1. 引言
政府采购及工程招投标领域数据的进一步开放,对数据的获取和综合利用能力将在未来成为衡量整个招投标大数据产业综合竞争力的新标杆。但面对海量的数据规模、复杂多样的数据结构、隐藏化的数据价值,如何在高效完成数据采集的同时,及时实现对信息的进一步抽取、识别、分析、建模及应用,挖掘出数据的隐藏商业价值,是标讯信息价值化路径的关键。
中文命名实体识别的实现算法是如今最为广泛使用的基于深度学习的方法。其中,前馈神经网络以单向方式进行信息传递,从而使得网络结构更加容易计算,但也削弱了神经网络的表达能力。循环神经网络通过对神经元接收自身的信息,而形成一个环路的网络结构,从而可以实现对文本序列中下文位置信息的记忆与处理。由于RNN中存在梯度爆炸或消失现象,从而导致神经元的短期记忆,存在长期依赖问题。LSTM神经网络中,记忆单元通过捕捉到关键信息并将其在一定的时间内存储保存,从而解决梯度爆炸或消失问题。由于信息的输出将受到历史信息和后续信息两个方面影响,因此引入双向长短期记忆神经网络(Bidirectional LSTM, BiLSTM)。
本文基于Bert + BiLSTM + CRF [1] 的中文实体识别深度学习算法,通过分类集中标注,学习标注数据集中的语义信息以及一些规律来识别蕴含标讯信息中的关键字段信息,提升多种字段识别准确率,解决特定环境结合上下文实体识别问题,为构建完整有效的集数据采集、数据清洗、数据聚合、数据建模、数据产品化为一体的公开大数据产品奠定基础。
2. 算法
命名实体识别任务作为信息抽取的一项基础性工作,主要是通过序列标注的方法进行解决。通过使用神经网络模型处理命名实体识别的问题已经成为一种趋势,Hammerton等人于2003年首次通过使用单向LSTM来处理命名实体识别问题,Collobert等人在2011年将CNN-CRF模型运用到NER任务中,Lample等人在2016年使用的LSTM-CRF模型在英文命名实体识别中取得突出的性能,成为了当前在命名实体识别问题中的主流模型之一 [2],CRF的优点是能对隐含状态建模,学习状态序列的特点,通过在标签之间增加约束性的条件 [3],可以更好的符合语言逻辑的正确性,最终生成符合人类的语言模型。单词向量序列用作模型的输入表示,输入到双向LSTM,通过训练提取特征信息,输出到CRF层,最后计算最佳注释序列。
2.1. BiLSTM
长短期记忆(LSTM)主要用于解决长序列训练中梯度消失和梯度爆炸的问题 [4]。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。其主要结构如图1所示。
BiLSTM模型添加了LSTM网络的后向层,前向和后向隐藏层一起形成BiLSTM网络模型的隐藏层,并最终加入输入层进行连接。对于输入层中句子的标签信息,前向LSTM用于从前往后表示句子的信息,后向LSTM则用于从后往前表示语句的信息。最后,上下文信息的连接是单词的最终表示。在输入层,句子中每个单词对应的单词向量可以输入到BiLSTM层,正向LSTM获得单词向量的正向隐藏层序列。
2.2. CRF
条件随机场(Conditional Random Field,简称CRF)是一种判别式无向图模型 [5],生成式模型是直接对联合分布进行建模,而判别式模型则是对条件分布进行建模,条件随机场则是判别式模型。跟隐马尔可夫模型通过联合分布进行建模不同,条件随机场试图对多个变量在给定观测值后的条件概率进行建模。通过上下文的分析,条件随机场分词会提升到更高的精度。但因为复杂度比较高,条件随机场一般训练代价都比较大。
2.3. Bert
BERT 的创新点在于它将双向Transformer用于语言模型,双向训练的语言模型对语境的理解会比单向的语言模型更深刻,Transformer的原型包括两个独立的机制,一个encoder负责接收文本作为输入,一个decoder负责预测任务的结果 [6]。BERT的目标是生成语言模型,所以只需要encoder机制。Transformer的encoder是一次性读取整个文本序列,而不是从左到右或从右到左地按顺序读取。
3. 实现流程
具有复杂结构的标讯的字段化、结构化是抽取、数据标注、模型迭代更新相互结合的一个流程,如图2所示。
3.1. 数据清洗
数据分析、定义数据清洗的策略和规则、搜寻并确定错误实例、纠正发现的错误以及干净数据回流。
3.2. 数据标注
采用联合标注:对一串连续的字标注相同的标签。在NER任务中,实体由一个或多个字组成,所以它属于联合标注任务。但是在联合标注中,相邻词语标签之间可能会存在依赖关系。这一问题可以通过标签转化的方式,把联合标注转化成原始标注解决。
3.2.1. 数据集1
数量:数据量8388篇文本,16字段。
标注方式和类型:对全文进行标注,
标注字段:

