1. 引言
随着虚拟现实(VR, Virtual Reality)和眼动追踪(ET, Eye Tracking)技术的兴起,越来越多内置摄像头的智能头盔产品被推广到消费者市场中 [1]。当用户佩戴智能头盔时,便能通过穿戴传感设备(数据手柄、手套)进行人机交互,享受沉浸式VR体验。在上述交互过程中,用户和机器分别扮演决策者和反馈者的身份,二者的关系为决策和执行,交互方式较为单一。如果能够赋予机器感知人类情绪的能力,那么便能分析出用户的使用习惯和心理状态识。通过分析用户的情绪状态,不仅能够改善智能设备系统的交互方式,而且还能指导开发厂商制定针对性的治疗方案和广告策略。因此,识别用户佩戴智能头盔下的情绪状态,对分析用户行为和改善人机交互方式具有重要意义。
当用户佩戴智能头盔时,面临两方面的挑战,一方面为面部上半区域被设备严重遮挡,难以获得有效的情绪特征;另一方面是在用户的使用过程中,产生较大的姿态变化,例如旋转和移动,导致面部特征位置定位不准确和特征提取难度较大。Ekman等人 [2] 从解剖学的角度出发,表明绝大部分情绪变换都与眼部区域的肌肉运动单元有关,眼部区域蕴含着丰富的情绪信息。因此,仅利用眼部区域识别出用户的情绪状态是可行的。通过眼部区域的情绪识别,不仅能解决面部遮挡问题,提取有效的情绪特征;还能利用摄像头与眼部之间的距离和角度相对不变特性,解决姿态变化带来的问题。
眼部情绪识别方法根据是否配置额外的传感设备,分为基于传感器和基于外观的方法,前者是利用传感设备捕获眼部生理特征进行用户情绪状态识别,后者是直接通过眼部区域图像推理出用户的情绪类别。虽然基于传感器的方法能够获取更多有效的情绪特征,但是需要更改智能头盔结构并且影响用户使用体验。随着深度学习的快速发展,相关研究人员提出基于外观的方法,利用卷积神经网络解决眼部区域的情绪识别问题。此类方法的大体思路是,首先从眼部图像中提取情绪特征,并用于预训练个性化分类器,增强模型的信息提取能力;然后,将个性化分类器加入网络框架中,并通过卷积神经网络输出情绪类别。虽然上述方法无需额外的传感器,但是以往工作提出的网络模型的参数量过于庞大且需要单独训练个性化分类器,导致模型在移动设备上运行缓慢且需要额外标定工作。
为了解决上述问题,本文提出一种基于标签分布学习的眼部情绪识别框架,主要由情绪识别网络和标签分布生成网络组成,见图1。情绪识别网络由局部特征增强模块、全局特征增强模块和轻量级ShuffleNet-V2 [3] 骨干网络组成,用于预测眼部情绪类别;标签分布生成网络选取ResNet50 [4] 网络生成眼部图像的情绪标签分布数据集,辅助眼部情绪网络的标签分布学习。通过标签分布生成网络生成眼部图像的情绪标签分布数据,并利用标签分布数据训练轻量级眼部识别网络,从而实现轻量级网络计算效率快和识别准确度高的效果。
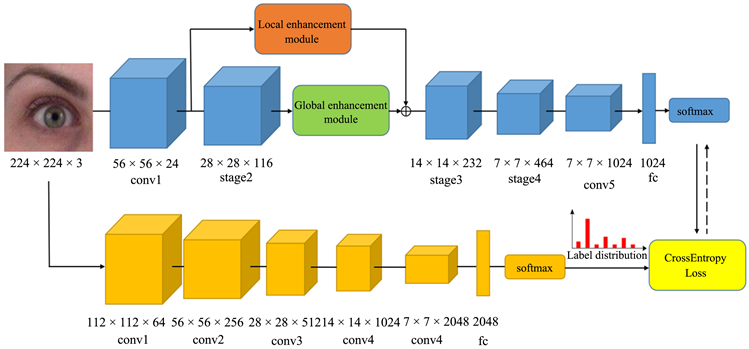
Figure 1. Eye emotion recognition network (up) and label distribution generation network (down)
图1. 眼部情绪识别网络(上)与标签分布生成网络(下)
迄今为止,有关眼部情绪数据集尚未开源。为了评估模型的性能,本文从两个方面构建实验数据集,一方面设计和搭建眼部情绪采集方案,收集真实环境下的眼部情绪数据集REED (Realistic Eye Emotion Datasets);另一方面利用公开的全脸情绪数据集MUG (Multimedia Understanding Group) [5],从全脸中裁剪出眼部区域的图像,制作实验环境下的眼部情绪数据集EMUG (Eye-Multimedia Understanding Group)。实验结果表明,本文方法在REED和EMUG数据集的识别准确度和识别效率均优于最先进的方法。本文主要贡献如下:
