1. 引言
文本分类在舆情研究、问答系统、客户的信息服务等诸多方面起到了巨大的作用,怎样对文本进行合理的分类,成为当前自然语言研究方面探讨的焦点课题。不少国内外专家已经提供了许多模型来处理这一现象,包括循环神经网络(Recurrent Neural Network, RNN) [1]、长短期记忆网络(Long Short-Term Memory, LSTM) [2]、卷积神经网络(Convolutional Neural Networks, CNN) [3]、自注意力机制模型 [4] 等。
本文模型基于BiLSTM层使用注意力机制在输出数据中获得注意力值,进而对层进行归一化;同时把BiLSTM通道的结果和最初的词向量数据结合,在两个卷积层中根据自注意力赋予词卷积运算后结果的权重,分别进行批归一化,重复两次之后分别进行池化,最终将CNN通道池化后的特征信息与BiLSTM通道信息进行融合,结果表明本文提出的模型具有较好的分类效果。
2. 相关工作
Bengio等 [5] 构建出神经网络语言模型(NNLM),为神经网络在NLP的发展指明思路。为获得更高效的词向量表示,Mikolov等 [6] 提出两种词向量模型,CBOW (Continuous Bag-of-Words)和Skip-Gram。由于CNN能够准确地提取文本的局部特征,RNN能够有效地处理上下文数据。Zhang等 [7] 将LSTM和CNN相融合,最终验证了RNN与CNN进行组合的有效性。吴汉瑜等 [8] 和梁顺攀等 [9] 都主张将BiLSTM和CNN融合,利用双向传输机制获得文本完整的上下文数据,最终得到特征融合可以有效提高文本分类的准确性。张小川等 [10] 将BiGRU与CNN结合,采用CNN获取词向量的局部表示,利用BiGRU获取全局上下文表示,结果表明所提模型具有良好的文本建模能力。
自注意力机制能够对文本的重要特征聚焦,所以,有些研究人员将以上三个模型组合起来,运用各自优点来获得更丰富的文本信息。陶志勇等 [11] 将自注意力机制引入BiLSTM,用于短文本分析;蒲相忠等 [12] 将自注意力机制引入卷积神经网络;邓朝阳等 [13] 在门控循环单元的基础上设置注意力门,加强特征信息交互,以上模型均得到了较好的分类结果。陈农田等 [14] 提出一种多通道CNN_BiGRU_att中文文本分类模型,模型使用CNN获取局部特性,使用BiGRU获取上下文的全局信息;陈可嘉等 [15] 提供了一个基于自注意机制和多通道CNN的SAttBiGRU_MCNN文本分析模型,在仿真实验结果中取得了良好成效,提高了文本分类的准确性。
3. MAC_BiLSTM文本分类模型的构建
3.1. 整体模型结构
MAC_BiLSTM文本分类模型主要由三个部分组成:第一个部分是由BiLSTM、自注意力机制以及层归一化构成的BiLSTM通道;第二个部分是由通过BiLSTM和自注意力机制后的特征向量,与最初词向量嵌入层融合而成的特征向量组成;第三个部分是由CNN拼接而成的并行通道组成,该通道输入向量为第二个部分输出结果。其中,BiLSTM通道主要用于获取文本信息中的长距离依赖关系,再将BiLSTM通道输出结果经过CNN通道可进一步对文本的局部特征信息进行提取,从而获得更加准确的文本信息。模型具体结构如图1所示。
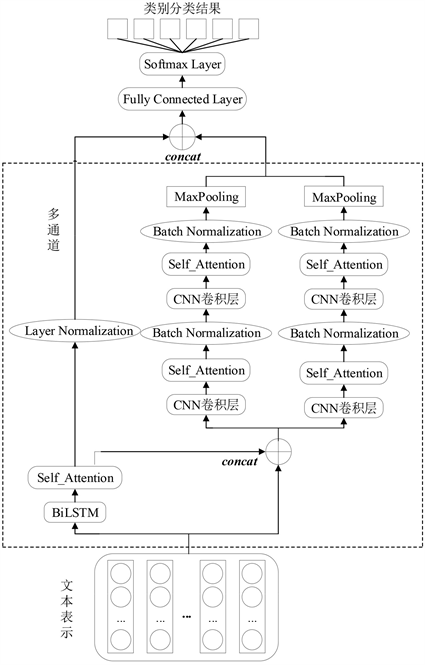
Figure 1. MAC_BiLSTM text classification model
