氧化硫(SO2)、二氧化氮(NO2)、粒径小于10 μm的颗粒物(PM10)、粒径小于2.5 μm的颗粒物(PM2.5)、臭氧(O3)、一氧化碳(CO)。其中,臭氧污染在全国多地区频发,对臭氧污染的预警与防治是环保部门的工作重点。因此,利用现有的实测数据和一次预报数据建立二次模型以提高臭氧预报的准确度是重难点之一。
全国多地的污染问题日趋严重,关注空气质量的人群越来越多,空气质量预报也显得愈发重要 [1]。空气预报可采用的方法有多种,如文献 [2] 采用了逐步回归法进行了空气预报。文献 [3] 则利用CMAQ方法进行了空气质量的预测,而文献 [4] 使用了CMAQ-MOS空气质量预报模型。当实验数据有缺失时,文献 [5] 通过深度学习实现了空气质量的预测。由于污染物臭氧特殊性,文献 [6] 特别地采用了主成分分析法和逐步回归分析等方法确定了影响臭氧浓度的主要气象因素。文献 [7] 主要研究了CMAQ空气质量数值预报模式对区域性空气质量的预报准确度,通过对不同监测点的数据进行家聚类分析,以次进行预报的误差分析。文献 [8] 也提出了通过遗传算法以此提高空气质量预报的准确性。
但是目前国内常用的WRF-CMAQ [2] 模拟体系对空气质量预报的结果并不理想。本文首先介绍了空气质量指数(AQI)以及空气质量分指数(IAQI)的定义,数值以及计算方法,然后利用最优回归方程确定不同空气污染物的显著性大小,最后基于一次预报数据及实测数据进行空气质量预报二次数学建模,建立了学习型线性回归模型,在预报过程中使用实测数据对一次预报数据进行修正,优化了WRF-CMAQ预报模型,提高了空气预报的准确性。
2. 空气质量预报问题研究
2.1. 气象条件特征
空气质量指数AQI是目前开展空气质量监测各个国家用于通知群众污染程度的一个指标。本文中,根据空气质量指数对空气质量等级进行划分。如表1所示,AQI的值越大,则对应的等级越高,也就意味着空气污染越严重,对人类自身健康危害程度越高。

Table 1. Air quality grade and range of air quality index
表1. 空气质量等级及对空气质量指数(AQI)范围
下表2则表示空气质量分指数(IQAI)不同标准时,所对应不同污染物的浓度限值。
Table 2. Air quality sub index and corresponding pollutant concentration limit
表2. 空气质量分指数(IQAI)及对应的污染物项目浓度限值
首先搜集大量相关数据,将地点命名为监测点A,那么为了计算监测点A从2020年8月25日到8月28日每天实测的AQI和首要污染物,我们将使用大气污染P的空气质量分指数(IAQI)的计算方法。如式(1)所示。
其中,
为污染物P的测量浓度值,
为与
相近的污染物浓度限值的高位值;
为与
相近的污染物浓度限值的低位值;
为与
对应的IAQI;
为与
对应的IAQI。
根据所采集的污染物监测浓度数据,我们通过
计算公式可以计算出所有监测种类污染物的IAQI值,所有IAQI值中数值最大的那一个作为AQI值,也即