1) 提出轻量级的眼部情绪识别模型,利用注意力机制构建了局部特征强化模块和全局特征强化模块,解决轻量级网络提取信息能力不足和眼部区域情绪信息量少的问题。同时,该模型无需用户进行额外的标定工作,也能达到较优的准确度和识别效率。
2) 设计标签分布生成网络,通过自动生成眼部图像的情绪标签分布数据,辅助眼部情绪识别网络进行标签分布学习,改善数据集标签的歧义性问题,提高模型的鲁棒性。
3) 从两个方面构建实验数据集,一方面,通过设计一套眼部数据采集设备,建立真实环境下的数据集REED;另一方面,通过公开的全脸情绪数据集MUG,裁剪出相应的眼部情绪数据集EMUG。实验结果分析,本文网络模型在REED和EMUG的四分类情绪平均准确度分别为68.5%和80.9%,在七分类情绪平均准确度分别为62.0%和68.1%。
2. 相关工作
基于眼部区域的情绪识别是人脸情绪识别的一个分支,经过多年来的相关研究者的探索,取得较为丰富的研究成果。眼部情绪识别方法分为基于传感器和基于外观。
基于传感器的眼部情绪识别方法的思路是在头戴式设备配备不同的传感设备捕获用户眼部生理信号,并结合眼部图像建眼部情绪识别模型,推理出用户的情绪类别。早期的研究工作主要利用单一的眼部生理特性,并推理出眼部情绪状态。Scheirer等人 [6] 采用皮肤电压传感器检测眼部肌肉的电位变化,区分用户喜悦、困惑和平静的情绪状态。Fukumoto等人 [7] 利用光遮断器检测眼部肌肉的运动状态,判别用户中立、微笑和大笑的状态。Masai等人 [8] [9] 采用光学传感器检测眼部肌肉运动状态,并通过SVM [10] 模型判别情绪类别。然而,单一的生理特征容易受用户自身的生理状态影响,难以准确识别用户情绪状态。随着传感设备的发展,智能头盔能够装配各式各样的传感设备采集眼部的生理特征,相关研究者提出多模态融合的眼部情绪识别方法。Kwon等人 [11] 采取数据级融合的策略,首先通过传感器采集眼部的皮肤电反应和血容量搏动等生理信号数据,分别计算平均值、标准差等统计数据作为情感特征向量;接着,采用PCA方法 [12] 降低眼部图像的数据维度,提取相应的情感特征;最终,将统计特征和图像情感特征拼接融合,输入到SVM模型推理出情绪类别。Soleymani等人 [13] 采用决策级融合的策略,将眼球注视时间、瞳孔直径和脑电图(EEG)输入到不同的分类器进行训练,并在决策阶段将分类器输出的决策特征进行融合,进而推理用户的情绪类别。Nie等人 [14] 采用卷积神经网络和二叉决策树的组合策略,首先利用AlexNet [15] 提取眼部区域的眉毛内轮廓、眼睑形状以及瞳孔位置等信息,然后通过距离探测器和头部惯性传感器测量用户眼部肌肉和头部姿态的状态,最终将各种特征数据输入到二叉决策树中,进行判断用户的情绪状态。然而,上述方法存在一些不足,一方面需要配备额外的传感器,难以集成到现有的商业智能头盔;另一方面,传感器测量用户生理信号时,需要紧贴用户皮肤,影响用户的使用体验。
基于外观的眼部情绪识别方法与前者方法不同,其思路为仅从摄像头拍摄眼部区域图像识别出用户的情绪状态,无需装配额外的传感器设备。早期的工作主要利用眼球的几何特征和生理信息识别用户情绪。Babiker等人 [16] 利用眼球瞳孔直径大小来区分用户的情绪状态,当用户处于中立情绪时,瞳孔直径最小,正向情绪时次之,负面时瞳孔直径最大。Nummenmaa等人 [17] 利用眼球运动状态判别用户情绪状态,当用户的注视点长时间聚焦在某个区域,表明用户对该区域感兴趣。然而,上述方法使用的情绪特征变化单一,难以细粒度区分多种情绪类别。