1. 引言
电力系统的稳定运行关系到我国的国计民生。电力线路在野外时刻面临着遭受外力破坏的风险,为了保证高压输电系统的安全稳定运行,对高压输电系统进行定期监测是必不可少的 [1]。电塔作为输电走廊中的关键设施,在保障电力系统的安全运行中起着至关重要的作用。输电杆塔的三维重建有助于电力系统管理、故障预防排查以及输电走廊的三维可视化,同时杆塔重建也是“智能电网”构建的重要一环 [2]。
作为输电杆塔三维重建重要的基础工作,如何实现精确快速的输电杆塔塔型识别也是学者们关注的问题。对此,郑晓光等使用人机交互的方式,实现了数据的可视化和语义的判读,从而实现人工塔型识别。H Wang [3] 等通过支持向量机(SVM)算法确定了输电杆塔的塔型识别。Zhou等 [4] 通过将杆塔点云和粗糙模型放大到相同的尺度并转换成二值图像,利用形状上下文算法来识别杆塔的类型。
近年来随着卷积网络的发展,其优秀的特征提取能力,更高的准确率,更快的运算速度等特点使得基于深度学习的检测方法得到广泛研究。目前,基于深度学习的目标检测算法主要分为两类:二阶段(Twostage)和一阶段(One stage)目标区域提取算法。常见two stage算法有:R-CNN系列 [5] [6] [7],SPP-Net [8] 和R-FCN [9] 等。常见的one stage目标检测算法有:Over Feat [10],YOLO系列 [11] [12] [13],SSD系列 [14] 等算法。深度卷积神经网络也被广泛应用在电力领域 [15] [16] [17],深度学习技术在杆塔自动化识别的工作中具有很大的潜力。
本文提出了一种基于PCA算法 [18] [19] [20] [21] [22] 和YOLOv5的杆塔塔型识别模型。我们的模型可以高效率地从无人机巡检所产生的数据中辨别出输电杆塔的塔型类别,从而为后续建模工作提供支持。本文使用数据主要为电塔点云数据,该方法也可推广于由倾斜影像重建的三维点云数据 [23]。
本文主要贡献:
1) 利用PCA算法,将杆塔点云沿着主方向投影到二维平面作为模型输入。
2) 利用YOLOv5网络实现杆塔的塔形识别,既能保证识别的准确度与可靠性,又能加快检测速度,实现实时目标检测。
2. 方法
本文基于PCA主成分分析算法实现了杆塔点云的主方向投影,并将投影后的二维影像作为输出,后续采用基于深度学习的方法实现了杆塔类型的识别。
杆塔的总体结构是对称的,但是直接对激光雷达采集的杆塔点云进行塔型识别等处理较为复杂,所以我们首先将点云沿主方向投影到二维空间,然后对二维投影图进行处理,进而实现了杆塔的精确类型识别。基于LiDAR点云的塔型识别流程图如图1所示。
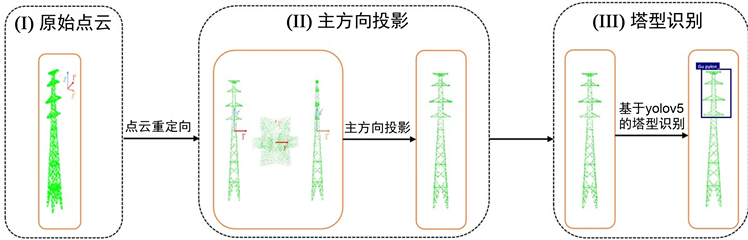
Figure 1. Tower type recognition flow chart based on LiDAR point cloud
图1. 基于LiDAR点云的塔型识别流程图
2.1. 基于PCA的主方向投影
点云较于二维数据,优势明显,但是因为点云数据的稀疏性、离散化、无序性等特点,直接以三维点云数据作为输入的网络模型,往往存在着不同的缺陷,例如体素化模型存在过大的运算量与内存占用,甚至由于稀疏性导致过多的空voxels出现,导致计算资源的浪费。同时庞大的点云数据规模更是严重制约了算法的实时性。因此本文利用PCA算法,通过主方向投影杆塔点云投影到二维空间作为模型输入。
