1. 引言
近年来,随着中国经济持续快速发展,以新能源汽车为主体的智能网联汽车行业呈现快速增长态势。一个完备且安全的智能网联的汽车控制系统是智能车辆研究和发展的一个重要方向,它能够辅助驾驶甚至实现无人驾驶,有效地保障驾驶安全,提升驾驶体验,减少交通事故,提高交通效率。而交通标志识别系统(Traffic Sign Recognition System, TSRS)作为车辆控制系统领域中的一个重要组成部分,近年来受到学界和工业界的广泛关注。
传统的交通标志的检测主要依靠手工设计的传统特征,如交通标志的形状和颜色等,根据分类目标提取图像合适的特征,然后用提取的特征训练机器学习分类器,分类器离线训练好之后,便可以用来对待识别图像进行分类 [1]。手工设计的特征往往无法适应复杂的驾驶环境,多阶段的特征提取和分类导致计算量巨大,在识别的精度和速度上都无法满足实际的需求。得益于计算机硬件的提升和深度学习的发展,大量的优秀的目标检测算法不断被提出并成功的运用于交通标志的检测和识别 [2] [3] [4]。
基于深度学习的目标检测算法主要分为两阶段(two stage)算法(如,RCNN [5]、fast RCNN [6]、faster-RCNN [7])和一阶算法(one-stage) (如,SSD [8]、YOLO [9] [10] [11] [12])两类。在交通标志的识别中,李旭东 [13] 等将YOLOv3-tiny检测算法作为基础网络,提出了一种三尺度嵌套残差结构的交通标志快速检测算法,并在长沙理工大学中国交通标志检测数据集上进行试验,指示、禁令、警告三大类交通标志F1分数分别为92.41%、93.91%、92.03%,检测时间为5.0ms。鲍敬源 [14] 等提出了一种Strong Tiny-YOLOv3目标检测模型,该模型通过引入Fire Modul层进行通道变换,在减小模型参数的同时能够加深模型深度。同时,模型在Fire Module层之间加入shortcut来增强网络的特征提取能力,在中国交通标志检测数据集上精度均值达到了85.56%。刘万军 [15] 等提出了一种新型多尺度融合卷积神经网络(SF-RCN),在基础特征提取网络中加入多尺度空洞卷积池化金字塔模块(MASPP),在网络中增加两个快速拼接模块(F-concat),融合模型中高层与低层的信息,该模型在中国交通标志检测数据集上精度均值达到了87.48%。
本文基于YOLOv5模型,针对交通标志在图像中密集且占比小的特点,通过增加注意力机制,引入多尺度融合,通过改变边框回归损失函数等方法,提升交通标志的检测的精度,加快模型训练的收敛。改进的YOLOv5s模型在长沙理工大学中国交通标志检测数据集(CCTSDB) [16] 上进行训练和验证。实验结果表明,改进后的YOLOv5s模型比原始YOLOv5网络的mAP指标提升了10.03个百分点,准确度提升了4.7个百分点,召回率提升了2.6个百分点,并且在小目标的检测中表现良好。
本文整体安排如下:第2部分从Input、Backbone、Neck、Head四个方面对原始YOLOv5模型算法进行简单介绍,再对优化锚框结构、引入的GAM注意力机制、特征融合结构Bi-FPN、加快模型收敛的SIoU分别进行详细的阐述。第3部分针对中国交通标志检测数据集(CCTSDB)的基本情况、实验环境的基本设定进行了简单交代,最后对实验结果和实验效果进行了简单分析。