图1. MAC_BiLSTM文本分类模型
3.2. 文本表示
Word2vec目前主要有两种模型来学习单词的分布式表示,一种是使用中间词来计算该单词上下文的Skip-Gram,另一个是通过上下文数据来估计中间单词的CBOW。本文训练词向量主要使用Skip-Gram模型,其网络结构图如图2所示。
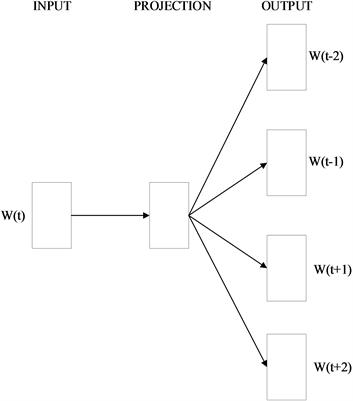
Figure 2. Skip-Gram structure diagram
图2. Skip-Gram结构示意图
3.3. BiLSTM通道
3.3.1. BiLSTM + Attention
LSTM模型t时刻的计算过程如下:
(1)
(2)
(3)
(4)
(5)
(6)
在运算过程中,
表示为激活函数,
表示t时刻遗忘门的节点操作,
表示输出门t时刻输出,
为权值,
为偏置项,
为时间t的输入向量,
为前一步计算的输出状态,
为最终状态的输出,
为上一时刻的单元状态,
为当前单元状态。
BiLSTM模型在处理文本时可学到大量双向语义数据,可对文本内容进行更好地分类,其结构如图3所示。
如图,BiLSTM由正向LSTM和逆向LSTM构成,
、
和
代表
、i和
时刻的输入信息;正向隐藏层LSTML的输出为
,逆向隐藏层LSTMR的输出为
,concat表示不同隐藏层输出向量的拼接,BiLSTM隐藏层的输出
表示为:
(7)
自注意力机制可以在保留原文特点的基础上突出文章重要特点,把注意力集中到某些对文章比较重要的词语上,注意力机制的计算流程如下:
(8)
(9)
(10)
其中,
为
的自注意力隐藏层表示,
为权重矩阵,
为偏置单元,
为
经过Softmax层后获得的归一化权重。最后将BiLSTM输出值
与权重值
进行点乘并求和,得到最终输出值
。
3.3.2. Layer Normalization
Hinton等 [16] 提出适用于RNN模型的层归一化(Layer Normalization)加快模型学习速度,具体根据以下公式将网络某一层的所有神经元输入进行归一化:
(11)
(12)
(13)
(14)
其中,
、
分别代表各层神经元的均值和方差,H代表网络各层节点个数,
代表第l隐藏层输出,y代表模型标准化值,g和b分别表示向量的缩放和平移。
3.4. CNN通道
3.4.1. CNN + Attention
为了提取更加丰富的局部特征,本文使用多层CNN。该通道输入为经过词嵌入层映射得到向量与经过BiLSTM + Attention通道之后词向量的融合。假设经过concat后的矩阵为S0,模型采用2个并行的CNN通道对S0进行局部特征提取操作。为了进一步提高双通道CNN的特征提取能力,获取文本的多元特征,在2个CNN通道再加入一层卷积对CNN进行优化,加强文本局部特征表达能力,同时引入自注意力机制层与批归一化层进一步加强模型的学习能力。
设输入词向量为
,其中,
,
代表输入文本中第i个词所对应的词向量,n代表选定的词向量维度。将卷积核定义为W,则卷积层的运算过程可以表示为:
(15)
其中,
表示通过卷积计算输出的第i个特征值,
表示非线性激活函数,
表示卷积运算,b为偏置单元。
词向量矩阵S经过卷积运算,得到一个CNN卷积后的输出矩阵
,N为词向量个数。接着将
输入自注意力机制层进行处理,计算过程如下:
(16)
(17)
(18)
3.4.2. Batch Normalization