PCA算法是一种常用于数据降维和特征提取的数据分析方法。该算法的主要思想是:将高维向量从原始空间投影到一个低维的向量空间,这种转换可以通过一个特殊的特征向量矩阵实现。这种转换也能实现由转换结果重构原始高维向量。该算法的步骤如下:
1) 设有m条n维数据,将这些数据用向量形式表示,并按列构成矩阵X;
2) 将每一行数据进行零均值化;
3) 求得协方差矩阵
;
4) 求出C的特征值以及该特征值所对应的特征向量;
5) 将特征向量规范化;
6) 将求出的特征值按从大到小的顺序排列,然后依照特征值的排列顺序将特征向量按行组合成矩阵,并将矩阵的前k行提取出来,作为矩阵P;
7)
即为将原始数据维度降低到k维之后的数据。
为了充分利用杆塔结构的对称性,以便后续塔型的识别,本文将杆塔的上部扫描点投影到XY平面上进行均匀采样;然后利用PCA [24] [25] 算法计算采样点云的特征值和特征向量,将最小特征值对应的特征向量
的方向指定为X'轴;最后,旋转角度和点坐标
由式(2.1)计算。
(2.1)
基于PCA的主方向投影,实现了输电杆塔点云主方向的提取以及主方向的投影,重定向后的杆塔点云图与主方向投影图如图2所示。
 (a)
(a) 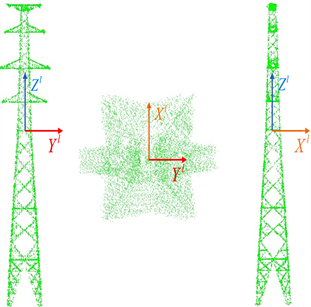 (b)
(b)  (c)
(c)
Figure 2. Extraction of point clouds’ main direction and projection. (a) Original point cloud; (b) Redirected point cloud; (c) Results of projection in the principal direction
图2. 杆塔主方向提取并投影。(a) 原始点云图;(b) 重定向点云图;(c) 主方向投影图
2.2. 基于YOLOv5的塔型识别
YOLO是由Redmon和Divvala提出的一种深度学习目标检测算法,属于one-stage目标检测算法,能实现端到端的识别,既能保证识别的准确度与可靠性,又能加快检测速度,实现实时目标检测 [26]。YOLOv5算法共有YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x,共4种网络结构,这四种网络结构在宽度和深度上不同,其中宽度越大的网络其卷积核数量越多,网络中的卷积操作更多,也就意味着网络所需要的计算量越大,但同时,其特征提取能力也就越强,目标检测速度越快,检测准确性越高 [27]。YOLOv5的网络结构如图3所示,结构分为输入端、Backbone (主干网络)、Neck网络和Prediction (输出端)四个部分 [28]。
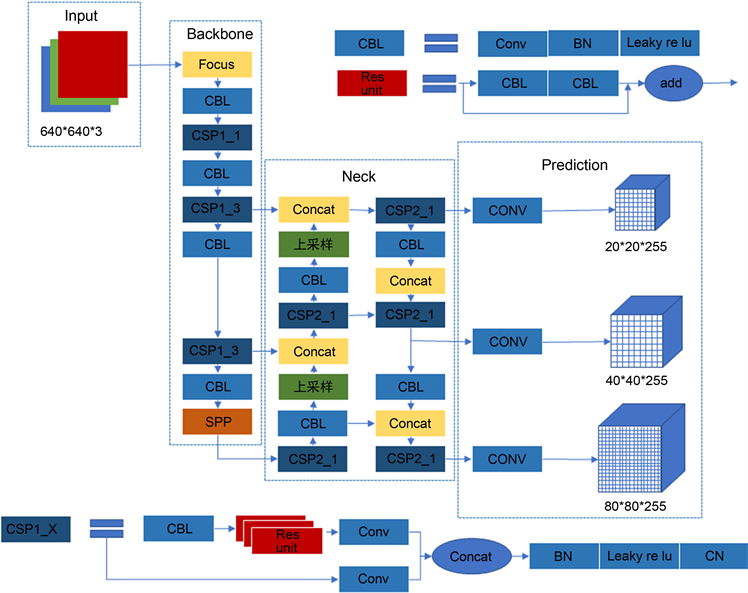
Figure 3. Network structure diagram of YOLOv5
图3. YOLOv5的网络结构图
1) 输入端:输入端对于不同尺寸大小的输入图片首先将其统一调整为640*640,并采用Mosaic数据增强、自适应锚框计算以及图像自适应缩放对输入图像完成预处理 [29]。
2) Backbone网络:Backbone部分由Focus下采样、CBL、改进的CSP以及SPP池化金字塔模块组成,用于提取图片的特征信息,可生成输入图像5次下采样的特征图 [30]。