随着深度学习的发展,相关研究者利用卷积神经网络解决眼部情绪识别任务。Hickson等人 [18] 利用InceptionNet [19] 提取眼部图像中眼部区域的动作信息,并根据识别出的动作组合判别用户的情绪状态。此外,该工作利用各种情绪的图像减去其中立情绪构建个性化分类器,解决不同用户情绪表达差异的问题。实验表明,该方法在自建数据集上,识别出五类情绪的平均准确率为73.7%。Wu等人 [20] 选择ResNet18提取眼部情绪特征,通过Kmeans [21] 聚类算法为不同用户制定个性化分类器。同时,为了提高网络识别效率,采用SiameseNet [22] 网络判断视频帧的用户是否相似,相似则跳过。最终,该方法在自建数据集上,识别七类情绪的平均准确率为76.6%。
综上所述,基于深度学习的眼部情绪识别方法具有两点优势,一方面无需装配额外的传感器设备,另一方面能够区分更加细粒度的情绪状态。但是上述方法存在一些不足:1) 网络模型过于复杂,难以在移动设备上高效运行;2) 需要用户进行额外标定工作,并单独训练个性化分类器。因此,本文提出一种轻量级基于标签分布学习的眼部情绪识别框架,旨在无需用户进行额外标定的工作,也能达到较优的准确度和识别效率。
3. 方法
本文提出一种基于标签分布学习的眼部情绪识别框架,框架分为情绪识别网络和标签分布生成网络。情绪识别网络由局部特征增强模块、全局特征增强模块和轻量级ShuffleNet-V2骨干网络组成,用于预测眼部情绪类别;标签分布生成网络选取ResNet50网络自动生成眼部图像的情绪标签分布数据集,辅助眼部情绪网络的标签分布学习。
3.1. 眼部情绪识别网络
基于外观的眼部情绪识别方法,主要存在智能头盔计算资源有限和眼部区域情绪信息量少等问题。Hickson等人 [18] 采取深度网络和个性化分类器的策略解决情绪信息量少的问题,但是需要额外标定工作和消耗大量的计算资源。为了解决上述问题,本文的眼部情绪识别网络采用ShuffleNet-V2轻量级网络作为主干网络,加入局部特征增强模块和全局特征增强模块,从而实现高效、准确且无需额外标定的效果。
眼部情绪识别网络首先将眼部图像初步提取情绪特征,通过局部特征增强模块和全局特征增强模块赋予有效的情绪信息特征更大的权重。然后,将局部信息和全局信息进行特征融合,并输出到后续的Stage3、Stage4、Conv5网络层中;最后,通过全连接层和Softmax层输出对应情绪类别。
3.2. 局部特征增强模块
Ekman等人 [2] 从解剖学的角度出发,表明不同面部运动单元(Action Unit,AU)对应不同情绪类别。为了情绪识别网络聚焦于有效的眼部情绪AU,本文构建基于注意力机制的局部特征增强模块,见图2。
首先,将大小224 × 224 × 3的眼部区域图像输入眼部情绪识别网络中,通过Conv1卷积层输出大小56 × 56 × 24情绪特征图;然后,将情绪特征图平分为4个28 × 28 × 24的情绪特征子图,并输入到2个卷积层获得大小为14 × 14 × 116深层的情绪特征子图,其中;最后,利用AttentionNet [23] 根据AU重要性赋予不同特征子图的相应情绪特征权重,并与深层的情绪特征子图相乘,合并输出28 × 28 × 116局部增强特征图。
3.3. 全局特征增强模块
虽然局部特征增强模块增强关键AU的表达能力,但是缺乏捕获眼部区域AU之间的相关性和全局性信息的能力,不利于推断困难样本。为了解决上述问题,本文基于Park等人 [24] 提出的BAM (Bottleneck Attention Module),设计出全局特征增强模块,见图3。全局特征增强模块由通道模块(Channel Module)和空间模块(Spatial Module)组成,通过提取特征图的通道信息和空间信息,寻找特征图AU之间的相关性。

