1. 引言
随着金融市场的不断完善,金融时间序列数据量日趋庞大且波动更为复杂。股票作为一种重要的金融工具,它的变化不仅受投资者关注,也关乎企业甚至国家的经济发展。股票价格受到时间序列的随机性 [1]、宏观政策、企业经济运行状况等诸多因素的影响,影响因素间复杂的非线性动态交互关系使序列存在非线性、非平稳、低信噪比的特点 [2]。近年来,智能金融预测可以极大提高金融风险管理和相关决策分析的效率。在金融预测过程中,一些特征对模型的贡献几乎为零,不仅会限制结果准确性,还会占用机器学习模型更多的训练时间从而导致过拟合。因此,在考虑尽可能多的因素下,对高维数据降维,并进一步预测股票走向,为投资者决策提供数据支持仍然是学术界和金融界具有极大挑战的问题。因此,本文利用多用多步特征选择对影响因子降维,再结合深度学习方法预测股票收盘价。
2. 股票预测模型
本文建立的股票预测模型框架流程图如图1所示。首先,利用Python的Tushare接口爬取股票数据,并使用TA-Lib库计算技术指标。其次,对收集到的数据进行预处理。然后,用多步特征选择筛选变量产生特征子集作为预测模型的输入变量。再将筛选出的最优特征变量导入遗传算法优化的LSTM神经网络,对个股的收盘价进行预测,并计算预测误差。最后对比所提模型与多种方法的预测误差。
2.1. 多步特征选择
市场条件、公司自身、行业政策等因素会影响股票价格。对于股票分析一般是股票基本面和技术分析两部分。技术分析是通过编译一系列技术指标来完成的。本文选取我国各行业企业股票走势作为研究对象。以收盘价为输出变量,输入变量包括K线基本指标、成交量指标、价格指标、动量指标和波动率指标 [3],如表1所示。
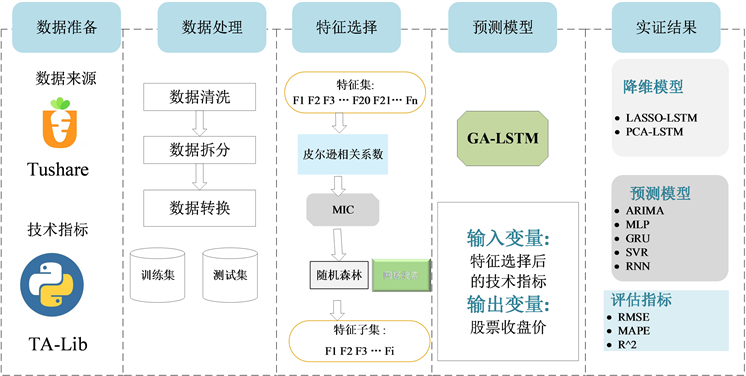
Figure 1. Proposed model procedure for stock prediction
图1. 所提模型股票预测流程图

Table 1. Technical indicators of stocks
表1. 股票技术指标
由于输入特征较多,而各个变量间存在信息冗余,从而影响LSTM的预测准确率及收敛速度。因此首先计算指标与收盘价的皮尔逊相关系数,保留相关系数较高的前40个指标。由于皮尔逊相关系数检验的是线性相关性,而指标对于收盘价的影响大多都是非线性的。Reshaef等人 [4] 在2011年提出的MIC可以捕捉每个特征与目标变量之间的任意关系,比如线性和非线性关系、函数或非函数关系等。两变量的MIC越大,则相关性越强,当两个变量具有严格确定的关系即
时,MIC取1,当两变量独立时,MIC为0。计算剩余的40个指标与收盘价的最大互信息系数,得到MIC前20的指标如下表2:
初步特征筛选后,通过随机森林算法构建股票收盘价预测模型,用于确定辅助变量最优特征子集。随机森林最早由Breiman提出 [5],用它计算特征重要性的思想是取每个特征在随机森林中的每颗树上做的平均贡献,最后比较特征的贡献大小,贡献通常用袋外数据错误率来衡量 [6],其基本步骤如下:
