1. 研究背景及意义
人口是保障社会和经济持续发展的重要载体,是整个社会的最基础的部分。庞大的人口总量不仅能为经济持续高质量发展提供充足的劳动力,同时也能在科技创新、艺术创作和体育竞技等众多人文领域发挥充足的人才优势。与之相对的,不合理的人口增长速度和人口结构也会导致社会和经济发展受到阻碍,进而影响人们的生活水平和质量以及社会的长期稳定发展。
中国人口数位居世界第一,我国人口总数的变化不仅是我国经济以及社会发展有着不可忽视的影响,同时也对于其他国家也有着不凡的意义,因此也得到了国际社会的长期关注。随着我国生育率持续降低,人口增长趋势渐缓,人口老龄化问题加剧,为了能够更好地应对未来发展中更多的问题和挑战,能够实现我国人口的均衡发展,保证我国社会和经济持续高质量发展,2015年我国决定全面实施二胎政策。这是我国历史上人口政策方面的又一次重大的转变,这也是影响我国未来几十年的人口结构变动的另一个重要影响因素。
1.1. 研究目的
人口预测数据是国家制定人口、经济和社会发展等宏观发展战略规划中的最基础数据。随着近年来人口生育政策适度调整以及中国人口结构变动等因素的影响,中国的人口发展增速和结构各方面都变得越来越复杂,同时,人口与资源环境的关系、人口老龄化程度不断加深等问题都在不断加深,也变得更加严重,关于如何对未来人口变动趋势做出准确判断的问题不仅是人口学领域的研究重点,同时也是经济学研究的领域,人口基础数量和人口结构对我国经济发展有着重要的影响。当前,学术界已经进行了大量而深刻的关于人口各方面问题的详细研究,并且大家也普遍达成了一个共识,即专家学者们一致认为人口问题是一个发展问题。
1.2. 研究方法
首先,通过大量的文献查阅去获取与我国人口预测方向相关的研究现状,再通过统计年鉴统计我国近四十年来的人口总数,建立ARIMA模型进行短期预测,最后根据人口预测趋势和结果,分析其原因并提出相关建议。
2. 文献综述
随着经济高速发展,我国人口数量不断增加,近年来,越来越多的学者致力于研究我国人口发展趋势和未来人口增长趋势的,主要研究内容进行分类整理如下所示。
2.1. 人口发展趋势
人口数据是社会生活和经济发展中各个方面的预测和分析中最基础的数据。陈卫文(2006)基于2000年全国第五次人口普查数据以及2004年国家统计局统计公布的全国总人口数,对我国2005~2050年全国人口发展趋势进行预测分析,同时发现我国生育率在快速下降,我国将长期处于低生育水平 [1]。而与生育率水平相关的,即是受教育人口、劳动力水平和人口老龄化。徐警武(2007)发现我国的人口再生产面临重大转型,认为我国2007~2027这20年间,我国高等教育将由大众化进入普及化,高等教育规模将进一步扩大,这会导致大量学生入学,造成较大的入学压力 [2]。张瑾和黄志龙(2014)研究发现我国未来劳动适龄人口比例与16~64岁劳动参与人口比例将持续下降 [3]。2015年实行二胎政策后,王亚楠和钟甫宁(2017)利用1980~2010年进入生育期的妇女的初育年龄对其终身生育率进行预测,研究发现,为促进未来人口出生数量能够稳步增长,以此保持人口长期处于均衡发展状态,我国生育政策的目标仍须做出适当的提高 [4]。周文(2018)通过假设全面二孩政策实施后我国总和生育率分别以2.0、1.8、1.5和 1.18的水平发展研究发现,只有当生育率随着全面二孩政策的实施提高至更替水平2左右时,我国人口结构才能得到改善,否则,我国人口规模将快速微缩,人口年龄结构进一步老化 [5]。但二胎政策放开后,我国生育率水平并没有达到2,赵玉峰和杨宜勇(2019)综合比对多种人口预测数据发现,出生人口规模将波动下降,而我国人口总量下降拐点将在未来10年内出现 [6]。陈友华(2019)研究发现,我国正处在超低生育率早已形成、人口增长接近尾声、老龄化程度将不断加深 [7]。王金营和李天然(2020)以2002~2014年我国老年人健康长寿影响因素跟踪调查(CLHLS)数据为基础,研究发现,未来失能老年人口规模将不断扩大,预测2050年失能人口约占老年人口总数的13.68% [8]。
