1. 引言
随着技术的进步,以及人类对智能服务机器人的要求越来越高,兼具高机动性能、智能化交互的机器人正在成为全球的研究焦点。并且现阶段新冠肺炎疫情防控压力犹存,减少公共场所人员接触是防止疫情扩散的有效手段,在这样的背景下,用机器人代替人工的需求被激发。
就目前而言,在机器人方面的研究如雨后春笋般涌现。但许多的研究方向都是基于具有极佳运动控制系统的仿生机器人,刘京运 [1] 所阐述的四足机器人进化史介绍了仿生机器人在运动控制方面的快速发展。在基于深度强化学习方面的机器人路径规划 [2] 和机器人运动控制 [3] 方面都有长足的发展。在大多数的服务机器人工作的环境下,极佳的运动控制系统和仿生机器人的优势都不能够得到十足的体现,在服务机器人领域,最为关注的问题还是资源的利用和人机交互的优化方面。而伴随着5G技术的发展与突破,通过云端建立云服务机器人系统是提升机器人计算和存储资源的重要途径。基于SOA的云服务机器人框架设计 [4] 主要针对于资源共享负载均衡进行了阐述,具体针对与机器人的运转并未过多介绍。也有部分针对于机器人操作和目标检测相结合的研究,例如结合目标检测和机器人抓取实现番茄的采摘 [5] 、水面垃圾的清理 [6] 以及针对识别算法进行优化,提升机器人的抓取成功率 [7] ,但大都是在针对于固定任务场景下的对单项任务的完成或是抓取的运动策略方面的优化。鲜有涉及到云机器人交互设计、多场景任务模式等方面的研究。虽然目标检测已应用在各个广泛领域,但是云服务机器人并未得到广泛的应用,目前,在基于云端机器人系统向目标检测应用方向扩展的研究较少。
因此,为解决多适应场景下的基于云服务机器人的目标检测算法的实现问题。本文以智能服务机器人在仿真咖啡厅场景下的多种交互操作任务为基础,将YOLOv5目标检测算法结合机器人自然语音理解、导航行走、物品交互等多模态技术。通过达闼科技 [8] 的HARIX海睿云端大脑完成对云服务机器人的控制,让目标检测算法能够上传至云端,并在机器人上得到调用实现,达到实现多应用场景下目标检测的实现,能够完成识别并触发空调和灯的控制开关、冲泡咖啡、倒水等多种应用场景下的任务实现。
2. 总体设计
结合功能需求,本作品需要以下6个方面的支持,分别是RDK蓝图设计、数据采集和处理、YOLOv5算法训练、算法镜像部署、Blender动作设计、Smart Voice智慧语音。技术方案主要是采用YOLOv5算法训练识别模型,使用docker将模型封装为镜像上传至云端,进行RDK蓝图编程调用云端部署的算法,使用语音驱动意图进行识别,使用Blender动作进行位姿的调整,完成各项任务。在整个实现的过程中,研究方法主要包括理论研究、仿真实验、对比分析、验证优化等方法,在对机器人本身进行操作的过程中,需要通过不断地仿真实验和对比分析进行调整参数的设置,例如在蓝图的设计中要所有的蓝图节点能够按顺序准确运行,每个节点函数的调用都要合理合规,在动作设计中,要求对位姿能有精准的调整,对抓握等动作要有准确的设计,以求达到最佳的使用效果。在对算法的训练中,要不断地进行验证优化,让算法在准确度和泛化能力上都有较优的效果。研究方法主要包含作品的技术路线,如图1所示。
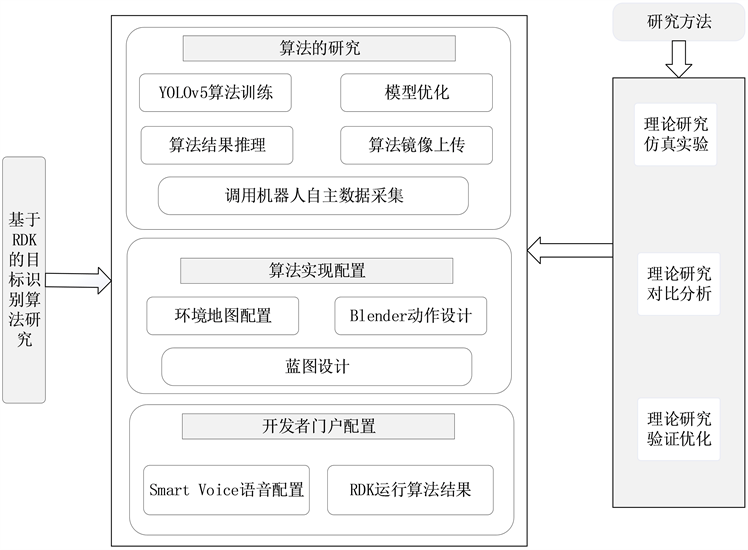
Figure 1. Overall system architecture diagram
图1. 系统总体架构图
3. RDK蓝图设计
蓝图也被称为可视化编程,将C++语言的代码可视化,通过逻辑性编入到引擎中。在此主要包含数据采集和算法实现两个蓝图的设计。
3.1. 数据采集蓝图的设计