1) 从N个原始训练集中用Bootstrap有放回抽n个样本,进行k次采样,生成k个训练子集
。
2) 从原始特征中随机抽取m个特征,对
进行训练,将m个特征作最优切分得到K棵决策树预测结果。
3) 计算特征重要性并按降序排序:重复抽样得到的一组数据来训练决策树,剩余数据计算第i棵决策树袋外错误样本数
。在保持其他特征不变的同时,对OOB中的
加入噪声干扰得到
, 再次计算袋外数据误差
。重复上述步骤,得到
与
。计算
所有决策树特征
置换前后OOB分类误差率的平均变化量:
。
4) 根据重要性剔除一定数量特征,剩余作为新的特征集,用此特征集重复上述过程,得到对应的特征集和袋外误差,直到剩下m个特征,选择误差最低的特征集作为LSTM的输入变量。
2.2. 股票走势预测
将多步特征选择的最优特征集作为股票预测模型的输入,由于股票时间序列前面的价格会影响后期价格走势,因此选择具有记忆性的LSTM神经网络,它是Hochreiter在1997年对循环神经网络的改良 [7],通过反向传播算法进行训练,并使用记忆单元来解决梯度消失的问题。其神经元结构 [8] 如图2。
细胞状态
用于保存当前信息,并在下一时刻传递给LSTM,通过门控单元传递信息。这些门决定了对过去和新信息的记忆遗忘程度,使LSTM成为一个长期依赖函数。遗忘门
控制上一时刻传递到当前时刻 中的信息,输出为
(1)
输入门
控制当前输入新信息
中有多少可以加入到细胞状态中。Tanh层用来产生当前的新信息,sigmoid层用来控制有多少新信息可以传递给细胞状态。输出为
(2)
(3)
更新后的细胞状态来自上一时刻旧的细胞状态信息
和当前输入新信息 :
(4)
输出门
:更新细胞状态后,输出隐藏状态
,用sigmoid层来控制细胞状态信息,将细胞状态缩放至(−1, 1)作为隐藏状态的输出
(5)
(6)
为了使预测结果更加准确,采用遗传算法优化LSTM参数 [9]。遗传算法是元启发式随机优化方法,基本思想是模拟生态的进化过程,通过交叉、变异等手段,有效地获得网络参数的近似全局最优解 [10]。优化的网络参数有:LSTM的层数,隐藏层神经元个数,dense层层数。其初始参数设置为:交叉概率0.5,变异概率0.01,种群大小20,世代大小30,每条染色体长度为8,染色体个数为2。适应度为均方误差的倒数:
(7)
MSE表达实际值与期望值之间的误差,均方误差倒数越大表明网络性能越好,剔除低适应度低的个体,繁殖高适应度的个体。算法结束后,适应度值最大为最优解,即LSTM的最优参数。遗传算法优化LSTM结构如图3。
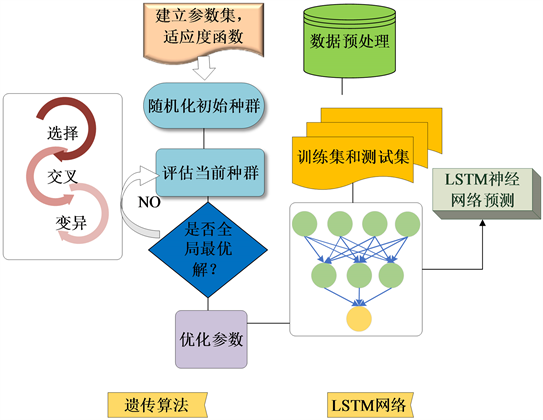
Figure 3. The flow chart of GA-LSTM
图3. 混合GA-LSTM预测模型的框架
3. 数据与评价指标
3.1. 数据选择与处理
