摘要: 目的:构建心源性休克患者院内死亡预测模型。方法:利用MIMIC-III数据库,收集人口特征、实验室检查、合并症等87个指标并进行特征选择后,使用随机森林、Logistic回归、XGBoost、卷积神经网络算法,构建预测模型。用敏感性、特异性、曲线下面积、准确性来比较这4种模型的性能。结果:在这项研究的804名患者中,有209名患者(26%)出现院内死亡。在预测院内死亡时,四个模型的接收器工作特征曲线(ROC)的曲线下面积(AUC)在0.757至0.848的范围内。在所有模型中,XGBoost的灵敏度最高(87.3%),特异性(81%)和准确性最高(84.6%)。结论:机器学习算法可以准确预测心源性休克患者院内死亡率,尤其是XGBoost模型。
Abstract:
Objective: To construct a prediction model for in-hospital death in patients with cardiogenic shock. Methods: Using the MIMIC-III database, 87 indicators of demographic characteristics, laboratory tests, and comorbidities were collected and then feature selection. Logistic regression, random for-est, XGBoost, and convolutional neural network algorithms were employed to build models. Sensi-tivity, specificity, accuracy, and area under the curve were applied to access the performance. Re-sult: Among 804 patients enrolled in this study, 209 patients (26%) died in hospital. In the predic-tion of the in-hospital death, the areas under the curve (AUCs) of the receiver operating characteris-tic curves (ROCs) of the four models ranged from 0.757 to 0.848. Among all models, XGBoost achieved the highest sensitivity (87.3%), specificity (81%) and accuracy (84.6%). Conclusion: Ma-chine learning algorithms can accurately predict the in-hospital mortality of patients with cardio-genic shock, especially the XGBoost model.
1. 简介
心源性休克是由于原发性心功能不全而导致的各个器官低灌注的危重状态。引起心源性休克的原因很多,最主要的原因是急性心肌梗死,还包括心律失常、主动脉破裂和心包填塞 [1]。虽然心源性休克的发病率低于其他致命疾病,但其住院死亡率高达约60.1% [2]。尽管在早期预防、及时诊断和积极治疗以挽救心源性休克患者方面取得了进展,但心源性休克仍然是死亡的主要原因之一 [3]。
在心源性休克患者管理中,对其进行风险评估是非常重要,全面评估患者情况,减少院内死亡的发生对于这种复杂患者至关重要。机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科,已经在生物信息学、生态学、医学、遗传学、遥感地理学等多领域开展的应用性研究 [4],对于数据的审查分析更加科学,能考虑到内在相关性,本研究利用公开数据库,通过机器学习方法,分析影响心源性休克患者的院内死亡相关危险因素。
2. 研究对象