在虚拟环境中进行数据采集,需先通过Smart Voice语音系统调用数据采集的蓝图事件,再通过导航
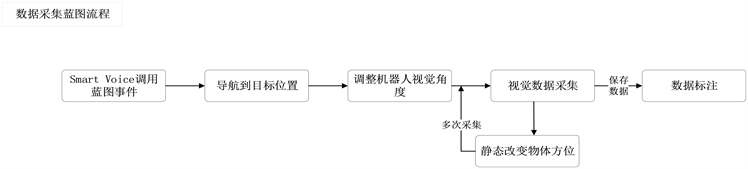
Figure 2. Design drawing of data collection blueprint
图2. 数据采集蓝图设计图
让机器人到达指定位置,经过对机器人位姿的调整后使目标物体在视觉范围内,便可开始调用数据采集蓝图开始采集数据,每采集一张图片都对目标物体进行静态调整,调整后便可继续采集,以提高数据的泛化能力。数据采集的蓝图设计如图2所示。
数据采集可以通过for循环进行多次采集,避免了单次采集需要大量调用相同蓝图节点,减少了蓝图节点的冗余,循环采集部分的蓝图如图3所示。
以虚拟环境中的开关为例,在图片中包含选择采集的开关并且相应开关有红色方框进行标识,在此需要进行准确的位姿调节,摄像头的角度向下倾斜,机器人的机身向右轻微旋转,便可以采集到开关在图片中央的数据,为提高数据的多样性,可以在机器人的位姿上进行多种调整,以获得不同效果的大量数据,如图4所示。

Figure 4. Data acquisition results at the switch
图4. 开关处数据采集结果
3.2. 算法调用蓝图的设计
实现目标检测算法的运行,首先,要通过Smart Voice语音调用蓝图事件,驱动导航到目标位置,在目标位置进行简单的位姿调节后,调用算法识别蓝图节点,在识别结束后,可通过语音反馈结果,并结合检测结果判断是否要进行后续的动作运行。算法调用的蓝图设计如图5所示。
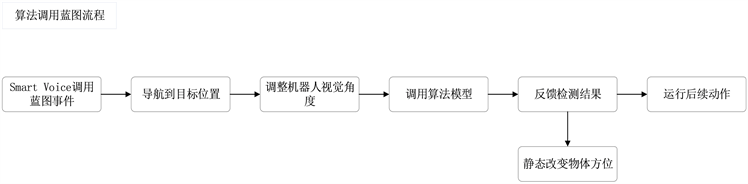
Figure 5. Design drawing of algorithm call blueprint
图5. 算法调用蓝图设计图
蓝图设计是整个机器人运行的基础,机器人通过蓝图的流程顺序逐个完成相应节点的任务,节点的内容环环相扣,当上一节点的内容没有完成时,很大概率会影响到后续节点的运行,所以蓝图的设计要经过多次的模拟实验,以求各个环节都能达到理想的效果,最终完成整个动作流程。
4. YOLOv5目标检测算法
4.1. 算法架构
在识别算法上采用YOLOv5 [9] [10] 进行算法训练。YOLO是端到端目标检测算法的代表,与R-CNN系列最大区别是不需求取候选区域,只需通过一个单独的CNN网络就能够实现目标的定位和识别。YOLO的显著特点是检测速度快,但其缺点是精度相比于Fast-RCNN等有所下降,是一种典型的精度换速度的做法,网络结构图如图6所示。
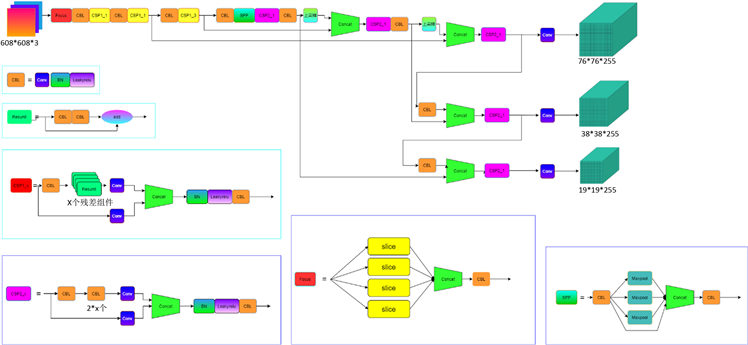
Figure 6. YOLOv5 network structure diagram
图6. YOLOv5网络结构图
YOLOv5的网络结构主要包括以下四个部分,各个模块功能如图7所示。
a) 输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放;
b) Backbone:Focus结构,CSP结构,SPP (Spatial Pyramid Pooling [空间金字塔池化]);
c) Neck:FPN + PAN结构;
d) Prediction:GIOU_Loss。
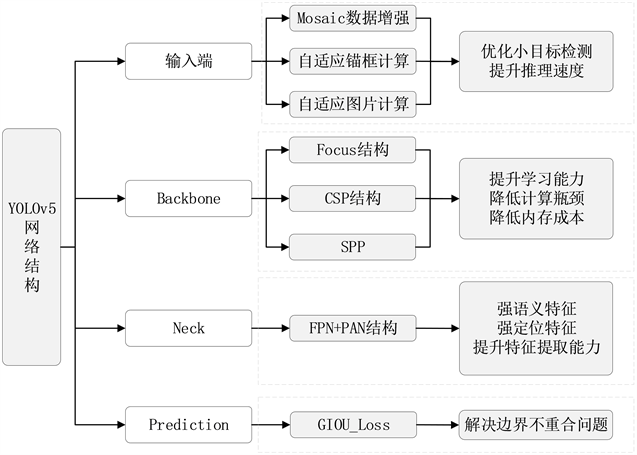
Figure 7. YOLOv5 structure classification diagram
图7. YOLOv5结构分类图
4.2. 算法优化