2. YOLOv5模型架构
2.1. 原始YOLOV5模型
2016年,Joseph Redmon等人提出了一种单阶段(one-stag)的目标检测网络YOLO,并经过不断技术迭代至YOLOv5,逐渐成为one-stage目标检测算法的基准算法。YOLO的核心思想是将目标检测视为一个空间上分离的预测框和有联系的类概率的回归问题。YOLOv5模型结构可以分为Input、Backbone、Neck、Head四个主要部分,并根据模型的深度和宽度不同,衍生出YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四个模型,根据不同设备,适配于不同的数据集,从而达到精度和速度的平衡。
Input输入端主要包括Mosaic数据增强、自适应anchor计算,自适应图片缩放三个方法。Mosaic数据增强通过随机缩放、随机裁剪、随机排布的方式对4张不同图像进行拼接,不仅能丰富检测目标的背景,提高小目标的检测效果,且能减少显存的使用,加强BN效果。自适应anchor计算是指利用K-Means聚类和遗传算法,自适应的计算不同训练集中的最佳锚框值,根据最佳锚框生成的预测框能更好的匹配Ground Truth,进而加快模型收敛和提高定位精度。自适应图片缩放是对不同长宽比的图片自适应地添加最少的黑边,减少冗余信息提高推理速度。
Backbone主要包括C3 [17] 和SPPF [18] 模块。C3模块基于BottleneckCSP模块,将梯度的变化从头到尾地集成到特征图中,支持特征传播,鼓励网络重用特征,增强网络提取特征的能力的同时减少网络参数数量。SPPF通过不同池化核的最大池化进行特征提取,提高网络的感受野。
Neck主要包括特征金字塔网络(feature pyramid networks, FPN [19])和与路径聚合网络(path aggregation network, PAN [20])相结合的结构。FPN是自顶向下的,将高层的特征信息通过上采样的方式进行传递融合。PAN是自底向上的,将低层的位置信息传递融合。FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,实现高层特征与低层特征融合互补,使模型获得丰富的定位和分类特征信息。
Head设置了三个检测头,在三个检测层中图像分别下采样32倍、16倍和8倍。不同尺寸的特征图用于检测不同尺寸的目标对象,利用计算出来的先验框进行回归预测,有利于大中小不同尺寸的目标,尤其是小目标的检测。如图1所示为YOLOv5s的网络架构。
2.2. 改进YOLOv5
2.2.1. 先验锚框优化
大量实验证明,合适的先验锚框能够很大程度的增加网络训练的稳定性和收敛速度,提高网络检测准确率。由于不同的数据集的检测目标大小各不相同,YOLOv5基于COCO数据生成的锚框不再适合交通标志的数据集。本文利用K-Means聚类和遗传算法,计算出适合不同特征层的先验锚框,如表1所示。
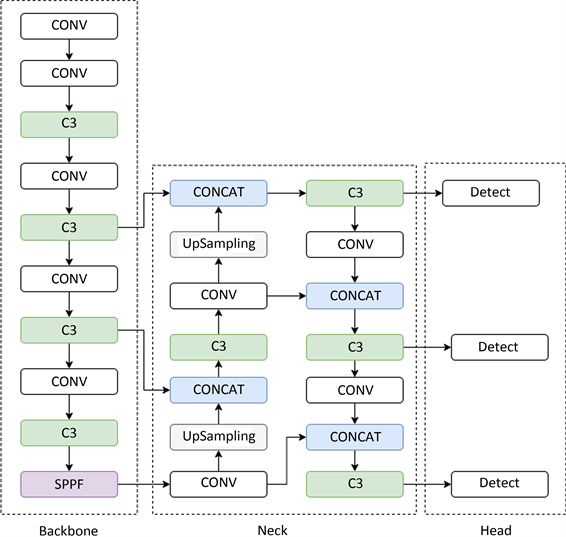