重症监护医学信息市场(MIMIC-III)是可公开获得的重症监护数据库 [5]。MIMIC-III数据库的建立得到麻省理工学院和以色列女执事医疗中心的批准。该数据库包含生命体征,药物,实验室测量值以及其他成年患者(18岁或18岁以上)入院的其他重要项目。本研究为回顾性研究,作者获得美国国立卫生研究院保护人类研究参与者考试的批准(ID: 35892903),并且获取访问MIMIC-III数据库的权限。使用PgAdmin并通过结构化的查询语言提取数据库中资料 [6]。
2.1. 纳入标准
1) 年龄位于18到89岁之间;2) 基线数据缺失率 < 10%。同时,如果数据库期间有超过一项入院记录,只会选择第一次入院。根据国际疾病分类第9版临床修改诊断代码(ICD-9:785.51)确定诊断为心源性休克的患者。
2.2. 研究指标
包括年龄、性别、既往史、实验室指标等。所有指标均为进入ICU的24内的数值,包括同一指标的最大值、最小值。删除某一项指标缺失值大于30%,最终共纳入87项指标进行研究。
2.3. 研究方法
所有数据分析及模型建立使用R (4.0.3)和Python (3.7.0)进行处理,对于缺失值使用多重插补法进行填充。符合正态分布的计量资料以均数 ± 标准差(x ± s)表示,组间比较采用两独立样本t检验;计数资料比较采用卡方检验或Fisher确切概率法;将院内存活和院内死亡组按照7:3随机分为训练集和验证集。采用递归特征消除法进行特征筛选,即根据底层模型的特点,选出最重要的特征,把选出来的特征放到一边,然后在剩余的特征上重复这个过程,直到遍历了所有的特征。在这个过程中被消除的次序就是特征的排序。将筛选后的特征应用到模型中,以是否发生院内死亡为结局变量。在训练集中分别建立Logistic回归、随机森林、XGBoost和卷积神经网络模型 [7];在构建模型过程中,通过不断调整各项参数,使每个模型均达到最佳的表现,用验证集来验证模型的表现。模型的评估采用敏感度、特异度、准确率、曲线下面积来进行衡量。特征选择及模型构建的过程在图1。使用Delong test法计算两个ROC曲线之间是否存在的统计意义。使用沙普利值(SHAP value)对最优模型进行可视化解释,寻找模型中各个变量的贡献程度 [8]。
3. 结果
3.1. 基线资料
在804例心源性休克患者中,563例(70%)随机进入训练数据,241例(30%)进入验证数据。表1显示是否发生院内死亡之间的基线变量的区别,其中两组在许多因素之间具有差异有统计学意义(P < 0.05)。

Table 1. Comparison of baseline information of patients with and without in-hospital mortality
表1. 院内是否发生死亡患者基线资料比较
3.2. 构建模型的结果
构建的Logistic回归模型、随机森林模型、XGBoost模型及卷积神经网络在验证集中进行内部验证,结果显示,各模型的AUC均较高,依次为0.786、0.826、0.848、0.757。卷积神经网络模型表现一般,在特异性、敏感性、准确性依次为0.687、0.852、0.751。XGBoost模型的表现最优,其敏感度为为0.81、特异度为0.873、准确率为0.846,各个模型的表现情况如表2所示,ROC曲线在图2中展示。经过Delong test检验,XGBoost模型明显优于Logistic 回归(P < 0.05)。XGBoost模型中各指标对应的贡献度如图3所示,年龄、白细胞最小值、平均收缩压是最具预测性的特征,其次是最高体温和红细胞分布宽度最小值。同时,我们也对XGBoost模型中各个特征进行总体可视化。在图4中,每一行中的蓝色和红色点代表了特定变量的低值到高值的参与者,而X轴给出了SHAP值,它给出了对模型的影响:即它是否倾向于推动事件发生(SHAP的正值)或事件未发生(SHAP的负值)。例如:图4中显示年龄是最重要的特征,当蓝色点主要集中在SHAP值小于0的区域,红色点主要集中在SHAP值大于0的区域,可见年龄小会降低院内死亡发生发风险,年龄越大会增加院内死亡发生的风险。
Table 2. Comparison of the prediction performance of the models in the test set
表2. 各模型在测试集中的预测性能
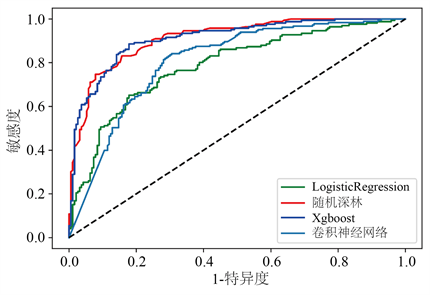