为增强模型的自适应能力和表达能力,加入Batch Normalization批标准化层 [17] 对通过CNN卷积层和自注意力机制层产生的输出向量加以处理。假定Batch_size为m,Batch Normalization层输入向量为
,则Batch Normalization计算流程如下:
(19)
(20)
(21)
(22)
其中,
、
分别代表神经元各批次的均值和标准差,通过公式(22),当前Batch_size第i个输入节点的值
变为均值为0、方差为1的正态分布
,
为避免除零输入的极小值,
和
为缩放和平移参数。
最后,再将经Batch Normalization后的特征向量进行池化,计算流程如下:
(23)
3.5. Softmax层
由于CNN通道中的池化运算将特征向量进行了降维,使CNN通道与BiLSTM通道输出向量呈现不同维度,因此需要对各通道输出矩阵进行处理,然后将经过concat函数融合后的向量存于output,进行全连接运算。
本文采用Softmax分类器实现output的文本分类,得到各类别输出向量的概率分布,计算过程如下:
(24)
其中,P表示输入向量x分类到类别j的概率,
为模型训练的参数。
3.6. 模型激活函数
本文采用由Diganta [18] 提出的Mish激活函数。传统大多使用Sigmoid、Tanh、Relu激活函数,各函数公式为:
Sigmoid:
(25)
Tanh:
(26)
Relu:
(27)
Mish:
(28)
各激活函数对应的函数图像如图4:
对比Sigmoid、Tanh、Relu激活函数,Mish函数正值能够到达任何高度,从而有更好的梯度流信息,而不像Sigmoid函数无负值流入,Tanh容许进入过大的负值,以及Relu函数的硬零界限,能够更好地保障特征信息的流动。
4. 实验结果与分析
4.1. 实验环境与数据概述
本文的实验环境如表1所示:

Table 1. Setup of experimental environment
表1. 实验环境设置
本文实验选取网络上公开的用于文本分类的四个中文数据集:THUNews新闻数据集 [19]、今日头条新闻数据集、online_shopping_10_cats (简称os10c)数据集和ChnSentiCorp (简称Chn)数据集。
THUNews新闻数据集由清华大学提供并公开,共涵盖经济、地产、股票、教育、科学、社会、政治、运动、游戏、文娱10类资讯。今日头条数据集涵盖15种资讯,实验提取其中8类:科技、娱乐、体育、军事、金融、汽车、文娱、教育。os10c数据集收录了图书、平板、手机、果蔬、洗发水、热水器、蒙牛、服装、电脑、酒店10类评论信息。Chn数据集由哈工大谭松波教授整理并提供,包含酒店、笔记本、书籍三个领域正向、负向2类情感数据。
本文将数据集随机分为训练集、测试集和验证集,数据集概况如表2所示:
4.2. 数据预处理与模型参数设置
本文利用Jieba对输入数据集进行分词处理,利用Word2vec模型中的Skip-Gram方法开展词向量训练,得到的词向量分布式表示维度为:50、100、150、200、300。同时引入数据增强(Data Augmentation)技术,使有限数据集获得更大数据量,改善模型稳健性,增强模型泛化能力。
模型的具体参数设置如表3所示。
4.3. 评价指标
大多数分类模型的评判标准是:准确率(Accuracy)、精确率(Precision)、F1值(F-measure)及召回率(Recall)。相关的混淆矩阵结构图如表4所示。