Figure 1. YOLOv5s network architecture
图1. YOLOv5s网络结构

Table 1. Different anchor box size
表1. 不同尺度的先验锚框
2.2.2. 引入特征融合结构Bi-FPN
卷积神经网络通过卷积不断的提取图像的特征,随着网络深度的增加,高级的语义特征被提取,能够大幅度提高网络对图片的识别,但与此同时,目标的位置信息也在特征提取的过程中不断被弱化。Yolov5采用FPN + PAN相结合的结构实现特征的融合,自下而上的FPN结构能够提供更强的语义信息(有利于物体分类),自上而下的PAN结构能够提供更强的位置信息(有利于物体定位),这样使得预测特征层同时具备较高的语义信息和位置信息,提高了目标检测任务精度(见图2)。
传统的特征融合只是简单的将不同特征层进行叠加和融合,而不对特征层进行区分。不同特征层对于模型的性能贡献是不同的,针对这一问题,本文采用加权双向(自顶向下 + 自低向上)特征金字塔网络Bi-FPN [21]。它引入了可学习的权重来衡量不同输入特征的重要性,能够更好的平衡不同尺度的特征信息,同时重复应用自顶向下和自底向上的多尺度特征融合。Bi-FPN的操作可如下公式(1)表示:
(1)
其中,P表示融合后的特征层,Pi表示不同的特征层,wi是一个可学习的权重参数,参数ε = 0.0001可以避免除零导致的数值计算问题。通过网络的自我学习能够在不同特征层提取关键信息,促进特征融合。
为了更好的检测出小目标交通标志,在网络结构中,多个Bi-FPN结构能够融合来自多个低层的特征,如第13层,第17层、第21层,第25层。并通过网络训练权重,平衡语义和位置信息,从而提高目标的分类和定位准确率。
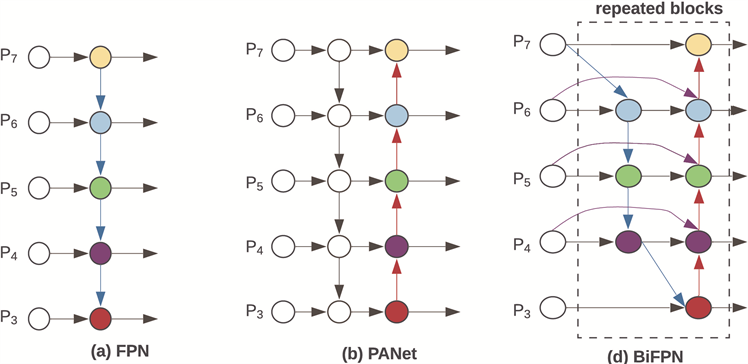
Figure 2. FPN and Bi-FPN architecture comparison
图2. FPN和Bi-FPN对比图
2.2.3. 添加注意力机制(GAM)
注意力机制的本质就是通过观察图像的全局信息,提取感兴趣的关键信息,抑制甚至过滤掉无用的背景和冗余信息,提高信息处理效率和提取关键信息的准确率。
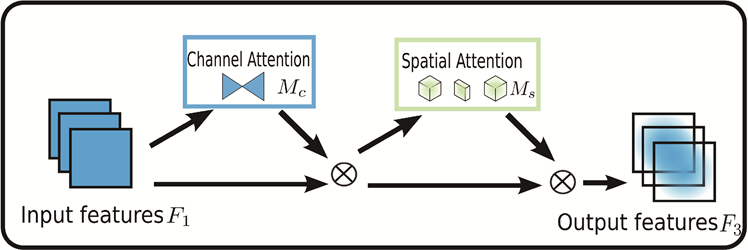
Figure 3. The overview of GAM attention
图3. GAM attention过程示意图
GAM注意力机制(Global Attention Mechanism) [22] 不同于CBAM模块(Convolutional Block Attention Module) [23],它不仅仅考虑了将注意力映射沿特征图的通道与空间两个独立的维度进行注入,更考虑了通道与空间的相互作用,引入并放大了跨维度的交互作用,在所有三个维度上捕捉重要特征。GAM attention整个过程如图3所示。