Figure 3. Channel module (up) and spatial module (down)
图3. 通道模块(上)和空间模块(下)
特征图通过Stage2模块输出大小28 × 28 × 116的特征图,分别输入到通道模块和空间模块。通道模块的作用是关注不同通道重要性,根据任务需求进行强化或者抑制不同通道。通道模块的提取步骤是,将输入全局平均池化层GAP进行通道融合,并利用2个全连接层Gfc计算出大小1 × 1 × 116通道权重特征。空间模块是为了聚焦眼部区域AU的空间位置信息,计算整个特征图的空间注意力权重,强化或者抑制不同空间位置特征表达能力。空间模块基于He等人 [4] 提出瓶颈结构(Bottleneck Structure),由2个1 × 1卷积层和2个3 × 3卷积层组成,用于提取眼部区域AU的空间信息。空间模块的特征提取思路是,首先利用1 × 1卷积层进行升维操作提高通道数量,并融合通道信息;然后,通过2个3 × 3卷积层进行空间信息变换,关联上下文信息;最后,经过1 × 1卷积层进行降维操作,输出大小28 × 28 × 1的空间权重特征。
在上述提取过程中,首先将通道模块和空间模块生成的特征权重和映射到同一维度空间,进行特征权重融合;然后,通过Sigmoid激活函数输出0到1之间的大小为28 × 28 × 116全局特征信息权重;最终,通过乘法运算将加权到每个通道的特征上,输出大小28 × 28 × 116的全局特征图。
至此,将眼部情绪识别网络生成的局部特征图和全局特征图进行元素求和,输入到后续Stage3,stage4和Conv5网络层中,并通过全连接层的信息融合和Softmax函数的概率化,输出用户情绪类别。
3.4. 情绪标签分布生成网络
标签分布学习的关键问题是如何构建标签分布数据集,通常的做法是根据样本的纹理特征和结构信息构建样本标签映射函数,从而生成相应的标签分布数据集。但上述方法仅适用特定的场景和数据,限制模型的泛化能力。Zhao等人 [25] 利用卷积神经网络强大的提取能力,自动生成人脸情绪标签数据集,有效解决标注者标注错误的主观问题和图像模糊带来错误的客观问题。
受到该工作的启发,眼部情绪标签生成网络利用ResNet50深层网络自动生成眼部图像的情绪分布标签,辅助眼部情绪识别网络的参数训练。眼部情绪标签生成网络采用迁移学习方式,解决眼部数据的情绪信息不足和缺乏大型的公开数据集等问题,提高情绪数据标签分布的准确性。在迁移学习过程中,首先将情绪标签生成网络在公开全脸数据集FER2013 [26] 进行预训练参数权重;然后,将模型在EMUG数据集上进行参数微调,使其适应目标场景。
当迁移学习完成时,眼部情绪标签生成网络能够产生眼部图像的情绪标签分布,用于辅助训练眼部情绪识别网络。具体而言,给定一个图像f和其对应的情绪标签
,其中c是情绪种类数目。首先利用情绪标签生成网络的卷积层对图像f进行特征提取,然后将情绪特征输入到全连接层进行特征融合,输出各类别的情绪标签向量
;最后,利用Softmax函数生成情绪标签分布
,
(1)
其中
。
3.5. 损失函数
根据上文所述,情绪标签生成网络的输出是真实标签分布,眼部情绪识别网络的输出是预估标签分布。因此,本文网络的损失函数采用交叉熵函数,计算真实标签分布和预估标签分布的差距,利用反向传播对眼部情绪识别网络的参数进行更新,即
(2)
其中,N为样本数目,
为眼部情绪识别网络的预估情绪标签分布,上标p为样本序号,下标q为情绪类别。
4. 实验与结果分析
4.1. 实验数据集