其中,准确率代表正确计算的样本相对于分类样本的比例,计算公式如下:
(29)
精确率是指预测结果为正例的统计中,被准确预测为正样本的比例,计算公式如下:
(30)
召回率代表正确预测结果的正样本占全样本的实际正样本的比例,计算公式如下:
(31)
F1是精确率与召回率的加权平均数,统计公式如下:
(32)
4.4. 实验结果及分析
首先,本文进行两个实验,一采用Mish激活函数,另一个采用Relu激活函数,对比模型包括:BiLSTM、CNN、BiLSTM_CNN、BiLSTM_Attention、CNN_BiGRU_att [14] 以及SAttBiGRU_MCNN [15]。其对比结果如表5和表6所示:
结合表5和表6,MAC_BiLSTM文本分类模型较其他6种模型,在四个数据集都取得了较好的分类结果。通过表5,本文给出的分类模型在四个数据集上准确率分别达到了88.21%、87.41%、87.12%和89.01%。对比BiLSTM模型,本文模型在四个数据集上准确率分别提升了2.76%、1.61%、2.74%和3.21%。比较CNN模型,本文模型在四个数据集上准确率分别增加了4.33%、2.78%、4.07%和4.39%。对比BiLSTM_CNN模型,本文模型在四个数据集上准确率分别提升了2.02%、1.21%、0.80%和2.99%。另外,
Table 5. Comparison of experimental results with Mish activation function
表5. 加入Mish激活函数实验结果对比
Table 6. Comparison of experimental results with Relu activation function
表6. 加入Relu激活函数实验结果对比
BiLSTM_CNN模型比BiLSTM模型在四个数据集上的准确率分别提高了0.74%、0.40%、1.94%和0.22%,比CNN模型在四个数据集上准确率分别提高了2.31%、1.57%、3.27%和1.40%,表明CNN与BiLSTM结合的网络结构能更有效地提取文本中的关键特征,从而提高文本分类准确率。相比BiLSTM_Attention模型,本文模型在四个数据集上的准确率分别提高了0.94%、1.78%、1.02%和2.79%,并且,通过对比BiLSTM模型和BiLSTM_Attention模型的准确率可发现,自注意力机制的引入使模型的分类性能得到了进一步的改善。将本文所提模型与CNN_BiGRU_att模型和SAttBiGRU_MCNN模型的分类结果进行比较,发现本文模型比CNN_BiGRU_att模型准确率在四个数据集上分别增加了5.00%、2.97%、3.95%和3.31%,较SAttBiGRU_MCNN模型准确率在四个数据集上分别提高了1.51%、1.16%、1.04%和1.85%,表明本文提出的方法能够更充分地发挥出CNN与BiLSTM对文本特征的提取能力,并且本文模型在CNN通道中融合BiLSTM通道的输出,增强了特征的重用,进一步加强了CNN对文本局部特征信息的捕捉能力。同时,在BiLSTM通道和CNN通道中分别引入自注意力机制层和归一化层对通道输出的特征分布进行调整,增强了模型的学习能力,有效地提升了模型分类的准确性。
