1. 引言
图像分类问题是目前机器视觉中一大重要的问题,随着深度学习的发展,传统图像处理方法渐渐被摒弃,越来越多的研究者们使用深度学习的方式进行特征描述。在现阶段主要使用卷积神经网络的方式进行识别分类,通过架设不同结构的网络模型实现对现有图片进行分类(预测)。神经网络的出现成为图片分类的一大助力 [1]。在实际应用中,想要取得百分之百的精确准确率是不可能的,我们要尽所能地提高识别的准确率,提高泛化性能。本论文尝试着将经典卷积神经网络模块化,这样使得其易于组合。开发者可以任意组合目前现有的卷积神经网络模块,探索更高的识别准确率。而且,当新的神经网络模块被科研人员研发出来后(如Res2Net),也可以模块化串联到现有神经网络中进行组合。
2. 经典卷积神经网络的模块化
2.1. 研究思路
卷积神经网络对图像进行分类是我们常研究的方向。不同架构的神经网络模型拥有不同准确率以及泛化性能。我们分析了基本的模块化后的经典卷积神经网络,此时,我们可以将这些模块进行自由组合,生成新的卷积神经网络,探索新的网络架构模式。整体分类步骤如下图1所示:
2.2. 卷积–池化层
卷积层 [2] 和池化层 [3] 是卷积神经网络的核心构建块,也是主要的计算发生的地方。它由输入数据、过滤器和特征图组成。有一个特征检测器(也称为卷积核),它将在图像的感受野上移动,检查特征是否存在。整个这个过程称为卷积。池化操作在整个输入上扫描一个过滤器,但不同的是这个过滤器没有任何权重。相反,内核将聚合函数应用于感受野内的值,填充输出数组。可以减少参数或权重的数量。
2.3. ResNetBlock
随着神经网络的深度的不断堆积,我们发现随着深度的堆积,神经网络会有“退化”的现象出现。56层网络的错误率会大于20层的错误率,在深度传播时,后面的特征过于抽象,会丢失原本的特征。于是ResNet [4] 设计了跳连结构,用前面的特征数值加到经过卷积核后的矩阵上。这样基本的操作有效地保留了原有特征。如图2所示,我们在ResNet网络的基础之上,提取出ResNetBlock结构,并且对基本的ResNetBlock进行修改。
2.4. InceptionNetBlock
InceptionNet [5] 系列是Google公司开发的卷积神经网络,InceptionNet以Inception结构块为基本单元。后期的V2,V3,V4也是通过改变Inception结构快而改变网络基本结构的。通过并联模式,减少了输入量和计算量。Inception结构块可以有多种变体模式,我们可以给出多种InceptionBlock结构。InceptionBlock之间可以堆叠使用,添加了1*1的卷积,降低了输入通道。与较浅和较窄的网络结构相比,该方法的优点在于计算量适度增加的情况下显著提高网络效果。本文使用的InceptionBlock如下图3所示。
3. 基于组合ResNet和InceptionNet的神经网络分类
通过上文的介绍,我们可以将这几种卷积网络模块化,当有新的深度神经网络架构时,也可以加入到此类之中。借助以上的Block模块,接下来我们可以设计出一个模块化拼接后的卷积神经网络。我们的卷积神经网络结构后文表所示。
3.1. 网络结构