迄今为止,有关眼部情绪数据集尚未开源。为了评估模型的性能,本文从两方面构建实验数据集,一方面是设计和搭建眼部情绪采集方案,收集真实环境下的眼部情绪数据集REED (Realistic Eye Emotion Datasets);另一方面是利用公开的全脸情绪数据集MUG,通过裁剪眼部区域的图像,制作实验环境下的眼部情绪数据集EMUG (Eye-MUG)。
4.1.1. 自建数据集
为了采集真实环境下的眼部区域图像,我们搭建一套简易的采集设备,设备主要由头戴设备、支撑力臂和摄像头组成,见图4。通过头盔和可调节支撑力臂的组合,能够自由调节志愿者的眼部区域与摄像头间的角度和距离,便于数据采集。同时,为了减少外界光照影响和提高图像质量,选择带6个发光二极管的红外且分辨率为640 × 480的摄像头,其中采集频率为30帧/秒。
REED的数据采集工作共征集25位志愿者,其中男性14名、女性11名。在数据采集的过程中,首先要求志愿者佩戴采集设备观看情绪诱导图片,激发和指导志愿者做出相应的情绪状态;然后,利用OpenCV图像处理工具收集志愿者的眼部区域视频并标注相应的情绪类别;最终,清理闭眼和情绪切换时产生的错误情绪图像数据。

Figure 4. Schematic diagram of eye data acquisition equipment
图4. 眼部数据采集设备示意图
每位志愿者采集7类情绪,分别为悲伤、恐惧、惊讶、愤怒、快乐、厌恶、平静,见图5。每类情绪需要采集2次,每次采集拍摄7秒时长的视频,数据采集总时长为2450秒,图像总数为73,500张。通过数据清理,筛选出53,375张图像,其中每位志愿者的每类情绪图像约为305张。对于筛选出来的图像,根据所属志愿者的不同进行分组,从中随机挑选10组志愿者的数据作为训练集,5组志愿者的数据作为验证集,10组志愿者的数据作为测试集。

Figure 5. REED dataset, seven eye emotion images from the same volunteer
图5. REED数据集,同一志愿者的七种眼部情绪图像
4.1.2. 裁剪数据集
从全脸情绪数据集裁剪出眼部情绪数据集的要求有两方面,一方面需要图像分辨率高和无遮挡的图像,才能裁剪出高质量的眼部区域图像;另一方面需要稳定的光照条件和头部姿态,才能模拟佩戴智能头盔下的场景。因此,本文选取全脸情绪数据集MUG制作眼部情绪数据集EMUG。
MUG公开数据集共有52位志愿者的全脸情绪图像,情绪类别共7类,分别是悲伤、恐惧、惊讶、愤怒、快乐、厌恶、平静,见图6。每类情绪收集3到5组的视频序列,每组序列往往有50到150张图像。制作EMUG的过程中,利用Eivazi等人 [27] 提出的眼部区域检测方法将MUG的全脸情绪图像裁剪出相应的眼部区域,使用手工剔除闭眼和错误情绪的图像,并将每张图像打上相应的情绪类别标签。EMUG数据集共有52位志愿者,包含七类情绪,分别是悲伤、恐惧、惊讶、愤怒、快乐、厌恶、平静,见图7。其中,每位志愿者的每类情绪图像约为184张,数据集总共包含66,976张图像。为了更加合理测试网络性能,EMUG数据集根据所属志愿者的不同进行分组,从中随机挑选28组志愿者的数据作为训练集,12组志愿者的数据作为验证集,12组志愿者的数据作为测试集。

Figure 6. Seven facial emotions from the same volunteer from the public data set MUG
图6. 来自公开数据集MUG同一志愿者的七种面部情绪

Figure 7. Expose the EMUG dataset image of the culled dataset MUG