3) Neck网络:Neck部分采用特征金字塔网络(FPN) [31] [32] 和金字塔注意力网络(PAN) [33] [34] 的组合结构。通过自顶而下的FPN层,采用上采样操作,将传递的上层特征信息进行融合并传递给网络中的下层,传达强语义特征。而通过自底而上的包含有两个PAN结构的特征金字塔,通过下采样操作,将低层的特征信息和高层特征进行融合,输出预测的特征图,传达强定位特征,加强了网络特征提取能力。
4) 输出端:输出端采用GIOU_Loss [35] [36] 损失函数,减少了单纯IOU损失的不足。传统的IOU及其边框损失表达式如式2.2.1与式2.2.2所示,GIOU及其边框损失表达式如式2.2.3与式2.2.4所示。GIOU与IOU一样具有尺度不变性,即当目标边框等比例放大缩小时,损失能仍然保持相同的量级,不需要对不同大小的边框作出不同的处理。但是,相比于IOU,GIOU加入了对非交叉面积比例的考虑,非交叉面积定义为预测框与真实框的最小外接矩形集合C和预测框与真实框并集的差。且对比与IOU损失,GIOU具有偏离趋势度量的能力。对于传统的IOU损失,当真实边框与预测边框不相交时,IOU计算值始终为0 [37],对于不同远近距离的边框其损失计算值都相同。但是GIOU损失函数随着真实边框与预测边框距离的不断增加,其计算值会表现出越接近于−1,计算出损失就会越大,因此,即使真实边框与预测边框不相交,也能根据GIOU损失计算值判断出两者的偏离距离远近。
(2.2.1)
(2.2.2)
(2.2.3)
(2.2.4)
其中,集合A、B分别为真实边框与预测边框;集合C为真实边框与预测边框的最小包围框。
YOLOv5方法中的塔型检测识别过程如图4所示。其主要实现步骤为:
1) 图像分割:YOLOv5将输入图像分割为N × N个网格,每个网格负责预测落在该网格内的物体;
2) 边界框预测和分类:对每个网格预测若干个边框,包括每个边框是目标的置信度及每个边框区域在多个类别上的概率;
3) 提取网格特征:对图像完成卷积运算操作,获得特征图;提取特征图上每个边框内的特征形成高维特征向量;
4) 图像中目标的识别分类:每个网格预测多个边框,根据计算得到分类误差、置信度以及类别概率等判别塔型。
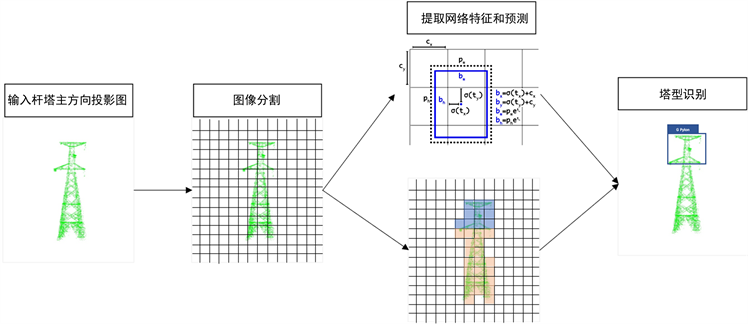
Figure 4. Tower type identification process of YOLOv5
图4. YOLOv5塔型识别过程
3. 实验
3.1. 数据集
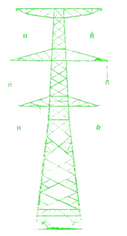
本实验所使用的数据主要为激光雷达采集的杆塔点云数据,均由无人机巡检系统所采集。本实验所识别的杆塔类型主要有鼓型、V字型、酒杯型、干字型,共计2736张杆塔点云。其形状如图5所示:
 (a)
(a)  (b)
(b) 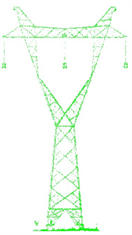 (c)
(c)  (d)
(d)
Figure 5. (a) Gu pylon; (b) V pylon; (c) B pylon; (d) G pylon
图5. (a) 鼓型;(b) V字型;(c) 酒杯型;(d) 干字型
对数据集进行分析得到可视化结果如图6所示。经分析可看出Wpylon,Vpylon,Tpylon三种塔型在杆塔数据集中分布占比较少,酒杯塔占绝大多数,反映了杆塔数据集的特征是平坦地区以酒杯塔为代表的直线塔型居多,从label大小分布可看出其主要分布在0.5附近可以看出数据集的特征分布较为集中,保证了目标检测的准确性。