为探究各模型各评价指标与词向量维度之间的关系,本文进一步比较了各类模型在词向量维数依次为50维、100维、150维、200维和300维下,MAC_BiLSTM分类模型与其他深度学习分类模型词向量维度与准确率之间的关系,所得出的对比实验结果如图5~8所示:
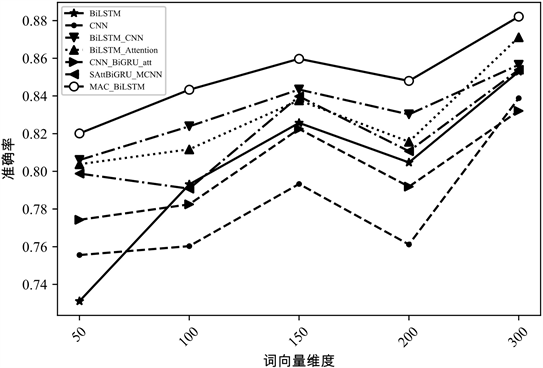
Figure 5. The accuracy comparison of the models under different word vector dimensions in THUC News dataset
图5. THUC News数据集不同词向量维度模型准确率对比

Figure 6. The accuracy comparison of the models under different word vector dimensions in Toutiao dataset
图6. 今日头条数据集不同词向量维度模型准确率对比
根据图像,所有模型的准确率均伴随着词向量维度的上升,总体呈现出向上的趋势,并且各分类模型的分类性能在词向量维度为300维时实现最优。也就是随着词向量维度的增加,向量空间的表达能力增强,模型读取到的文本信息愈加全面、愈加丰富,从而各分类模型的性能均得到了提升。其中,本文模型在各个维度上的分类性能都优于其他主流深度学习模型,更证明了文中给出的MAC_BiLSTM模型在中文文本分类任务中的有效性与准确性。
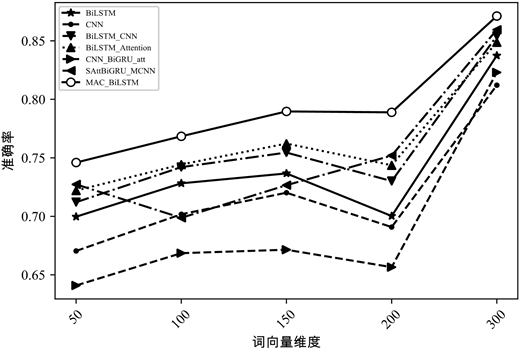
Figure 7. The accuracy comparison of the models under different word vector dimensions in os10c dataset
图7. os10c数据集不同词向量维度模型准确率对比
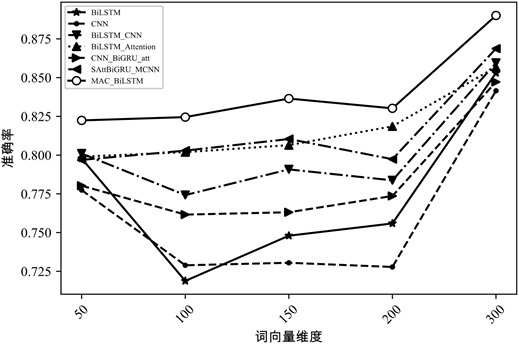
Figure 8. The accuracy comparison of the models under different word vector dimensions in Chn dataset
图8. Chn数据集不同词向量维度模型准确率对比
5. 结束语
本文结合BiLSTM、CNN、自注意力机制以及归一化提出了多通道MAC_BiLSTM文本分类模型并对中文文本进行了分类研究。首先进行分词然后将文本数据增强,接着将文本数据通过BiLSTM对文本序列信息进行捕捉学习,提取文本不同层次的上下文语义信息。然后利用自注意力机制对文本深层次序列信息进行再提取,从而得到更加准确的文本关键语义信息,并将经过BiLSTM通道的信息与最初的词向量信息融合,输入CNN通道从而获得多特征的文本局部语义信息,得到更丰富的文本语义表示。通过将本文给出的文本分类模型,与其他六种模型在各个数据集上进行多维度的对比分析,结果显示本文提供的模型有比较好的分类结果,从而证明本文模型的有效性,为自然语言处理领域提出了新的科研思路。
考虑到文本分类任务中词语的词向量表示对文本模型存在的影响,在接下来的研究中,将着力于在词汇的语义拓展和建模框架、参数等方面加以优化完善,以便于提高模型学习效果的准确率,并降低训练过程的时间成本。
致谢
感谢全国统计科学研究项目对本论文的支持,感谢导师江开忠对本论文的指导,感谢作者杨洋、惠岚昕对本论文的协助与支持,感谢给予引用权文献与数据所有者对本论文的论据支撑。
基金项目
全国统计科学研究项目(2020LY080)。