1. 引言
知识库问答分为两步,实体链接和关系预测。实体链接负责从问句中识别出指代并映射到知识库对应的话题实体;关系预测用于理解问句意图,预测问句问及实体的关系路径。最终通过实体及关系路径映射到知识库的一个三元组,作为问句答案。
面向中文短文本的实体链接(Entity Linking),是自然语言处理领域的基础任务之一,即对于给定的一个中文短文本(如问答中的问句、微博短文等)识别出其中的指代,并与给定知识库中的话题实体进行关联的过程,包括实体指代识别和实体消歧两个子任务 [1]。在NLP社区的研究中,实体链接经常被忽视。国外学者 [2] [3] [4] 认为通过问句中的实体指代和知识库实体在字面上的相似度匹配就能解决。本文分析中文数据集 [5] 发现:1) 未见实体指代多,占测试集的85%。2) 95%的实体指代对应的知识库候选实体都存在相同的重叠词(overlap)。模型要在短文本提供极少信息下挖掘字面相似的候选实体之间的差别。3) 缺少知识库的背景知识,人类也无法给出指代映射的正确实体。例如短文本“2013年12月永宁站的日进出人次是多少排名第几?”,指代“永宁站”是一个未见实体,仅出现在测试集中。指代对应的知识库候选实体是{永宁站,永宁站(新北市),永宁站(沈吉铁路)}。均存在相同重叠词“永宁站”,从上下文信息中,只能推断问句问及一个车站的信息,但无法分辨出话题实体。
针对上述问题,已有一定的研究成果。工作 [6] 采用预训练模型BERT [7] 以及流水线的方式,把实体识别建模为序列批注识别出实体指代,然后将其与候选实体作为实体消歧的输入,建模为句对匹配,输出候选实体的分值。采用预训练模型一定程度上解决了未见指代首次登陆的问题,但容易识别出知识库不存在实体的错误指代。同时该工作并未利用到知识库信息。工作 [8] 在工作 [6] 基础上沿用了预训练模型BERT以及流水线的方式,在实体消歧上把实体描述文本拼接到候选实体后,引入知识库信息提升实体消歧的表现,在数据集 [9] 中获得最佳表现。但在句对表示上并未深入研究,仅简单取指代的首尾token作为匹配的最终表示。在实体识别中结合了BERT、GRU和CNN,参数量大且结构较为复杂。
为解决在中文实体链接上的问题,本文在目前已有研究的基础上,对基于BERT的中文实体链接框架提出了一个优化模型Entity Knowledge subgraph-BERT (EKBERT)。主要贡献如下:
1) 提出一种统一的知识标记方法,同时应用到实体链接的实体识别和实体消歧任务。
2) 在实体消歧任务上,引入候选实体的一跳子图增强上下文信息,结合知识标记提取指代和候选实体的片段表示,传入孪生网络得到更好的句子对表示以及候选实体得分。
3) 在公开的中文实体链接和中文知识库问答任务上进行实验,达到了目前公开的最佳效果。
2. 相关工作
2.1. 中文知识库问答
知识库由大量三元组[<主语>,<谓语>,<宾语>]构成。知识库问答的目标是把一个自然语言的问句转化成一个查询语句,通过检索知识库得到答案。目前主要分为基于语义解析和基于信息检索两种方法 [10],基于语义解析的方法直接从自然语言问句中解析出实体、关系及逻辑组合,转化为知识库上的查询语句并从知识库查询返回答案。方法 [11] 利用序列标注模型解析问句中的实体、利用端到端模型解析问句中的关系序列。基于语义解析的方法通常依赖大量人力进行关系分类的标注,难以预测训练集中未出现的关系。基于信息检索的方法在识别指代并链接实体的基础上,从知识库中召回候选实体的关系路径,并与问句进行语义匹配的排序,选择出最可能的路径从知识库中检索答案。方法 [2] 提出增强路径匹配的方法,实现问句与候选路径的多层次匹配。相比于基于语义解析的方法,基于信息检索的方法在路径选择方面具有更好的泛化能力,能够应用在较大的知识库中。
2.2. 基于预训练语言模型的实体链接