Figure 6. Number, size and center point distribution of labels
图6. 标签数量、大小及中心点分布
3.2. 模型训练与测试
3.2.1. 评价指标
本文算法性能的指标主要包括准确率(Accuracy)、精确率(Precision, P)、召回率(Recall, R)、平均精度均值(mean Average Precision, mAP)、PR曲线等。其中精确率P定义为正确分类个数与所有识别出来的个数之比。召回率R定义为已经识别个数与应该识别个数之比;置信度为0.5时的平均准确率MAP@0.5定义为在超过0.5时就被认定为某类物体的前提下的平均准确率。其中准确率,精确率与召回率公式如(3.1.1),(3.1.2)与(3.1.3)所示:
(3.1.1)
(3.1.2)
(3.1.3)
3.2.2. 配置参数
本文实验的软硬件平台如表1所示,训练集和测试集分别包含了2456和250张杆塔点云重定向后的主方向投影图。

Table 1. The hardware and software platform of the experiment
表1. 实验的软硬件平台配置参数
3.2.3. 模型训练
在训练过程中,我们将epochs设定为300次,batch size设定为32,img-size设置为[640 640],cfg设置为yolov5s.pt。随着训练轮次的增加,对检测精确度进行分析,可以看出当训练次数达到200轮左右时,检测精确度不再有显著提升。训练指标可视化图像如图7所示:
3.3. 实验结果
根据训练过程生成的模型,得到如下图8所示的PR曲线值:
从PR曲线图可以看出在召回率低于0.6的情况下,除了steel pipe pylon外其他杆塔的precision都能够保持一个较高的值,这符合了steelpipepylon形态特性与其他杆塔差距较大的特点。所有类型杆塔点云识别的平均精确度map@0.5为0.867,这一准确率基本满足目标检测的要求。利用已训练模型对电力杆塔目标进行检测,结果如图9所示:
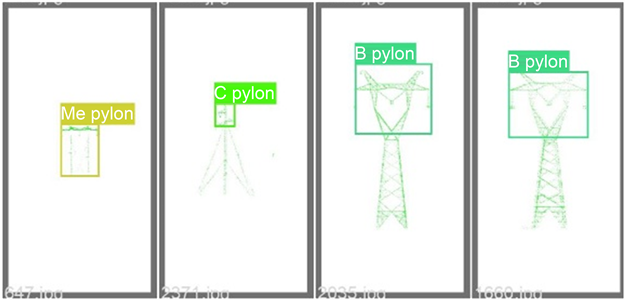
Figure 9. Power tower type identification and detection result diagram
图9. 电力杆塔类型识别检测结果图
本文还通过进一步计算召回率、精确率、平均准确率等指标对检测结果进行定量评价。各类评价指标的计算结果数据如表2:
Table 2. The calculated data of each index in the experimental results
表2. 实验结果中各指标的计算结果数据
4. 结语
本文通过对现有主流杆塔识别检测方法的综合分析,提出了基于PCA算法获取杆塔点云主方向投影,结合YOLOv5深度学习模型,提出了一种准确高效地识别输电杆塔类型的方法。由于采用比杆塔点云更易于检测的主方向投影图作为数据集,本训练模型一定程度上改善了目标检测的准确率并增加了新的类别。不足的是由于杆塔数据集类型比例不平衡,部分塔型数据较少造成对某些类的识别准确率较低,因此在后续工作中会做进一步提升。
基金项目
1) 武汉大学国家大学生创新创业训练计划项目,项目编号:202110486108;
2) 武汉大学知卓时空智能研究基金资助。
NOTES
*共同第一作者。