GAM attention包括通道注意力子模块和空间注意力子模块。通道注意力子模块使用三维排列在三个维度上保留信息,用一个两层的MLP (多层感知器)放大跨维通道–空间依赖性。对于输入的特征图,首先进行维度转换,经过维度转换的特征图输入到MLP,再转换为原来的维度,并进行Sigmoid处理输出(见图4)。空间注意力子模块使用两个卷积层进行空间信息融合,删除了池化层对空间位置信息的损失影响,利用通道缩减和7*7的卷积来减少通道数量,在减少计算量的同时专注于对于空间维度信息的提取(见图5)。
2.2.4. 边界回归损失函数的改进
YOLOv5的损失函数由分类损失(classification loss)、目标置信度损失(object loss)和定位框bbox回归损失(boundingbox regression loss)三部分组成。其中定位框bbox回归损失采用完全交并比损失函数(Complete-IoU loss, CIoU Loss [24])实现目标框预测。具体计算如公式(2)~(5)所示。
(2)
(3)
(4)
(5)
其中,
代表预测框和真实框,ρ两个框的中心点坐标的欧式距离,而c则是能够同时包含预测框和真实框的最小闭包区域的对角线距离,
、
代表真实框框的宽度和高度,w、h代表预测框的宽度和高度。v为预测框和真实框长宽比例差值的归一化,α为平衡因子,用来平衡长宽比例造成的损失和IoU部分造成的损失。
传统的IoU损失仅考虑了预测框和真实框之间的交并集造成的结果损失,而忽略预测框在回归过程中IoU损失对于模型收敛的影响,比如预测框和真实框完全重叠和完全不重叠的情况在计算IOU损失中没有区别,无法帮助模型收敛。GIoU [25] 引入能够同时框住真实框与预测框的最小的框,解决了真实框与预测框完全分离时IoU无法衡量两者距离的问题。DIoU引入了衡量中心点坐标的距离差异的惩罚参数p和c,解决了预测框和真实框完全重叠时,使得预测框中心点快速收敛于真实框的中心点。YOLOv5采用CIoU损失函数是在DIoU的基础上考虑到了预测框与真实框的长宽比例问题,更好的解决区域重叠问题带来的收敛低效问题。然而目前为止提出的方法中,都没有考虑到真实框与预测框框之间的方向而导致收敛速度慢的问题。这种不足导致收敛速度较慢且效率较低,因为预测框可能在训练过程中“四处游荡”并最终产生更差的模型。Gevorgyan Z.等人提出了全新的SIoU [26] 损失函数。
SIoU考虑了真实框和预测框之间的向量角度,重新定义了惩罚指标。具体包含四个部分:角度损失(Angle cost)、距离损失(Distance cost)、形状损失(Shape cost)、IoU损失(IoU cost)。
a) 角度损失
(6)
(7)
(8)
(9)
如图6所示,角度损失为Λ,计算公式为公式(6)~(9),其中
为预测框中心点坐标,
为真实框中心点坐标,σ表示真实框和预测框中心点的距离,ch为真实框和预测框中心点的高度差。
b) 距离损失
(10)
(11)
距离损失为Δ,计算公式为公式(10)~(11),其中cw和ch为真实框和预测框最小外接矩形的宽和高。
c) 形状损失
(12)
(13)
(14)
如图7所示,形状损失为Ω,计算公式为公式(12)~(14),其中
分别为预测框和真实框的宽和高。θ为超参数,控制对形状损失的关注程度,为了避免过于关注形状损失而降低对预测框的移动。最终SIoU损失表达式如公式(15)所示。
(15)