本节简述一下新组合的卷积神经网络的架构,该网络架构一共具有18层,其中前8层是正常卷积,前5层属于正常卷积,在第6层的卷积操作中加入了最大池化的操作以及dropout进行随机丢弃。第7层中使用Batch Normalizatio对数据进行归一化,使得数据降低过拟合程度,输出了7*7*128大小的数据。数据在经过前8层的卷积操作后,进入InceptionBlock模块,分4条通道进入网络分别进行卷积操作。接下来我们可以设计出一个模块化拼接后的卷积神经网络,输出4*4*512大小的结果,然后进入两个ResnetBlock模块,每个模块是4层,连接到残差网络,可以进一步削减过拟合的问题。随后使用GlobalAveragePooling将最后一层的特征图进行整张图的一个均值池化,同时丢弃0.2的数据防止过拟合,最后拉直层使用L2正则化以及Softmax激活,生成整个共计18层的模型结构。这样的结构既存在InceptionBlock的特点,还具有Resnet的跳连结构的特征,理论上可以比较好地识别图像进行分类。在后文一律将新构造的卷积神经网络命名为NewNet,如图4所示。

Figure 4. New network data flow diagram
图4. 新网络的数据流图
3.2. 网络参数
借助以上的Block模块,接下来我们可以设计出一个模块化拼接后的卷积神经网络。我们的卷积神经网络结构如表1所示。

Table 1. Combining parameter data for convolutional neural networks
表1. 组合卷积神经网络的参数数据
4. 模型对比与结果分析
4.1. 硬件环境的使用
Tensorflow [6] 支持C,C++等多种开发语言。Python语言也是支持的语言之一,我们使用Anaconda创建虚拟环境变量,使用TensorFlow2.1.0版本使用CUD11.4以及CUDNN加速构建识别模型。使用操作系统Windows 10家庭中文版64位操作系统。处理器使用Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz,显卡使用英伟达GeForce RTX3090。运行内存为24 GB。
4.2. 数据集的使用
实验数据使用三种数据集,分别是Cifar10 [7],Cifar100 [8],以及Fashion [9] 数据集。众所周知,CNN网络模型越深,需要的数据也就越多,相对泛化性能就会越好。我们采用了一定的数据扩增技术,使用了翻转,旋转的方式使得数据扩大,尽量增强泛化性能。
4.3. 实验结果分析
4.3.1
. 优化器的比较
选择一个好的优化器是比较困难的,我们在新算法NewNet中,使用不同的数据数据集,不同的优化器,在不同的epoch下比较各种参数。SGD [10],Adagrad [11],Adam [12],RMSProp [13] 是主流的四种基本优化方法。下图是不同数据集不同优化器下损失函数的比较。
如图所示,在使用三种数据集的前提下,上图展示了在三种不同的优化器SGD、RMSprop,Adagrad和Adam下的损失函数下降情况。如图5,图6,图7所示,综合三种数据集的表现后可知,Adam优化器是最适合使用的加速器。
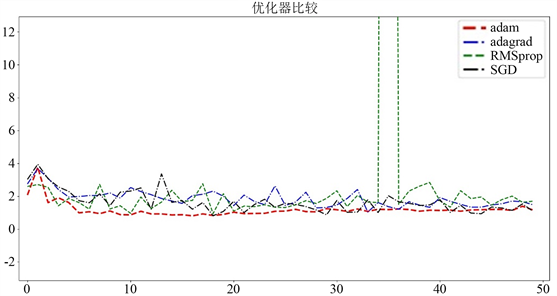
Figure 5. Categories of the local area Cifar10 dataset
图5. 局部区域Cifar10数据集的类别
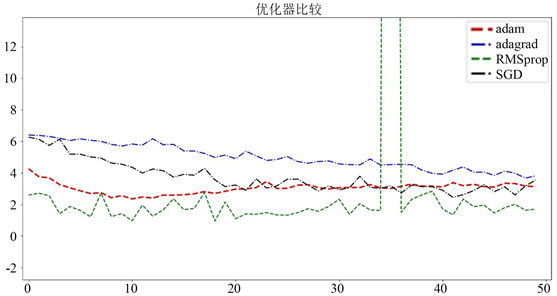
Figure 6. Categories of the local area Cifar100 dataset
图6. 局部区域Cifar100数据集的类别
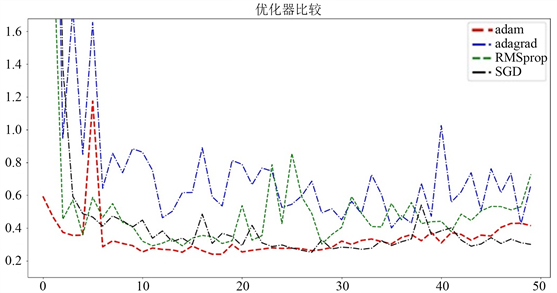
Figure 7. Categories of the local area Fashion dataset