环境空气质量主要取决于环境中污染物的排放情况和环境中大气的扩散能力 [3] [4] [5]。其中,社会经济因素或直接或间接影响了所处环境中大气污染物的排放情况,气象因素主要决定了环境中大气的扩散能力。接下来在污染物排放情况不变的情况下分析各类气象条件对污染物浓度的影响程度。因此,在污染物排放相对稳定的情况下,气象条件对空气质量状况发挥主要作用。本文根据搜索的数据资料,从湿度、温度、气压、风速这四个气象条件着手,采用逐步回归算法 [6] [7] 分析各气象条件与空气质量(AQI)两者之间的相关关系。逐步回归算法是在全部需要考虑的因素中,按照它对因变量Y作用显著程度的大小,由大到小逐个引入回归方程。
则空气质量Y与预报因子X建立的最优回归方程为:
其中,Y为空气质量;
是常数项
为选入预报因子,
为选入的预报因子系数。
设当日24 h内的平均气压为x2 (MBAR),平均风速x2 (m/s),平均湿度为x3 (℃),平均温度x3 (%)随机选取40个样本今复兴逐步回归分析,回归结果如表3所示。
Table 3. AQI and meteorological correlation coefficient
表3. AQI与气象相关系数
从表3中可以看出,影响污染物浓度的有4个因子,即气压、风速、温度、湿度。sig均小于0.05,说明具有显著意义。同时根据表所示得到空气质量的逐步回归方程式为:
通过以上方法,已经基本确定了在污染物排放情况不变的条件下,某地区影响空气质量的主要气象因素为气压、风速、湿度、温度,并且皆与空气质量存在正效应作用。
1) 温度对空气质量的影响
某一地区空气温度越高,必将引起空气体积的膨胀,近地面的大气对流增强,空气中的分子必要向周围地区扩散,那么空气质量就越好。反之,气温越低,近地面的大气对流减弱,不利于空气中的分子向四周扩散,随之而来必将导致污染物浓度增加,空气质量变差。
2) 湿度对空气质量的影响
某一区域空气中湿度越大时,空气中的水汽更易于吸附污染物,从而沉降,那么该地区的空气质量就会变好。反之,湿度越小越不利于可吸入污染物颗粒的沉降以净化空气。
3) 风速对空气质量的影响
某一区域风速越大时,空气流动越强,越有利于空气中的分子向四周扩散,那么大气污染物得以稀释扩散,空气质量越好。反之,风速越小,大气流动活动减弱,污染物聚集,那么空气质量必然变差。
4) 气压对空气质量的影响
低气压中心地带常常是阴雨天,当空气温度大降雨量少或不能形成降雨时,空气中的颗粒物几乎不能被净化,甚至可能导致颗粒物的吸温增长,造成污染物堆积,空气质量变差。
2.2. 二次预报模型
目前国内对空气质量预报常用WRF-CMAQ模拟系统,但是WRF-CMAQ预报模型的预报结果并不理想。该系统往往受制于模拟气象场以及排放清单的不确定性,以及包括臭氧在内的污染物生成机理的不完全明晰。因此,需要利用已搜集的A,B,C三个监测点实测数据和一次预报数据进行二次建模。为了二次预报数学模型预测结果中AQI预报值的最大相对误差尽量小,首要污染物预测准确度尽量高,本文采用学习型线性回归方法进行修正预报。
二次建模的主要思路为:以起报日前一定历史时期的污染物浓度预报效果作为根据,通过训练样本总结出各污染物浓度预报值与实际监测值之间的函数关系。倘若该函数关系具有一定程度的延续性,那么在日预报时间仅需根据各污染物浓度预报值与相应的函数关系式相结合,我们就可以得出最终的预报效果。模拟中采用一元线性回归的方法,在MATLAB中通过输入历史时期各污染物浓度预报值与实际检测值,训练出函数模型。由于污染物浓度的预报性可能随着时间的推移发生变化,因此合理的选择回归样本数且对于修正预报的效果起到至关重要的作用。由于回归时始终选择正确距离预报时刻相近的一段日期内的污染物浓度数据作为样本,因此二次预报对邻近日期的各污染物浓度的预报的准确度较高。