Figure 2. Area under the curve as a measure of predictive performance of whether in-hospital death occurs in patients with cardiogenic shock
图2. 曲线下的面积作为衡量心源性休克患者是否发生院内死亡的预测性能

Figure 3. Feature importance graph for machine learning models
图3. 机器学习模型的特征重要性
 每一行中的蓝色和红色点代表了特定变量的低值到高值的参与者,而x轴给出了SHAP值,它给出了对模型的影响:即它是否倾向于推动事件发生(SHAP的正值)或事件未发生(SHAP的负值)。
每一行中的蓝色和红色点代表了特定变量的低值到高值的参与者,而x轴给出了SHAP值,它给出了对模型的影响:即它是否倾向于推动事件发生(SHAP的正值)或事件未发生(SHAP的负值)。
Figure 4. The first 20 clinical variables affecting the model in the Xgboost model
图4. Xgboost模型中前20个影响模型临床变量
4. 讨论
心源性休克在是患者心脏输出功能衰竭的极期表现,具有病死率高的特点,因此,在心源性休克早期评估中,识别高危患者,积极采取各种措施具有重要意义。既往关于心源性休克的风险研究局限于危险因素、预后探究 [9],仅少数基于危险因素的预测模型研究 [3]。机器学习是指机器通过分析大量数据来进行学习,其属于人工智能的一部分,重视寻找数据中的关联。与传统的统计学不同的是,机器学习更关注模型的预测效果,即该事件是否发生。Shin发现机器学习与传统统计模型在预测心衰患者再次入院和死亡的风险中具有更好的判别力 [10]。D’Ascenzo利用基于机器学习的方法来识别急性冠状动脉综合征后全因死亡,心肌梗塞和大出血的发生率 [11]。
在本研究中,我们使用4种流行的机器学习算法构建心源性休克患者院内死亡模型,经Delong test检验显示,机器学习算法表现明显优于传统的Logistic回归模型,其中综合预测效能最优的为XGBoost模型,AUC为0.848。
相对于深度学习中出现黑盒理论,利用SHAP法能反映出每一个样本中的特征的影响力,而且还表现影响的正负性。本研究中的XGBoost提示,年龄、炎性指标、体温是模型中影响院内死亡的重要因素。年龄是判断许多疾病预后的经典指标。高龄患者预后在绝大多数疾病中相对较差,年龄同时也是心源性休克患者预测预后的独立的危险因素。研究显示在使用ECMO、机器循环通气患者中年龄与患者住院死亡率的增加呈线性相关 [12]。炎症指标在心源性休克患者中扮演重要角色。休克患者常常出现严重的全身性炎症表现,实验室检查中可发现典型炎症介质水平,如C反应蛋白,白介素-6升高 [13] [14]。外周灌注降低引起内皮细胞的损伤,各种机制导致炎症因子的聚集,随着缺血时间的延长,最终引起各个器官功能障碍。红细胞分布宽度近几年也被认为是一个新的炎症指标来预测患者预后。越来越多的研究发现红细胞分布宽度在心脑血管疾病中有着良好的预测价值。Kim研究指出在严重脓毒症或败血性休克患者住院期间红细胞分布宽度较基线明显增加与不良的临床预后相关 [15]。对于心源性休克患者,红细胞分布宽度的升高与患者全因死亡风险增加相关 [16]。
本研究中使用的XGBoost模型,是于2016年发布的一种新算法,但其在数据科学界获得了广泛的欢迎 [17]。因为它是一种高效的、可扩展的分类和回归的模型,可以处理稀疏,复杂和非线性的数据类型,这与临床上多变的数据相一致。
综上所述,从模型的特异性、敏感性方面来看,本研究搭建机器学习心源性休克院内死亡率预测模型是成功的,其具有良好的稳定性,可以提前预警高危心源性休克患者,根据预测结果可以实行积极干预。模型中使用的数据均为临床常见的指标,便于获得,具有很强的可操作性和推广性。
5. 研究的局限性
本文利用了公开数据库进行分析,数据详实,但仍需要进一步外部验证模型的准确性,但考虑到在研究开始随机分组,分为训练集、验证集,所获得的模型具有一定的可靠性,但仍需要进一步的研究。
参考文献
NOTES
*通讯作者Email: lianzx566@163.com