本文采集是不同行业代表企业十年的日数据,所有股票数据来自开源python金融数据接口Tushare包,主要实现对股票等金融数据采集、清洗、处理和储存。股票的所有技术指标都来自一个Python金融量化的高级库,名为TA-Lib的技术分析库。对收集到的数据作如下处理:
1) 数据清洗与拆分
本次研究中使用的数据是通过API和网站收集的,所以有些值缺失或没有意义。因此,在适当的时候,将计算出的统计平均值作为观测值替换缺失的数据,为保证数据真实性,不对周末数据作缺失处理。在训练过程中,将数据的70%数据作为训练集来估计模型,剩下的30%作为测试集来测试最优模型的性能。
2) 数据转换
数据归一化是数据预处理的重要步骤。归一化的目的将数据压缩到(0, 1)范围内。为了更好的说明问题,我们用式8对数据进行归一化,目的是统一量纲,方便计算,减少梯度和加速收敛,其中Xi代表第i天的收盘价,Xmax和Xmin代表Xi的最大值和最小值。
(8)
在建立LSTM模型的过程中,归一化数据需要进行滑动窗口处理,每组X对应一个Y,假设原始时间序列
的宽度时间窗l,预测周期为pr,数据会生成nl-pr + 1个时间窗序列,分别为
。在本文中,最合适的时间窗口宽度初始设置为16,如图4所示,每组监督数据包括一组
和一组
,每组
包括一个从i到
共16个指标数据,每个对应的y是
个收盘价。构建的数据集作为LSTM模型的输入序列进行训练和验证。
3.2. 预测结果评估
为了有效评价所提模型,用四个指标对预测结果评估。均方根误差:作为股价预测模型的评价标准,同时作为训练模型时的损失函数,RMSE的值越小,模型的拟合效果越好。平均绝对误差百分比:MAPE越低,模型的预测结果越可靠。决定系数:R2 越接近于1,模型拟合效果越好,R2越接近于0,模型拟合效果越差,当R2为1时,样本数据完全拟合。
是序列实际值,
是其预测值,
是原始序列平均值,指标计算如下:
(9)
(10)
(11)
4. 实验设计与结果分析
本节主要分为三个部分。第一部分以中国银行股票数据为例,展示所提模型预测结果。第二部分将所提出的多步特征选择方法与其他降维方法筛选出的变量作为输入变量,再导入LSTM网络进行预测方法进行对比,第三部分利用ARIMA、SVR、RNN、GRU、MLP和LSTM四个模型对股票收盘价进行预测。第四部分选择中国股市不同行业的股票数据运进行预测从而验证此模型的普适性。结果表明,使用多步特征选择降维后的LSTM网络具有更好的预测效果。
4.1. 特征选择结果
通过皮尔逊相关系数和互信息系数初步筛选特征后用随机森林计算特征重要性。随机森林参数用二次划分贪心选择算法优化。首先,经一次划分随机搜索算法,计算在不同的决策树个数进和最大深度下的MSE,MAE。确定决策树个数在300~400,最大深度为10~120。图5中标记的平均测试分数的最高点也是平均绝对误差最低值MAE = 0.0066,对应的每个划分最少的样本数为7,叶子节点最少的样本数为6。同理缩小参数取值范围进行二次网格搜索,计算每个网格的均方根误差,得到最优决策树个数为400,决策树最大深度和单棵决策树最大特征数分别为140和34。