深度学习的实体链接方法 [12] 中,一般分为指代识别和实体消歧两步。在指代识别上,方法 [13] 等人使用了一个别名词典和LSTM语言模型进行指代识别,方法 [7] [8] [14] [15] 用了基于BERT语言模型做指代识别,方法 [14] [15] 基于知识库特点构建了领域词典,基于精确匹配辅助深度学习模型提高了整体的泛化能力。但未实现利用知识库融合到端到端的实体识别模型。方法 [16] 采用了预训练模型并引入了知识库实体信息。通过拼接知识库实体及其描述信息,输入BERT得到实体嵌入表示,然后与双向GRU网络的提取的语义表示进行拼接,输入一维卷积网络,最终输出每个token的二分类结果进行指代识别。但网络结构较为复杂。方法 [15] 在方法 [17] 提出的模型FLAT上,把知识库实体作为词典融入lattice特征,再基于BERT做实体识别,上述工作都利用知识库进行端到端的中文实体识别。
在实体消歧上,一般建模为文本匹配的排序问题。方法 [4] 提出一个引入Lattice结构的CNN网络,从词和字层面上编码,解决中文文本无法避免的分词错误从而得到更好的文本匹配表示。但未利用预训练语言模型,模型需要标注数据较多。方法 [7] 采用预训练语言模型BERT建模问句和候选实体的匹配任务,提高泛化能力。方法 [14] 在利用BERT得到匹配得分上,再规定了实体长度,实体出度,实体与提问词的距离等特征,构建了一个基于特征的评分机制,但超参数设置难控制。方法 [8] 结合BERT的匹配得分和基于多个特征通过LightGBM得到另一个匹配得分,相加得到最终得分。但仍依赖人为规定,且未利用知识库的信息。方法 [18] 等人提出一个基于BERT的孪生神经网络匹配模型,节省了参数及推理时间,并获得更好的文本匹配表示,证实了孪生网络在句子表示中的作用。但并未在短文本实体链接任务上验证。
2.3. 融入知识的预训练语言模型
最近,很多工作研究把知识融入到预训练语言模型中。方法 [19] 先把文本变成知识增强的句子树,然后通过软位置编码和掩盖注意力机制把知识融入到语言模型中,不影响原来学习好的参数解决知识噪声问题。在特定领域的中文序列批注和中文长文本匹配上得到验证,但未在中文实体链接任务上实验。方法 [20] 等人利用维基百科额外的实体描述信息作为上下文信息,从而提高需要推理的问答任务的表现。方法 [21] 等人利用BERT以及实体信息解决实体关系分类问题。这些工作都表明注入知识到语言模型中的有效性,能提升下游任务的表现,
3. 本文方法
3.1. EKBERT整体结构
EKBERT模型的整体结构如图1所示。本实体链接方法由两个部分组成,指代识别模型和实体消歧模型。给定一个问句Q,我们将它与知识库的实体进行精确匹配,在问句中匹配的词前后插入特殊标记“|”,然后输入指代识别模型,模型输出问句的实体指代m。通过数据集提供的mention2id字典得到指代对应的所有候选实体
,把问句Q和逐个候选实体ei组成句子对。同时,从知识库中检索候选实体ei的一跳子图,作为上下文信息拼接在候选实体ei后。最后,在指代和候选实体的前后插入特殊标记“#”和“$”标出位置。输入到实体消歧模型。该模块直接输出候选实体的得分p,分值最高的候选实体ei作为问句指代映射到知识库的话题实体,完成实体链接。

Figure 1. The overall architecture of EKBERT
图1. EKBERT实体链接的整体架构
3.2. 实体指代识别