图7. 局部区域Fashion数据集的类别
4.3.2
. 准确率比较
为了评估算法的性能优劣,准确率是一个非常重要的指标 [14]。目前新建立的网络在不同程度上都有略微的过拟合现象,所以存在一些震荡的现象。我们可以用新的网络与其他网络的准确率进行比较,使用Python语言画图进行对比,如图8、图9、图10所示,将新架构网络与四种经典卷积神经网络(VGGNET [15], AlexNet [16], LeNet [17], inceptionNet, ResNet)的准确率进行对比的图像。

Figure 8. Accuracy analysis of Cifar10
图8. Cifar10的准确率分析
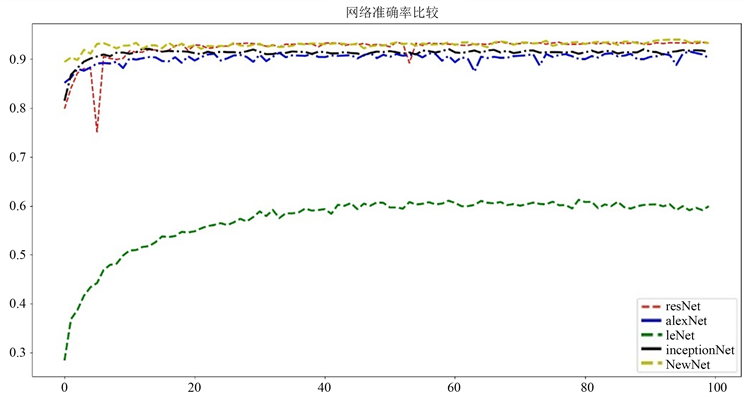
Figure 9. Accuracy analysis of Fashion
图9. Fashion的准确率分析

Figure 10. Categories of local regions Cifar100 datasets
图10. 局部区域Cifar100数据集的类别
可见,该网络在三个数据集上优于其它各网络模型,这是由于Cifar100数据集的种类较多,从准确率上来看NewNet网络的优势非常明显,明显高于ResNet以及其他网络,新网络在Cifar10以及Fashion数据集上的表现也略强于其他网络。综上所述,NewNet的网络,和ResNet网络相比,NewNet结构非常具有优势不仅具有跳连结构可以非常好的解决过拟合问题,也可以多通道地去对图片进行处理。
4.3.3
. 损失函数的比较
本节中我们比较算法的损失函数,在图像分类问题中,我们一般使用的是交叉熵损失函数,交叉熵 [18] 是用来评估当前训练得到的概率分布与真实分布的差异情况。它刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。我们在下表记录Loss函数的数值。
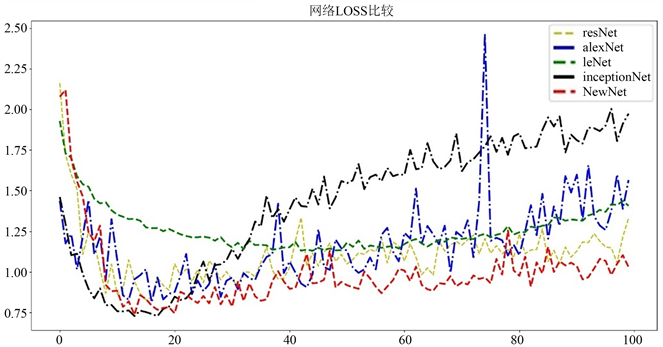
Figure 11. Comparison of error Loss function of Cifar10 dataset
图11. Cifar10数据集误差Loss函数比较
图11显示的是Cifar10数据集上损失函数的下降态势。红色的线代表新构造的神经网络,新网络在该数据集上的效果较好,和主流网络相比取得了较好的效果,是众多网络中Loss函数到达较低的一种网络。
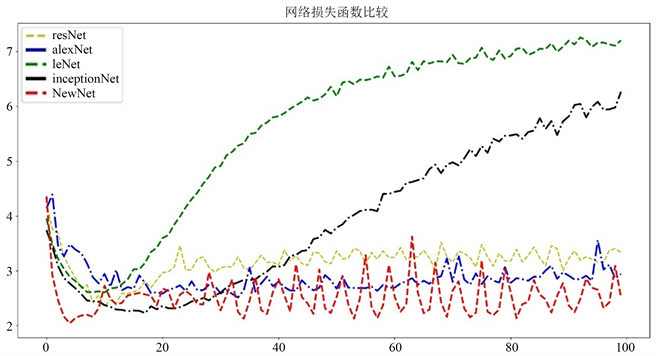
Figure 12. Comparison of error Loss function of Cifar100 dataset
图12. Cifar100数据集误差Loss函数比较
图12显示的是Cifar100数据集上损失函数的下降态势。由图可见红色的线代表新构造的神经网络,一共有五条曲线。可见NewNet网络的震荡虽然相对较大。相对其他网络的损失函数,新网络但是还保持在较低的水平上。该新网络取得了相对较好的效果。

Figure 13. Comparison of error Loss function of Fashion dataset
图13. Fashion数据集上误差Loss函数比较
图13显示的是Fashion数据集上损失函数的下降态势。依然是红色的线代表新构造的神经网络,一共有五条曲线。和其他曲线比较。NewNet保持在较低的水平上。我们可以说新网络取得了相对较好的效果。
以上可以总结出,新的神经网络在损失函数的下降方面由于简单的卷积神经网络,基本做到了比目前主流神经网络更好的效果。
