1. 引言
国内生产总值(GDP)是一个国家或地区所有常住单位在一定时期内生产活动的最终结果。它反映一国家或地区的经济生产规模与综合实力,是国民经济核算的核心指标,也是衡量一个国家或地区经济状况和发展水平的重要指标。历年来,山东都是我国的经济大省,在国内占据重要地位。因为近几年受疫情等多因素影响,所以山东省经济发展受到冲击,因此面对错综复杂的国内国外经济贸易形势,山东省多年来的增长优势能否继续保持是当地人民最主要关心的事件之一,下面就针对这一主要问题进行研究分析。
本文首先选用ARIMA模型对山东省1978年~2018年的GDP数据作时间序列,根据数据的变化规律,建立时间序列模型,预测2019年至2020年的GDP数据,与BP神经网络得出的山东省GDP作对比,检验结果表明ARIMA模型具有较好的预测效果,为山东省制定经济发展目标提供决策参考。
2. ARIMA模型构建
2.1. ARIMA模型的结构
ARIMA模型又称为求和自回归移动平均模型,由Box-Jenkins首次提出。ARIMA模型简记为ARIMA (p, d, q)模型 [1]:
式中,
为延迟算子,
,
,为平稳可逆
模型的自回归系数多项式;
,为平稳可逆
模型的移动平滑系数多项式。
2.2. 建模步骤
1) 判断序列是否为平稳时间序列,如果序列是非平稳,可以通过差分等方法,将它化为平稳时间序列。
2) 确定
模型,选取适当的
值。
3) 模型预测和优化 [2]。
3. BP神经网络
3.1. BP神经网络理论
人工神经网络是一种运算模型,由大量的节点(神经元)和节点之间相互连接构成,每个节点代表一种特定的输出函数,称为激励函数。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称为权重。它具有通过学习逼近任意非线性映射的能力,将神经网络应用在非线性系统的建模与辨别中,可以不受非线性模型的限制。当前应用最广的是多层前向神经网络(BP神经网络),由三部分组成:输入层、隐含层和输出层。
式中,
表示输入信号,
表示输出信号,
表示神经元
的突触权值,
表示输入信号线性组合器的输出,
表示激活函数,其中
。
3.2. BP神经网络的步骤
1) 对样本数据进行预处理。BP神经网络首先对原始数据进行归一化,把数据转化为区间[−1, 1]的数字,这样可以尽可能地平滑数据,消除预测结果的噪声,初始化公式为:
其中,
表示样本序列输入值,
表示输入序列的最小值,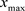 表示输入序列的最大值,
表示输入序列的最大值,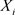 表示归一化后的数据。
表示归一化后的数据。
2) 划分训练集和测试集。依次将连续8年的数据作为网络的一个输入数据,第9年的数据作为网络输出,按此方式进行滚动式的排列,形成神经网络的训练样本。
3) 构建BP神经网络。
4) 网络参数配置。
5) BP神经网络训练 [3]。
4. 实证分析
4.1. 数据的来源
本文选取的数据是1978~2021年期间山东省的GDP数据。将1978~2018年的数据作为训练集,2019~2021作为测试集,并预测2022年的GDP。所有数据均来源于《山东统计年鉴》。
4.2. 基于ARIMA模型的GDP预测
4.2.1. 数据的预处理
将1978年至2018年的GDP数据绘制时间时序图,如图1所示,GDP数据呈现出明显的递增趋势,认定数据是不平稳的;同时对数据做单位根(即ADF)检验,验证得出数据为非平稳序列。为了使其平稳化,选择用差分方法对其进行平稳化处理,我们对原序列进行差分运算,再者对差分后序列进行ADF检验,该序列所有ADF检验统计量的P值均小于显著性水平(α = 0.05),所以确定三阶差分后序列平稳(图2)。再对三阶差分后序列进行纯随机性检验。检验结果显示,各阶延迟下LB统计量的P值均小于显著性水平,说明差分后序列不是白噪声序列。
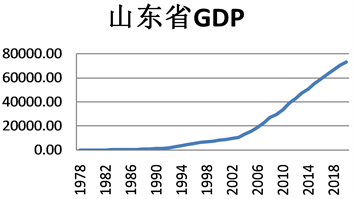
Figure 1. Time series of Shandong GDP
图1. 山东省GDP时序图
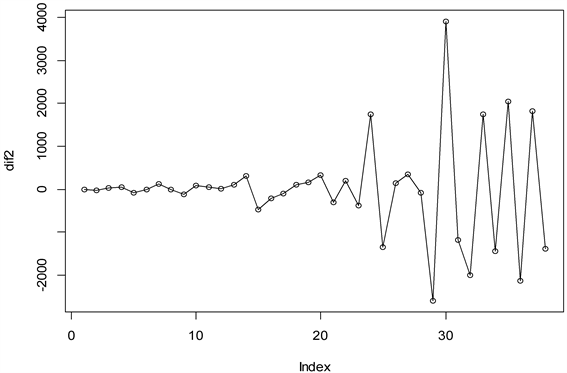
Figure 2. Third order difference time series of Shandong GDP