EKBERT的指代识别模型基于BERT-Softmax模型,输入问句Q,输出指代m,如图2所示。为了召回更多知识库中的实体同时提高指代识别的准确率,我们希望进一步挖掘知识库中的有用信息。知识库中的实体往往隐藏指代,我们将问句与知识库的实体进行精确匹配。这里会涉及ner任务的嵌套实体问题。比如知识库中存在实体“永宁”和“永宁站”。“进出”和“进出人次”。我们会在这些词的前后插入标记“|”,如果同一个字前(或后)有多个词边界,只会插入一次特殊标记“|”。比如问句“2013年12月永宁站的日进出人次是多少排名第几?”与知识库精确匹配的实体是{2月,永宁,永宁站,进出,进出人次},匹配后的输入文本为“2013年1|2月|永宁|站|的日|进出|人次|是多少排名第几?”。“永”字前只会插入一次“|”。标注方法采用BIO,引入的标记“|”会根据是否在指代span 内确定,在指代span 以外标签为“O”,在指代span 以内标签为“I”。另外,涉及书名号的命名实体,把书名号统一标记到命名实体的span 中。

Figure 2. Mention detection model of EKBERT
图2. EKBERT的指代识别模型
3.3. 实体消歧
EKBERT的实体消歧模型如图3所示,编码层是BERT,对输入的句子对进行编码。中间层是一个孪生的前馈全连接神经网络,得到指代m和候选实体ei匹配表示,输出层用Softmax分类器给出候选实体ei的分值。
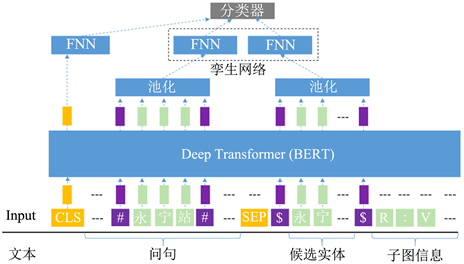
Figure 3. Entity disambiguation model of EKBERT
图3. EKBERT的实体消歧模型
3.3.1. 知识库信息增强
知识库信息:给定一个指代m,通过mention2id字典我们得到候选实体集合
。对于该集合中的每一个候选实体ei,我们从提供的知识库中检索得到若干个三元组,把带指代m的问句Q作为句子1,候选实体ei和它的一跳子图拼接作为句子2。其中,一跳子图由候选实体(头实体)直接相连的多组“关系r:尾实体o”(或“属性:属性值”)组成,不同的“关系:尾实体”(或“属性:属性值”)用“|”分隔开。
实体边界信息:我们希望模型能捕捉到指代和候选实体的边界,因此,在指代词前后添加标记“#”,在候选实体前后添加标记“$”。最终,我们把问句,候选实体,知识库子图按公式(1)输入BERT的编码器:
(1)
3.3.2. 池化策略及孪生神经网络
假设每个token的隐层表示是
。向量
到
表示指代m的隐层表示,向量
到
表示候选实体
的隐层表示。我们通过池化(平均或最大)和激活函数tanh得到指代m和候选实体
的一维向量表示。由于孪生神经网络(Siamese Transformer [18]、Siamese BiLSTM [22] [23]、Siamese CNN [24])在句子对匹配任务得到充分的验证,其结构能挖掘句子对中的深层差异,得到更好的句子嵌入。本文采用Siamese FNN作为中间层,经过BERT得到的指代和候选实体表示已经包含丰富的交互信息,因此用结构简单的FNN (
)做孪生网络的编码层。对指代m的token向量
到
进行平均池化后,得到它的最终表示
。过程公式化为:
(2)
对候选实体ei的token向量
到
进行平均池化后,它的最终表示为
。过程公式化为:
(3)
[CLS]位置的token向量作为句子表示,我们通过另一个FNN (
)得到其最终表示
,过程公式化为:
(4)
最后,把这4个向量
拼接,输入到Softmax分类器,得到每个候选实体的二分类概率。标签1的输出对应得分,得分越高越可能是话题实体。
在训练过程中,我们使用交叉熵作为损失函数并在每个全连接层之前应用了dropout,防止模型过拟合。
4. 实验
4.1. 数据集和评估指标
我们在两个中文数据集中进行了实验。第一个是NLPCC 2016 CKBQA知识库问答数据集 [5]。数据集提供了:1) 14,609个问答对的训练集和9870个问答对的测试集;2) 一个接近4300万条SPO的知识库;3) 一个叫mention2id的指代词与候选实体的映射字典。第二个是CCKS 2019 EL实体链接数据集 [25]。数据集提供:1) 一个约365万条SPO的知识库;2) 9万条训练集,1万条验证集,3万条测试集;3) mention2id字典。