算法训练时先将数据集图片导入输入端经Mosaic数据增强、自适应锚框计算、自适应图片缩放后进入Focus切片,通过卷积核得到特征图,然后进入Neck,经过FPN + PAN操作,使用CSP2加强网络特征融合能力,输出端计算Bounding box使用GIOU_Loss做损失函数,输出结果。
YOLOv5小目标检测效果不佳的原因之一便是小目标样本的尺寸较小,而采样倍数较大、较深的特征图很难学习到小目标的特征信息,因此,增加小目标检测层对较浅特征图于较深特征图拼接后进行检测,添加[5,6,8,14,15,11]的小检测层。
在YOLOv5中插入卷积注意力模块CBAM,CBAM可以无缝衔接到CNN架构中,并且对算力和内存的开销不会产生较大影响,可以与CNN网络一起进行端到端的训练。若有一个中间特征作为卷积层输出,则根据层的深度每个这样的特征层都会捕获边缘、形状等信息,以获取更复杂的输入语义表示。使得网络在训练过程中更多地关注特征图的重要部分。
4.3. 模型训练
将在仿真环境中收集的图片进行标注作为模型训练的数据集。在YOLOv5/data文件夹下创建自己数据集的路径、种类数量、种类名称的.yaml文件,将自己的数据集以data/image/train、data/image/val、data/labels/train、data/labels/val的结构来组成。然后使用python train.py—img 640—batch 8—epochs 500—data data/dataset.yaml—cfg yolov5m.yaml—weights yolov5m.pt的命令运行,结果会在YOLOv5文件夹下的runs/train中。
5. 机器人运行实现
5.1. 机器人运行规划
在算法训练优化完成后得到算法模型,还需将算法模型进行镜像制作并上传,在结合机器人语音匹
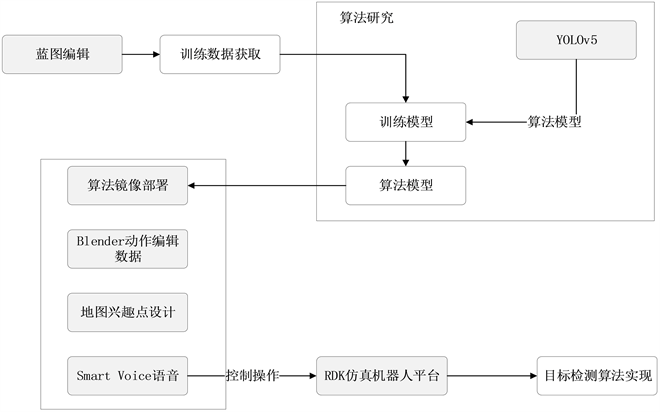
Figure 8. Design drawing of algorithm implementation
图8. 算法实现设计图
配及动作设计的基础上,才能驱动机器人进行目标算法的识别。算法的实现设计包含算法镜像部署、Blender动作设计、地图兴趣点设计、Smart Voice等4个部分,如图8所示。
5.2. 算法镜像部署
将已经训练好的模型通过docker制作镜像,再将镜像上传到云端以获得唯一域名地址,通过调用地址直接运行识别模型。在蓝图中通过ObjectDetect类可以调用模型。将已配置好使用对应镜像的蓝图进行打包上传,再将已经上传的技能与机器人选择的角色进行配对绑定,则配对成功的机器人角色便可再虚拟环境中使用训练好的目标识别算法。基于RDK平台通过Smart Voice语音系统对已经设置好的机器人角色进行任务调用,即可在仿真环境中运用算法进行操作。
5.3. Blender动作设计
机器人的动作规划通过Blender平台和蓝图中关节组数的节点进行编辑规划,经过实际的测试,setJointStates节点设置关节数组来产生的动作更适应于瞬间动作,通过Blender进行帧动作编辑,对关键帧进行动作设定,在数据导出时会自动平滑地补充间隙帧的数据,减少了对冗余信息的重复操作,从而大量缩短了动作设计时间。在蓝图中拖拽PlayMotionAsync节点来播放指定路径动作,因此,在设计动作的时候需要与物体的位置和机器人所处的位置相匹配,否则,动作正确也难以达到预期效果。