图7. 公开数据集MUG经过裁剪后的EMUG数据集图像
4.2. 实验设置
本文对所有数据集预处理操作,将图像大小调整为224 × 224像素,便于模型的训练和评估,利用随机裁剪和水平翻转等手段,增加样本的多样性和减少模型的过拟合。实验模型的损失函数选择带动量优化的随机梯度下降算法(Stochastic Gradient Descent, SGD),并将动量值设置为0.8。同时,模型初始学习率设置为0.0001,训练批次样本数量为128,共需要600次周期训练。
实验的硬件配置如下,CPU为AMD Ryzen 5 3600、GPU为NVIDIA GeForce RTX2070s 8GB、RAM为32GB,并采用Pytorch 1.9搭建、训练和评估网络模型。
4.3. 评估指标
本文模型的评估指标采用精确率P和F1评分。准确率P,召回率R和F1评分的计算公式为:
(3)
(4)
(5)
其中,TP是真正例,FP是假正例,FN是假负例。
本文的网络模型学习方式分为单标签学习和多标签学习,单标签学习的模型输出预测标签是单元组;虽然多标签学习模型输出的预测标签是多元组,但会采用最大值函数输出多元组里的最大概率值,即输出预测值仍为单标签。
4.4. 对比模型介绍
为了验证本文方法的有效性,本文对比相近工作的Eyemotion [18] 和EMO [20] 模型。
Eyemotion采用其他情绪类别减去平静情绪类别的像素值的策略构建个性化分类器,增强提取眼部区域的情绪特征,并将个性化分类器加入Inception网络识别用户情绪。该方法支持5类情绪识别,分别是愤怒、惊讶、快乐、平静和眯眼。由于眯眼更多体现眼部生理上的运动状态,难以体现用户的情绪状态,因此不在实验的讨论范围内。
EMO采用Kmeans聚类方法构建个性化分类器,并将个性化分类器加入ResNet18网络输出情绪状态。该方法支持7类情绪识别,分别是悲伤、恐惧、惊讶、愤怒、快乐、厌恶、平静。
迄今为止,Eyemotion和EMO是最接近本文工作的内容——基于眼部区域的情绪识别,但是二者所使用的模型、训练代码和实验数据尚未公开。因此,本文复现了二者的网络模型。因为Eyemotion和EMO需要在微调阶段前构建个性化分类器模块,所以提前进行额外的标定工作。本文方法和前者两种方法的训练策略都采用迁移学习方法,在预训练阶段,三种方法均选用ImageNet数据集进行参数更新。在微调阶段,利用REED数据集和EMUG数据集的训练集和验证集对三种方法的网络模型进行参数微调,并使用测试集对模型进行性能评估。
4.5. 实验结果与分析
4.5.1. 对比实验
三种方法分别在REED和EMUG数据集上,进行四分类情绪和七分类情绪准确度对比实验。
四分类情绪识别在REED和EMUG数据集上的实验结果,见表1。结果表明,本文方法的F1值分别达到0.720和0.826,准确率分别达到68.5%和80.9%。相比较于最优模型EMO,本文模型的F1指标分别提高了0.067和0.042,平均准确度分别提高了3.8%和4.0%。其中,三种方法在REED数据集的准确度要明显低于EMUG数据集,原因有两方面,一方面是REED数据集样本数目要少于EMUG数据集,另一方面是实际环境数据集存在标签歧义性和图像质量不佳的问题。

Table 1. Experimental results of four categories of eye emotion recognition
表1. 四分类眼部情绪识别实验结果
七分类情绪识别在REED和EMUG数据集的实验结果,见表2。结果表明,本文方法的F1值分别达到0.658和0.702,准确率分别达到62.0%和68.1%。相比较于最优模型EMO,本文模型的性能表现更佳。其中,七分类情绪的准确度低于四分类的准确度,原因是存在部分情绪类别的眼部AU表达类似,例如恐惧和惊讶、愤怒和厌恶,使样本标签具有歧义性,增加识别难度。