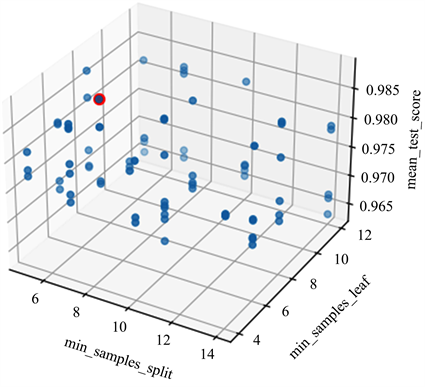
Figure 5. The scope of min_samples_split, min_samples_leaf value
图5. 每个划分最少的样本数、叶子节点最少的样本数取值
使用优化后的随机森林计算特征的重要性如图6所示。确定LSTM模型的最终输入变量为close_2_sma、high、low和SMA。
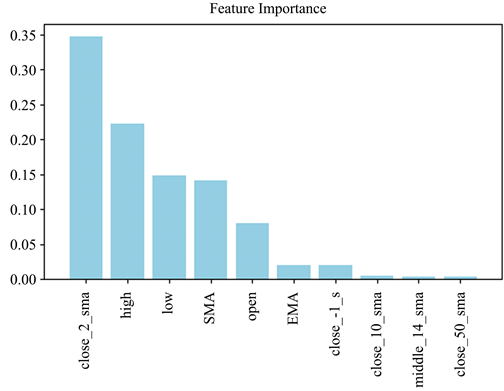
Figure 6. The importance of various features
图6. RF特征选择特征重要性
4.2. GA-LSTM预测
以中国银行股票的收盘价预测为例,输入变量包括了上一步特征选择得到的四个重要变量。利用遗传算法优化LSTM模型得到模型参数为:LSTM的层数为3,隐藏层的神经元个数为138,dense层层数为1,神经元个数为43。对于其他参数:早停法获得迭代次数为25,mini-batch得到一次训练选择样本数为16。使用Adam算法作为模型权重优化器,学习率为0.0001。用上述参数训练模型得到最终拟合结果如图7。
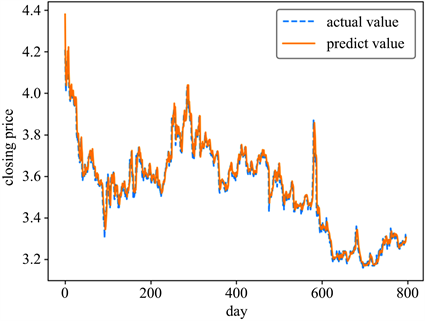
Figure 7. Bank of China stock forecast results
图7. 中国银行股票预测结果
由图7可以看出两条曲线几乎重合,初步认为此模型的预测精度较高。图8(a)损失函数图看出,训练集和测试集的损失函数都已经收敛且很接近,说明模型能够很好地拟合训练样本和测试样本的分布,泛化能力强。从图8(b)预测的残差图来看,残差值绝对值分布在0.1以内,个别位置有较大波动,误差较小且较稳定,进一步说明模型的优越性。
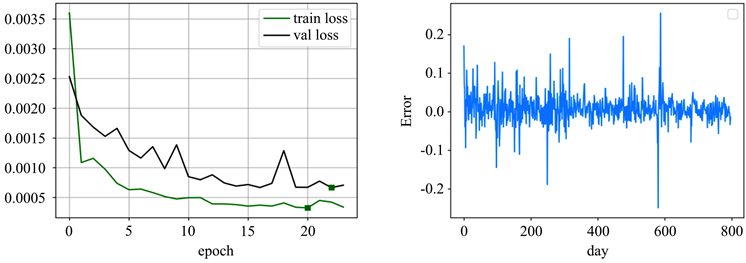 (a) (b)
(a) (b)
Figure 8. Loss function graph and error analysis
图8. 损失函数和误差分析
4.3. 降维模型对比
将多步特征选择与主成分、LASSO降维后的输入变量导入LSTM神经网络,使用共同的模型参数,预测结果及部分序列放大图的预测值和实际值如图9所示,可以看出与真实序列相比,所提出的模型,预测曲线(黑色)与实际历史曲线(红色)上下交织,没有明显的相位差,相较于其他曲线与实际值更加接近。表明多步特征选择降维再进行预测有更好的性能。
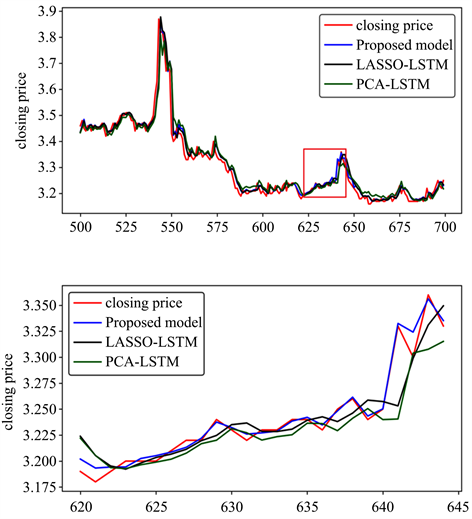
Figure 9. Comparison of dimensionality reduction model
图9. 降维模型预测对比图
为了定量评估预测精度,列出了这些模型的三个评估指标见表3。可以发现,所提出的多步特征选择相较于其他模型RMSE、MAPE都较小,R2说明拟合优度较好,其次是LASSO降维的方法。