首先,通过RDK环境获取物体的位置信息,利用Blender编辑器按时间轴的编辑方式编辑每个关节的状态,并添加蓝图给出到达物体的路径策略,控制仿真机器人实现位姿的调整和目标物品的识别和抓取。根据以上任务描述,项目需要进行的步骤包括:获得仿真环境下机器人与物品之间的高度和角度关系、Blender编辑器控制不同关节运动的实现、语音下兴趣点导航和动作之间的蓝图配合等。动作规划如下图9所示。
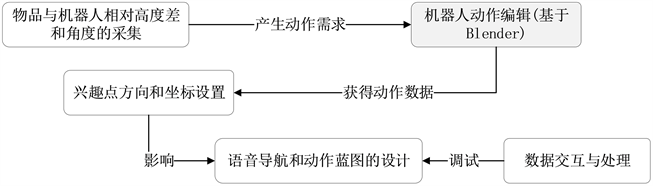
Figure 9. Design drawing of Blender action planning
图9. Blender动作规划设计图
如图10所示,采用不同视角获取的方案,进行2D基本几何规划方法,可以有效提高获取物体信息的效率,采用多次信息对比,减小误差,以提高精准度。由于导航下会将位姿进行更改,一定程度上需要多次实验不同坐标和角度的兴趣点,提高动作的精准度。此方法适用于粗略估计物品与本体之间的相对位置,实际调整数据,需要对关节进行多次调整,才能获得较为精准地动作数据。将最终获得的合格的数据导出到本地,再通过蓝图节点PlayMotionAsync调用已导出的动作数据,便可以通过蓝图运行动作数据完成相应的任务需求。
5.4. 地图设计
在开关处包含控制灯、空调、窗帘、门的多个开关,并且开关的碰撞体积极小,需要精准调节兴趣点的位置方向,并且还需精确设计动作规划,才能精确地执行对各个开关进行触发。如图11是各个不同开关之间的兴趣点设置。
5.5. Smart Voice语音设计
在Smart Voice网站中设置服务项目,添加GoToCurtain、GoToDesk、GoToCoffee等意图。当语音识别结果命中该意图时,控制蓝图中对应的程序将开始执行,即完成该意图所对应的机器人动作。Smart Voice相当于一个将语音转换为文字的过程,在转换为文本之后与已经设定的文本内容进行对比,如果有

Figure 11. Display diagram of navigation point setting at the switch
图11. 开关处导航点设置展现图
比对成功则进行任务执行,如果没有比对成功则任务不在设定范围之内,所以现需要设置大量的替换词等,让一种任务的执行尽可能包含多种的语言表达形式。
6. 项目实现
在实际测试的过程中,需要实现图12蓝图所示的调用,通过语音导航到目标位置后再通过调用URL地址运行识别模型。可得如图13和图14所示结果,识别的大致准确度分别为90%和92.3%。完成目标识别。

Figure 13. Detection and identification results of kettle
图13. 水壶检测识别结果

Figure 14. Detection and identification results of the switch
图14. 开关检测识别结果

Figure 15. Comparison diagram of lights on and off
图15. 开灯关灯对比图
在对物体进行目标识别之后,对应的蓝图节点将识别结果返回,后续的蓝图节点根据返回的结果判断执行何种方案。
在图15和图16中,展示的是在进行目标检测识别之后实际任务的执行完成。
7. 总结
在实际运行的测试过程中,实验测试效果与模型检测效果相差无异,结果表示,识别算法在实际运用中抗干扰能力较强,并且基本可以达到实际需求的准确度。根据机器人运行的蓝图可以实现算法的调用和检测分析。在一定程度上扩展了机器人的可执行性。在仿真环境中的识别应用展现得较为完善,例如可以识别到水壶,并在识别完成之后,实现倒水的动作,基本达到了预期的结果。