图2. 山东省GDP三阶差分时序图
4.2.2. ARIMA (p, d, q)模型的识别
ARIMA (p, d, q)模型中未知参数的确定主要依靠分析自相关图和偏自相关图,从图3可以观察到序列的自相关图在第一阶差分之后急速衰减,自相关图呈现一阶截尾状态,确定q = 1。从图4观察偏自相关图在三阶差分之后衰减,为确保p、q值的选择更加合适,根据AIC最小准则,比较不同参数(q)时的AIC值,最后选择ARIMA模型为ARIMA (1, 3, 2),此模型下的AIC = 607.34。
4.2.3. ARIMA (1, 3, 2)模型预测
利用最优模型,对山东省GDP进行预测并且与实际值比较如表1。
4.3. BP神经网络山东省GDP模型预测
本小节以2001至2018年的数据为初始数据,作为训练集,用于建立模型,2019至2021年数据为模型测试集,并预测2022年的GDP数值,得到预测结果如表2。
隐含层神经元的个数通过经验公式确定: ,
, 为输入层层数,
为输入层层数, 为输出层层数,
为输出层层数, ,隐含层神经元的传输函数选择
,隐含层神经元的传输函数选择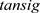 ,输出层的传输函数为
,输出层的传输函数为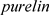 ,反向传播的训练函数为
,反向传播的训练函数为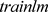 [4]。
[4]。
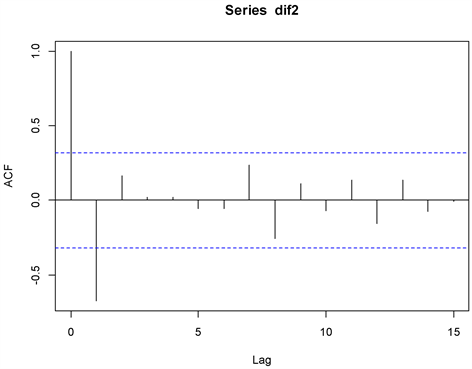
Figure 3. ACF of the third differenced series of GDP
图3. 三阶差分后GDP的ACF图
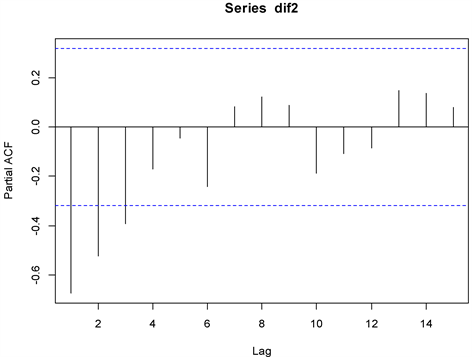
Figure 4. PACF of the third differenced series of GDP
图4. 三阶差分后GDP的PACF图

Table 1. Comparison of the forecasts and actual observations in ARIMA (1, 3, 2)
表1. ARIMA (1, 3, 2)预测值与实际值的比较
Table 2. Comparison of the forecasts and actual observations in BP neural network
表2. BP神经网络预测值与实际值对比
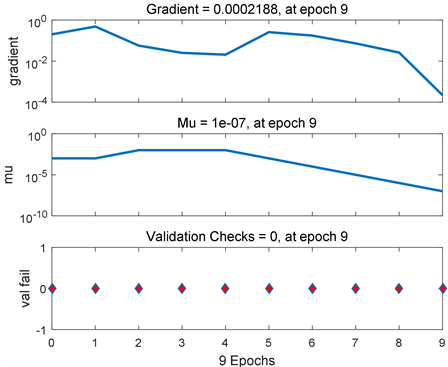
Figure 6. BP neural network training data process chart
图6. BP神经网络训练数据进程图
对于给定的数据集,在对BP神经网络进行预测性能测试后,最终可以得到神经网络的输出值,在训练次数达到9次时,BP神经网络的均方误差为2.6545−09,预测得到2022年的GDP值,得到较好的训练效果,预测精度较高。BP神经网络的学习效果图如图5,训练数据图如图6。
5. 总结
时间序列模型主要是先利用已知数据进行建模,之后对未来数据进行预测的一种方法,BP神经网络主要通过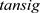 可微函数来表达信息输入、输出非线性映射。本文仅使用山东省GDP数据这单一指标进行预测,未考虑其他经济因素。文章利用时间序列ARIMA模型和BP神经网络模型,对山东省GDP数值分别进行预测分析,通过预测结果分析,发现在本文中时间序列ARIMA模型预测2019年到2021年的GDP数据更接近真实值,相对比BP神经网络的预测结果误差小,但从预测2022年GDP数据来看,BP神经网络的预测值比时间序列ARIMA模型的预测值可靠。
可微函数来表达信息输入、输出非线性映射。本文仅使用山东省GDP数据这单一指标进行预测,未考虑其他经济因素。文章利用时间序列ARIMA模型和BP神经网络模型,对山东省GDP数值分别进行预测分析,通过预测结果分析,发现在本文中时间序列ARIMA模型预测2019年到2021年的GDP数据更接近真实值,相对比BP神经网络的预测结果误差小,但从预测2022年GDP数据来看,BP神经网络的预测值比时间序列ARIMA模型的预测值可靠。