2.2. 人口预测方法
近年来,学者们运用多种方法对我国人口进行过预测。
孟令国、李超令和胡广(2014)采用人口–发展–环境模型(PDE),预测了我国2015~2050年人口结构变化走势,认为实施二胎生育政策比较理想 [9]。陈霞和肖岚(2020)在Logistic种群增长模型中引入适当形式的收获模型 [10]。赵子铭(2019)利用时间序列方法及不同检验、最优化方法建立ARIMA模型,预测结果与实际结果相差不大 [11]。郭雪峰、黄健元和王欢(2018)基于自适应滤波法对传统灰色模型进行残差修正后,比较了传统灰色模型和改进后模型的预测结果,发现,改进后的模型预测精度更高,适用性与可行性更强 [12]。为了使预测结果更加准备,也有学者将两种模型相结合。徐翔燕和侯瑞环(2020)将灰色预测模型和支持向量机模型进行组合,选取一师阿拉尔市19997~2017年的人口数据进行分析,对2018~2022年人口进行相关预测,发现与单一模型相比,组合模型预测精度会更高,其相对误差也会更低,若以与单一模型相比,组合模型会更合适 [13]。唐贤芳、崔岩和张淑丽(2020),选择2003~2015年数据建立静态灰色模型,而后构建等维递补动态模型与静态灰色模型,研究发现动态预测模型在预测精度方面明显好于静态预测模型,其数据预测的可靠性也会更强 [14]。对于模型的运用,盛亦男和顾大男(2020)对未来人口预测的方法做出了详细总结,发现目前的预测方法都存在一些缺陷,而基础数据的准确性反而更关键 [15]。
2.3. 文献评述
我国学者对于我国人口未来发展趋势持较统一观点,普遍认为我国生育率将快速下降,即使在2015年施行二胎政策后,我国人口老龄化的趋势也因此得到减缓,人口老龄化加重仍是当今社会我们需要面对的重要问题,与此同时,我国未来人口总量增长趋势也会随之减缓,这也是我国当前不可避免的问题。在人口预测的模型方面,学者们大多运用灰色预测模型和ARIMA模型,因此本文通过查阅统计年鉴相关数据,选取了我国1980年至2019年的每年人口总数数据,利用R语言建立了拟合优度高的ARIMA模型,预测了未来十年我国人口总量以及其增长趋势。
3. ARIMA (p, d, q)模型理论分析
3.1. ARIMA模型原理
ARIMA模型全称为求和自回归移动平均模型,简记为ARIMA (p, d, q)模型,是一种时间序列预测方法,其中AR (p)为自回归部分,MA (q)为移动平均部分。该模型旨在通过差分运算将非平稳时间序列转化为差分平稳序列,然后利用因变量的滞后值和随机误差项建立模型,以达到对未来值预测的目的,具体的数学表达式如下:
3.2. 平稳性检验
图示法是粗略判别AR (p)模型平稳性的一种方法,特征根判别是精确判别平稳性的方法。AR(p)模型可以简写为:
假设
是平稳序列
线性差分方程的p个特征根,任取
,带入特征方程,有
。假如该方程的所有特征根都在单位圆内即
,则该序列为平稳序列。
3.3. 纯随机性检验
Ljung和Box证明LB统计量近似服从自由度为m的卡方分布,数学表达式为:
其中,n为观测期数,m为延迟期数。若LB统计量小于临界水平,则拒绝原假设,认为序列为非白噪声序列,可以继续拟合模型。
3.4. 模型选择
在建立模型时,通常会有几个模型通过上述检验,此时就需采用下表1所示原则来选择相关模型,并采用信息量准备来确定模型的最优阶数。