在边框回归损失中,SIOU Loss中各项损失考虑全面,使得收敛速度更快,精度更高,优于原网络中的CIOU Loss,因此本文采用性能更优的SIOU Loss边框回归损失函数。如图8所示为本文改进后的YOLOv5网络模型结构。
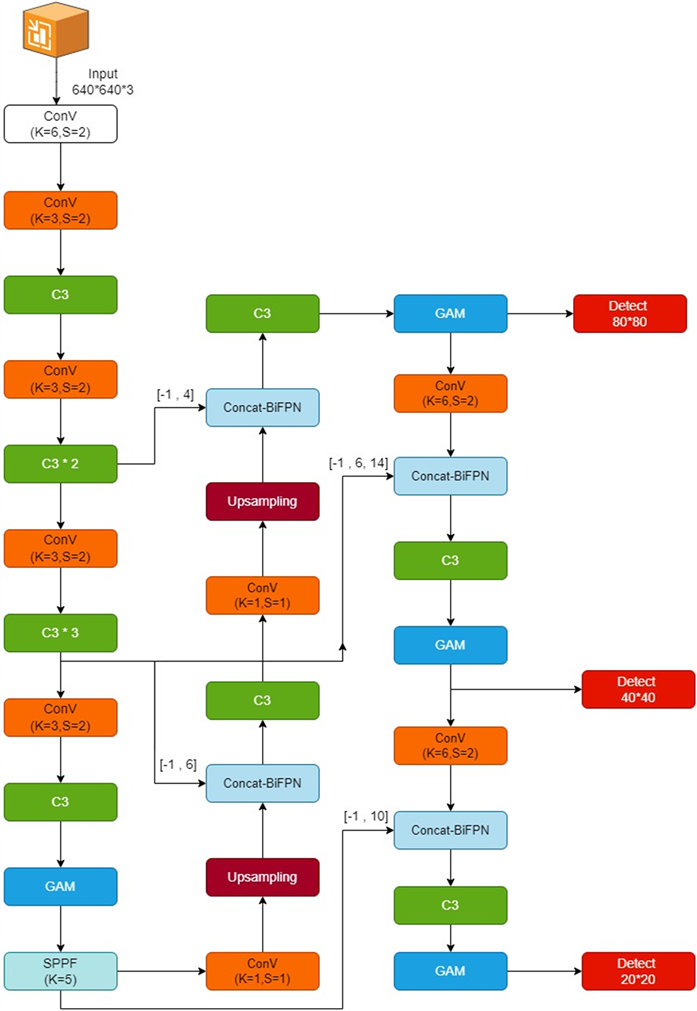
Figure 8. Improved YOLOv5 network architecture
图8. 改进的YOLOv5网络结构图
3. 实验结果与分析
3.1. 数据集
中国交通数据集CCTSDB2021 (CSUST Chinese Traffic Sign Detection Benchmark 2021)由长沙理工大学综合交通运输大数据智能处理湖南省重点实验室张建明老师团队制作完成 [16]。数据集有17,856张图片,其中训练集16,356张,测试集1500张(见表2)。目前标注数据有三大类:指示标志(Mandatory)、禁止标志(Prohibitory)、警告标志(Warning) (如图9所示)。图片分辨率有860*480,1280*720,1920*1080不等。交通标志像素大小不同并按照5个标准(XS, S, M, L, XL)进行划分(见表3)。

Figure 9. Chinese traffic signs with meaningful classification
图9. 交通标识示意图
Table 2. Traffic sign dataset classification and amount
表2. 数据集交通标志类别及数量
Table 3. Cropped image size and amounts
表3. 目标大小分类及数量
3.2. 实验环境和设定细节
本文实验在Linux操作系统Ubuntu18.04下进行,显卡为Geforce GTX 1080Ti,11GB运行内存。整个实验基于深度学习框架pytorch 1.7,实验环境是python3.8,GPU加速软件为CUDA11.2。实验的超参数设定如下:训练100 epochs,批样本数量(batch size)为32,随机梯度下降法(SGD),动量(momentum) 0.957,权重衰减(weight decay)为0.00048,初始学习率为0.012。
3.3. 评价标准
本文主要使用目标检测模型常用的评价指标。包括精确度(precision, P)、召回率(recall, R)、平均精度均值(mean average precision, mAP)、F1分数(F1 score)和每秒处理帧率(FPS)。各项评价指标计算公式如下:
其中,TP为将正类预测为正类的数量,FN为将正类预测为负类的数量,FP为将负类预测成正类的数量,TN为将负类预测成负类的数量,N表示类别数。
3.4. 实验结果及分析
为了验证改进的YOLOv5网络模型的目标识别性能,本文复现了原始的YOLOv5 (v6.1)模型在交通标志数据集中的表现(实验Repo),以此为参考基线,对所有改进点进行了消融实验,并将融合所有改进点的改进YOLOv5网络模型(实验Imp-YOLO)与参考基线进行了对比。实验结果如表4所示。