综上所述,本文所提的方法模型优于其他方法的原因是,一方面标签分布学习减少了数据集带来的数据标签歧义性影响;另一方面局部模块和空间模块具有更强的特征提取能力,能够在实际环境中取得更佳的性能。
Table 2. Experimental results of seven categories of eye emotion recognition
表2. 七分类眼部情绪识别实验结果
4.5.2. 消融实验
为了验证各个组件的有效性,将在REED数据集和EMUG数据集上进行四分类情绪识别的组件消融实验,结果见表3。消融实验选择ShuffleNet-V2网络模型作为基线网络,分别将局部增强模块(Local Enhancement Module, LEM)和全局增强模块(Global Enhancement Module, GEM)添加到基线网络中,进行组合测试。当基线网络仅添加局部特征增强模块时,在REED数据集和EMUG数据集上的四分类情绪识别准确度分别比基线网络提高了6.6%和8.2%。当基线网络仅添加全局增强模块时,在REED数据集和EMUG数据集上的四分类情绪识别准确度分别比基线网络提高了6.1%和7.7%。当基线网络情加入了局部特征增强模块和全局特征增强模块,即本文所提出的眼部情绪识别网络,虽然网络模型增加了微小的计算开销,但性能提升明显。
Table 3. Experimental results of different modules
表3. 不同模块实验结果
为了验证标签分布学习方法的有效性,选择在REED数据集和EMUG数据集进行不同学习方式的四分类情绪识别消融实验,比较基于标签分布生成网络(Label Distribution Generator Network, LDGN)生成标签分布概率的标签分布学习(LDL)与传统的单标签学习(SLL)的性能优劣,结果见表4。消融实验的基线网络选择EMO模型。本文的方法在REED数据集和EMUG数据集的结果表明,标签分布学习和单标签学习的准确度分别比基线网络提高了1.8%和3.8%。同时,基线网络通过标签分布学习方法,网络性能也有一定的提升,在REED数据集和EMUG数据集的准确度分别提高了3.1%和1.6%。值得注意的是,基于标签分布学习的情绪识别网络的参数量远低于LDG的参数量,但在性能上优于LDG。基于标签分布学习的方法实现高准确度的原因有两方面,一方面是人类情绪是由多个基本情绪组合而成,标签分布更加符合客观世界;另一方面,LDG生成的标签分布能够减少标签歧义性和人为标注错误。
Table 4. Experimental results of different modules
表4. 不同模块实验结果
5. 结论
为了解决眼部情绪识别信息量少和识别效率慢的问题,本文提出一个基于标签分布学习的眼部情绪识别框架。网络框架由眼部情绪识别网络和情绪标签生成网络组成,通过情绪标签生成网络输出眼部图像的情绪标签分布数据,对轻量级的眼部情绪识别网络进行参数更新,使得轻量级的眼部情绪识别网络实现较优的准确度和识别效率。同时,引入基于注意力机制的局部特征强化模块和全局特征强化模块,增强眼部情绪识别网络的特征提取能力,进一步网络的识别准确度。此外,为了评估网络的性能,构建了REED和EMUG眼部情绪数据集。实验结果表明,本文模型在REED和EMUG数据集上的识别准确度和识别效率均优于同类别的方法。
基金项目
广东省重点领域研发计划项目(编号2020B0101130019,2019B010150002),国家自然科学基金(批准号61907009)。