Table 1. Basic principles of model order determination
表1. 模型定阶的基本原则
3.5. 最小二乘估计
在ARMA (p, q)模型场合,记
残差项为:
残差平方和为:
,使残差平方和达到最小的参数值为
的最小二乘估计值。
3.6. 模型预测
用
衡量预测误差,
,显然预测误差越小预测精度越高。现最常用的预测原则就是预测方差最小原则,即
。
4. ARIMA模型建模分析——以我国近四十年人口总数为例
4.1. 平稳性检验

Figure 1. Time series chart of China’s total population from 1980 to 2019
图1. 1980~2019年中国人口总数时序图
选取统计局官网公布的统计年鉴中1980年至2019年的总人口数作为观测样本,近四十年来我国人口波动时序图如图1所示,人口数量呈稳定增长趋势,对序列进行一阶差分后发现,ADF检验并未通过,再进行二阶差分,二阶差分后时序图如下图2所示。观察二阶差分后时序图,认为时序图具有一定的平稳性。

Figure 2. Second order difference sequence diagram of China’s total population from 1980 to 2019
图2. 1980~2019年中国人口总数二阶差分后序列时序图
由表2可知,虽然有趋势有截距项有趋势两种类型下的滞后4阶的P值均大于5%临界水平,但无趋势无截距和无趋势有截距项类型下的滞后1~4阶P值均小于5%临界水平,因此我国近四十年人口总数二阶差分后序列是平稳的。
Table 2. Unit root test of China’s total population from 1980 to 2019
表2. 1980~2019年中国人口总数单位根检验
4.2. 纯随机性检验
如下表3所示,原序列在各阶数下LB统计量的P值均小于5%临界水平,因此该序列拒绝原假设,即,我国1980~2019年人口总数二阶差分序列为非白噪声序列,可直接拟合模型。
4.3. 模型识别与定阶
1) 模型识别
我国1980~2019年人口总数二阶差分后序列自相关和偏自相关图如下所示。

Figure 3. Autocorrelation graph of primitive sequence
图3. 原序列的自相关图
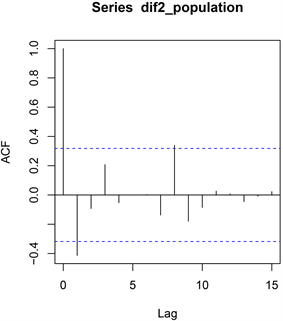
Figure 4. Partial autocorrelation graph of primitive sequence
图4. 原序列的偏自相关图
由图3和图4可知,自相关图无法具体确定是几阶截尾或拖尾,因此可以初步拟合ARIMA (0, 2, 1)、ARIMA (0, 2, 2)、ARIMA (1, 2, 1)和ARIMA (1, 2, 2)模型,观察其AIC值,再确定最终拟合模型,R在序列自动定阶中给出的合理模型为ARIMA (0, 2, 1),因此也加入模型的AIC比较中。
2) 模型定阶
Table 4. ARIMA model fitting effect
表4. ARIMA模型拟合效果
如上表4所示,ARIMA (0, 2, 1)的AIC值最小,同时其模型检验见图5,根据左下图显示各阶延迟下白噪声检验统计量的P值都显著大于5%临界水平,表示拟合模型ARIMA (0, 2, 1)的残差序列为白噪声序列,即该拟合模型均显著。
4.4. 模型预测
根据图6的时序图可以看出未来十年的人口总数增长趋势与历史波动趋势大致吻合,具体的人口总数预测值见表5。
5. 结论与建议
5.1. 结论
本文针对我国总人口的预测问题建立了相关ARIMA模型,人口总数二阶序列呈现趋势平稳,也通过了纯随机性检验,根据偏自相关和自相关图相结合建立的模型ARIMA (0, 2, 1)的AIC值最小,同时,

Figure 5. Significance test of ARIMA (0, 2, 1) model
图5. ARIMA (0, 2, 1)模型的显著性检验

Figure 6. Forecast of China’s total population in the future from 2020 to 2029
图6. 2020年~2029年我国未来人口总数预测图
Table 5. Forecast of China’s total population in the future from 2020 to 2029
表5. 我国2020年~2029年未来人口总数预测
ARIMA (0, 2, 1)模型显著,于是选择ARIMA (0, 2, 1)模型对我国未来人口做出预测,其预测结果与历史波动趋势相吻合,而在实施二胎政策后,我国人口增长趋势并没有发生显著性变化,这说明我国人口并没有因为二胎政策而有显著变化。
5.2. 建议
根据我国人口总数预测,提出以下几点建议:
1) 生育政策的调整目标须适当提高。二胎政策实行以来,我国人口数并没有得到显著的增加,说明生育目标仍须适当提高,以此来增加我国新生人口数。
2) 重点解决我国年轻一代就业和住房压力。生育压力主要来自于就业和住房压力,在就业压力和住房压力得到适当缓解后,我国生育水平得到提升,人口增长率也会随着提升,同时,我国经济发展也将得到提升。