由实验数据可知,改进的YOLOv5模型在各项指标中都获得了显著提升。在原始模型的基础上引入GAM注意力模型,能够更好利用空间位置信息和特征通道信息以及二者之间的交互作用,在三个维度捕捉特征信息,对于依赖位置信息的密集检测任务具有更好的检测效果,召回率R提升了3.23%,定位mAP提升了3.2%。Bi-FPN结构使用加权的方式进行特征融合,可以将低层特征与高层特征进行有效的平衡和融合。针对目标数据集小目标较多的特点,高效的特征融合有效的提升了模型对于特征的提取能力,使模型准确度P提升了4.0%。最后引入SIoU作为预测框回归的损失函数,解决了原始CIoU没有考虑真实框与预测框框之间的方向不同而导致收敛速度慢的问题,提高模型边界框的定位精度3.27%,检测速度也提升了3.72FPS。
总体而言,相比较原模型YOLOv5,准确度P达到了92.8%,提升了4.4%,召回率75.6%,提升了2.6%,F1-socore为83.32,提升了3.48%。mAP@0.5:0.95提升10.03%,模型高精度边界拟合能力显著增强。在保证较高的检测精度的同时,检测速率达208.33FPS能够满足实时性需求。实验结果表明注意力机制、特征融合和边框回归损失函数的共同优化可以有效地提升交通标志的检测的效果。图10为改进前后检测结果对比。
由图10可以看出,原始的YOLOv5算法训练的模型在检测中存在漏检的情况,尤其是在连续密集小目标和夜晚环境复杂的情况下,检测效果欠佳。第一张图漏检一个指示标识,第二张图在夜晚漏检两个禁止标识,第三张图漏检中间的禁止标识。而本文改进的YOLOv5算法成功的在图像上检测出了数据集中标注的所有交通标志,并且定位准确,无漏检现象。
在不同类别的检测上,改进的YOLOv5模型相较于原始的YOLOv5定位准确度提升更为明显(见表5)。在三大类别交通标志的定位mAP@0.5:0.95上分别达到了62.5%、61.2%和58.9%。在禁止标志定位精度提升了9.7%,在警告标志定位精度提高了8.27%,在指示标志上定位精度提高了12.1%。在不同尺寸的目标检测当中,对于密集小目标的提升相较与大目标更为明显(见表6)。对于尺寸小于210像素的XS目标提升达到了13.83%,引进的注意力机制和特征融合对于大量密集的小目标更为关注,使之相较于大目标提升明显。
Table 5. Experiments result for classification
表5. 不同类别的实验检测结果
Table 6. Experiments results for cropped image size
表6. 不同目标大小的实验结果
4. 结论
本文针对交通标志数据集中目标小且密集,背景复杂且多变的特点,提出了一种改进的YOLOv5的目标检测算法。通过引入GAM注意力机制,提高网络的特征提取能力,忽略无关的特征,引入Bi-FPN结构加强高级语义和底层特征之间的平衡和融合,通过替换边界框回归损失函数,加快模型的收敛速度。实验表明,本文提出的改进算法与原始算法相比,能够显著提升目标定位精度,减少漏检。
基金项目
本文获得感谢国家自然科学基金(资助号:12261021,11801111)、贵州省科技计划项目([2019]1122)和贵州省科技平台人才资助项目([2018]5781)联合资助。