4.3.4
. 对参数的微调处理
在训练过程中,对训练batch值,dropout [19] 值、迭代次数等参数做合理微调,找到优化的训练模型。我们在反复试验中找到了超参数的具体设置方法。参数如下:batch = 256,dropout = 0.2,在第六层卷积加入最大池化,第七层卷积加入BatchNormalization [20],GlobalAveragePooling [21] 使用dropout = 0.2,最后拉直层使用L2正则化 [22] 以及Softmax [23],迭代100次画出图形。在新网络在参数和结构的处理上,如下数据是原作者在当前条件下实验数次得出的结果,在复现时一般很难做出更好的结果。
5. 总结与展望
5.1. 方法总结
本文以实践中常用的三个经典数据集例,在总结前人研究的而基础上提出了模块化组合卷积神经网络,并分别从两个方面进行研究。一是对新型卷积神经网络重新架构。将InceptionNetBlock和ResNetBlock进行连接,得到了一个比之前方法相对更好的模型,其效果在准确率和损失函数曲线中得到证实。第二,基于超参数的微调。本文架构的网络比较简单,又希望提高准确率,本文使用了一系列的微调方法进行调整。包括使用数据扩增,加入BN层,L2正则化,Global average pooling方法。
5.2. 展望
随着深度学习技术的不断发展,图像分类的方法也层出不穷,使得人工智能技术也不断发展起来。本文基于基本的卷积神经网络,将经典卷积神经网络模块化,进而搭建出新的卷积神经网络,在新的卷积神经网络中训练模型。虽然有了一定量的优化,但是在以下方面还可以继续改进:
1) 我们可以将小数据集换成大型数据集在服务器上进行运行。换高性能显卡进行运算。可以考虑在服务器上建立Doker环境。在Doker环境中使用COCO数据集进行训练。
2) 可以借鉴最新的InceptionV4优化算法,在ResNet与结合后生成新的Inception-Resnet块,可以使用新Resnet块进行结合
3) 该模型同样可以引入DarkNet等其他的新卷积神经网路模块化后加入到新网络中进行比较。
4) 今后可以使用更大的数据集如:COCO数据集 [24] 进行训练与测试,使用更好的GPU进行训练,使用高batch送入神经网络。
5) 在本文研究神经网络的分类问题时候,由于数据集过小,有的时候很难将测试集准确率在提高,如果在参数大小没有制约的前提之下,可以考虑使用迁移学习的方式进行优化模型,可以将深度加深,在较大数据集上进行训练,训练完成后拿到模型文件,放入新的小数据集上进行再次训练,再次训练后放入测试集进行测试,这样可以大幅提高准确率。
6) 在训练时候,经常需要抑制过拟合的操作。可以使用数据扩增的方式对数据进行批量增广,这样可以有效地抑制过拟合。在实验中的经验发现,图像较小的数据集少量设置dropout并不会非常显著地提升准确率,并且由于l2正则化已经非常普遍,新网络效果比ResNet效果强,这主要是因为残差块和Inception模块对图像不停的特征都得到了处理,并且减少梯度爆炸以及梯度消失的可能。
随着图像分类技术的不断发展,卷积神经网络的架构方式也层出不穷,随着未来神经网络的不断发展,层数不断提升,精度不断升高,计算时间复杂度也会有着明显的降低。通过模块化后,会令不同的模块效果相互叠加,可能有协同效应,也有可能出现拮抗效应。开发者希望经过模块化组合后的算法在达到在满足安全性能的前提下,所需要的计算量最小化。通过更高效的更精准的图片分类方案来改进现有的分类算法,这是之后需要着手研究的问题。