Table 3. Comparison of dimensionality reduction model
表3. 中国银行降维模型预测对比
4.4. 预测模型对比
将本文所提的GA-LSTM模型与自回归移动平均(ARIMR)模型、多层感知机(MLP)模型、循环神经网络(RNN)模型、支持向量回归(SVR)模型和门控单元网络(GRU)的评测结果相对比,分析了所提模型的性能。模型的输入变量都为特征选择预处理后的变量。预测对比图及细节放大图如图10所示。与真实序列相比,各种深度学习模型的预测的结果表现为右移,说明预测较实际有一定时间的滞后性,其中最为明显的是线性模型ARIMA。对于所提出的模型,预测曲线(黑色)与实际历史曲线(红色)上下交织,没有明显的相位差,表明预测效果较好。
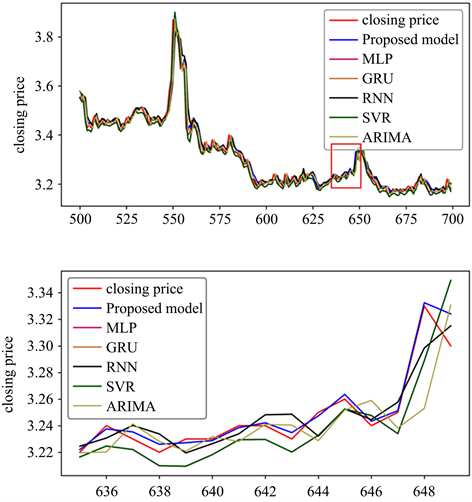
Figure 10. Comparison of predictions of parallel models
图10. 并行模型预测对比图
为了定量评估预测精度,表4列出了这些模型的三个性能标准。可以发现,传统模型的RNN和ARIMR的预测偏差高于其他模型,而基于SVR和GRU的预测偏差高于所提模型。该模型MAPE、RMSE和R2分别为0.34、0.0145和0.9986。所提模型预测效果优于ARIMA模型和RNN模型,相较于深度学习模型中的MLP、SVR、GRU预测效果有所提高。
4.5. 模型普适性检验
为了测试交易算法在中国股市中的表现,我们选择中国十大不同行业具有代表性公司的股票价格进行了实验。这些股票具有很强的流动性,能反映该行业的发展方向和整体走向,为交易策略提供良好的目标。它们代表了中国股市的发展方向,对投资者具有吸引力,预测结果如表5。可以看出,各行业数据计算预测误差小,拟合优度高。因此,该模型应用于不同的数据时,可以取得更好的预测结果。
Table 4. Comparison of parallel model
表4. 中国银行并行模型预测对比
Table 5. Comparison of rolling forecast results of stock prices
表5. 股票价格滚动预测结果对比
5. 结语
本文针对非平稳、噪声较大的金融时间序列数据,提出了一种混合机器学习多步特征选择的GA-LSTM框架,用于多指标下股票收盘价的预测,以提高预测精度。实验选取中国股市各行业数据,通过数据收集与处理、特征选择、网络模型参数优化、网络模型建立和结果评价分析五个过程验证所提模型的预测效果。结果表明,与PCA-LSTM、LASSO-LSTM降维方法相比,本文通过选取大量技术指标,首先利用多步特征选择大大减少模型的输入维数,计算特征重要性,提高了预测准确率;与机器学习模型MLP、ARIMA、RNN、SVR、GRU相比,提高了预测精度。未来工作可以尝试以下两个方面,一是选取更多种类的算法探讨预测模型的性能以及挖掘重要性预测指标;二是将模型应用到高频数据或不同周期的数据中。