Figure 2. Information model identification process
图2. 信息模型识别流程
项目名称、项目编号、项目预算、项目预算单位、报名截止时间、投标截止时间、业主、业主联系人、业主电话、代理机构、代理联系人、代理电话、中标机构、中标金额、中标金额单位、中标候选人
说明:该版本没有对数据进行分类标注抽取,全部类型数据为同一类进行16个字段的抽取。
3.2.2. 数据集2
数量:33,000左右,9类,全部34字段。
标注方式和类型:对全文进行标注。
标注字段:在后续的第二版本招标过程字段抽取中新增了其他字段,在招投标过程中,我们将招标过程中的文档分为预告、招标公告、采购公告、开标公告、评标公告、中标公告、采购结果、合同、其他9类。
3.3. 模型训练
对标注好的数据集使用BERT + BiLSTM + CRF模型进行训练。
1) 该模型训练过程中的loss (训练损失)随着模型迭代次数的变化图如图3所示,该图反应了模型训练过程中损失下降的过程,对于一个模型损失越小越好。
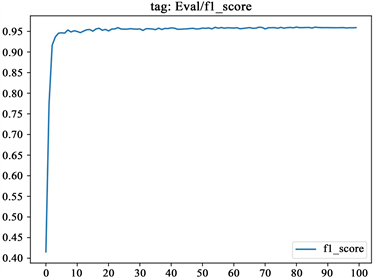
2) 该模型训练过程中的验证集的F1值、precision (精确度)、recall (召回率)随着模型迭代次数的变化图如下所示,该图反应了模型在不断迭代学习过程中对验证数据集的一个测试,其中F1、precision (精确度)、recall (召回率)值是衡量该模型好坏的标准,这三个值越大越好,其中F1值是通过precision (精确度)、recall (召回率)计算得到的,F1常用来表示一个模型整体好坏。图4展示了模型的准确率、召回率及F值的得分数随着迭代次数的变化情况。从图中看到,在开始迭代20次后,模型的性能结果逐步收敛,经过 20次左右的迭代次数之后,模型评价指标分数值基本保持在一个较为稳定的数值,并处于一个很小范围浮动的状态。出于时间成本及性能结果的考虑,本文最终选取迭代次数为60的训练参数。

Figure 3. Loss (training loss) change chart
图3. Loss (训练损失)变化图
 (a)
(a)  (b)
(b) 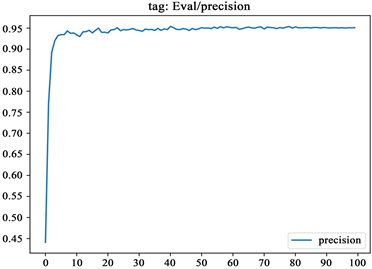 (c)
(c)
Figure 4. F1 value, precision and recall change chart
图4. F1值、精确度、召回率变化图
3) 训练步骤:
BidBert + BiLSTM + CRF模型(这里的BidBert是在我们自己的招标数据集上使用BERT模型训练得到的),其训练流程包括以下步骤:
S1、对纯文本、HTML和DOC文档等进行数据预处理;
S2、将S1的结果输入BidBert模型得到每个句子中字或词的Word Embedding;
S3、将S2的输出输入双向BiLSTM得到特征向量,再经过CRF对特征向量进行解码;
S4、通过S2、S3进行迭代训练,得到BidBert + BiLSTM + CRF模型。
3.4. 模型训练代码结构
bert_bilstm_crf_ner_pytorch
│.gitignore
│3.19.0
│requirements.txt# 环境包信息
│README.md
└─torch_ner
│__init__.py
├─bert-base-chinese#base Bert模型
│ config.json
│ flax_model.msgpack
│ pytorch_model.bin
│ tf_model.h5
│ tokenizer.json
│ tokenizer_config.json
│ vocab.txt
├─data # 训练、验证、测试数据集
│ eval.txt
│ test.txt
│ train.txt
│
├─output # 模型保存路径
│├─20220901174450
│││config.json
│││config.train
│││label2id.pkl
│││label_list.pkl
│││ner_model.ckpt
│││ner_model.pth
│││pytorch_model.bin
│││special_tokens_map.json
│││tokenizer_config.json
│││token_labels_test.txt
│││training_config.bin
│││vocab.txt
││└─eval
││ events.out.tfevents.1662025491.DESKTOP-STKHN7G
│└─logs
│ ner_train.log# 训练日志
├─source
││config.py# 配置文件,模型训练参数等在里面配置
││conlleval.py# 验证模型和测试模型类
││logger.py# 日志
││models.py# 主要模型,构建好的模型
││ner_main.py# 训练模型的入口
││ner_main_bak.py
││ner_predict.py# 模型推理预测
││ner_processor.py # 训练数据预处理
││ner_test.py
││pth2pt.py
││test.py
││utils.py
││__init__.py
3.5. 模型应用
模型推理就是抽取标讯信息中的关键信息,是对纯文本、HTML和DOC文档等中的关键信息进行抽取,其步骤包括:
S1、对纯文本、HTML和DOC文档等进行数据预处理;
S2、将S1的结果输入到BidBert + BiLSTM + CRF模型中进行抽取,并得到结果。
通过对1000篇标讯信息的两种不同模型抽取核查,实验结果如表1所示,可以看出,BiLSTM-CRF模型的各类命名实体识别准确率要大于LSTM-CRF模型,与单向的LSTM-CR模型相比,BiLSTM + CRF模型准确率、召回率、F值平均提高1.13%、1.09%、1.22%。实验结果数据可以表明,将单向 LSTM 网络结构改进为双向LSTM网络结构,有助于对文本序列的上下文信息提取。

Table 1. Comparison of experimental results of different models of bids data
表1. 标讯字段抽取不同模型实验结果对比
4. 结束语
BiLSTM + CRF模型泛化能力强,缺点是需要大量的标注样本,采用迁移学习的思想,利用Bert在先验知识的基础上进行模型训练,BERT Embedding与BiLSTM CRF分离 [7],可实现GPU显存的高效利用。
全国每天发布的招投标信息超过二十万条,绝大部分都是各种格式的复杂非结构化信息,如何识别及结构化,对于挖掘数据的隐藏价值具有非常重要的作用,本文尝试通过大量的文本标注,借助机器学习算法,不断优化模型,取得了较好的提取效果,对实现营销决策、数据统计及分析等各类大数据应用奠定了良好基础。
基金项目
贵州省科技计划项目(课题)黔科中引地[2021] 4016;基于BOES开放引擎的数据分析关键技术在招投标领域的创新应用。
参考文献