一元线性回归的求解步骤:
第一步:给定一个训练数据集,其中测数据
,
是输入,表示实际监,
是输出,表示一次预报数据。
;
第二步:把训练数据带入构建的模型,即函数
;
第三步:求损失函数(用来衡量预测值和真实值差距的公式);
第四步:采用梯度下降法让损失函数最低;
第五步:对新的输入
,预测系统根据学习的模型输出
。
学习型线性回归模型建模思路如下图1所示。
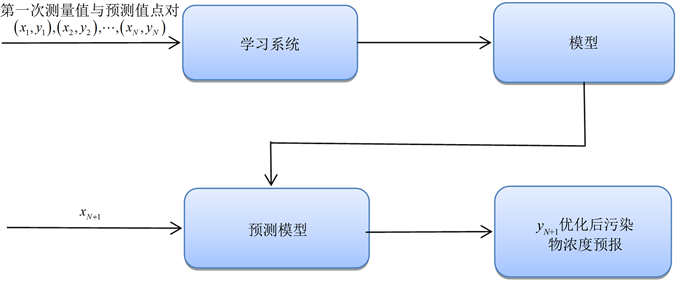
Figure 1. Thinking of learning linear regression model
图1. 学习型线性回归模型思路
基于学习型线性回归A监测点2021年7月13日二氧化硫污染物浓度预测模型如图2所示。
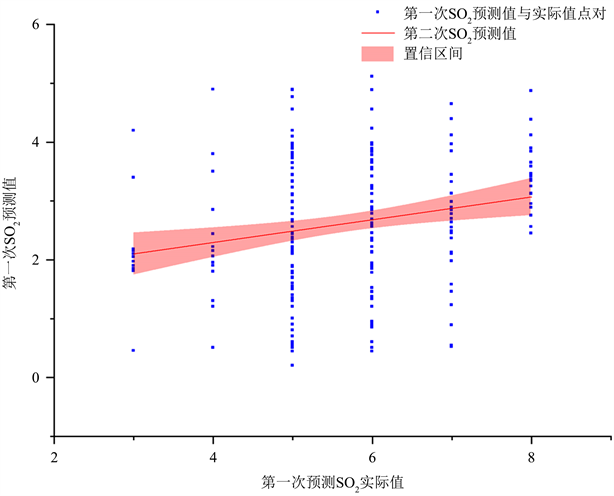
Figure 2. Prediction model of sulfur dioxide pollutant concentration
图2. 二氧化硫污染物浓度预测模型
基于学习型线性回归A监测点2021年7月13日二氧化氮污染物浓度预测模型如图3所示。

Figure 3. Prediction model of nitrogen dioxide concentration
图3. 二氧化氮浓度预测模型
则根据训练模型各污染物浓度及AQI的预测结果如下表4所示。
Table 4. Prediction results of pollutant concentration and AQI
表4. 各污染物浓度及AQI的预测结果
3. 模型评估
3.1. 模型的优缺点
3.1.1. 模型的优点
1) 采用逐步回归法可在所有需要考虑的因素中,按照自变量X (各气象条件)对因变量Y (AQI)影响的显著程度的大小,由大到小逐个引入回归方程。若某气象条件影响不显著,则将其从回归方程中删除,以保证在众多预报因子中选出最佳的预报因子组合,并且可根据选入的预报因子的相关系数判断各气象条件对空气质量的影响;
2) 建立的线性回归模型思想易理解,合理的选择回归样本可以训练出一个可靠的函数模型来描述数据之间的关系。那么新的输入出现时,可以得到一个修正后的污染物浓度预报值;
3) 模型比较简单,便于操作计算。
3.1.2. 模型的缺点
1) 本文所建立的模型对数据的依赖性很强,必须保证数据本身的准确性;
2) 本文在预测分析中仅考虑了气象条件的影响,忽略了社会经济因素的影响。以此影响了预测结果的全面性、准确性;
3) 没有讨论六种主要污染物在逐步回归模型中选入的最佳预报因子组合,也没有分析不同污染物的哪些气象条件对其浓度的影响起到了显著性作用;
4) 模型拓展性不高,容易受外界因素的影响。
3.2. 模型的推广与改进
在预测分析中加入社会经济因素,多影响因素模态下的空气质量预测可使预测结果更准确、更全面。
臭氧的预报可使用主成分析法与逐步回归法相结合,除了本文所使用的学习型线性回归模型还可使用CMAQ-MOS模型对CMAQ模式进行优化,从而提高预报的准确性。
基金项目
本篇文章受辽宁省教育厅面上项目的支持,项目编号为LJKMZ20220524。