原始数据集提供的数据格式如表1,我们沿用工作 [7] 的方法,调整成适合指代识别,实体消歧任务的格式。构建出来的形式如表2、表3所示。对于指代识别模型,我们采用精确率Precision、召回率Recall和F1值进行评估。对于实体消歧模型,我们采用Top 1、Top 2、Top 3的准确率和平均倒排数MRR进行评估。对于整个实体链接任务,我们采用Top 1、Top 2、Top 3的准确率进行评估。

Table 1. An example in NLPCC 2016 CKBQA dataset
表1. 原始数据集NLPCC 2016 CKBQA的案例格式
Table 2. An example in mention detection
表2. 指代识别的案例格式
Table 3. An example in entity disambiguation
表3. 实体消歧的案例格式
4.2. 实验设置
4.2.1. 数据预处理
由于数据集中的有大量指代带有书名号,构建指代识别数据集时,我们统一把书名号标注到命名实体中,否则书名号《》的标注不统一会影响指代识别模型的表现。
4.2.2. 超参数设置
表4展示了实验使用的超参数。第一组参数用于指代识别,和工作 [7] 保持一致,第二组用于实体消歧。其中最大序列长度Maxlength由拼接了知识库子图信息的上下文平均长度决定,最大序列长度设置到380能覆盖数据集95%的案例。不注入知识库信息,设置到60则能覆盖数据集95%的案例。
4.3. 实验效果及分析
实验的基准模型有两类:1) 数据集的SOTA模型:BB-KBQA [7] 和方法 [8];2) K-BERT [19],该模型在预训练模型BERT中巧妙融入了知识库,并在NER任务MSRA-NER、NLPCC-DBQA和匹配任务LCQMC、NLPCC-DBQA中表现最好。
4.3.1. 指代识别模块效果
指代识别模型的表现如表5所示。NLPCC CKBQA数据集中,BB-KBQA [7] 用的是BERT-CRF模型,没有利用知识库,表现最低。方法 [8] 利用BERT直接推理得到实体描述表示,作为知识增强表示,序列标注过程先用BERT-BiLSTM编码,然后每个token拼接前述的实体描述表示,用一维卷积作为解码层,网络结构复杂且参数量大。K-BERT [19] 融入了知识库信息,但由于在句子中实体后插入大量实体描述信息,导致知识噪声问题。本方法提出的EKBERT-MD (mention detection)在原句子中,匹配知识库的实体前后插入知识标记“|”,不影响语义并利用知识库实体的边界信息,实验结果在两个数据集上的表现都有提升。
Table 5. Mention detection results (%)
表5. 指代识别的表现(%)
4.3.2. 实体消歧模块效果
实体消歧模型的表现如表6所示。融入知识库信息的模型比没有利用知识库的BB-KBQA [7] 有明显提升,K-BERT [19] 在句子中实体后直接插入了子图信息,当插入信息远大于文本长度,会影响整个语句的语义表示,因此提升有限。方法 [8] 将注入了实体描述信息,并取指代前后位置的token作为匹配表示,是数据集中公开的第一名。我们提出的EKBERT-ED (entity disambiguation)注入了实体描述信息和指代、实体标记,取标记范围内的token池化(max表示最大池化,ave表示平均池化),通过Siamese FNN编码输出得分。表现优于K-BERT,并接近方法 [8]。
Table 6. Entity disambiguation results (%)
表6. 实体消歧的表现(%)
4.3.3. 实体链接效果
联合指代识别和实体消歧模型,整体的实体链接结果如表7所示,在两个数据集上的表现都比现有方法有所提升。
Table 7. Entity linking results (%)
表7. 实体链接的表现(%)
4.3.4. 知识库问答
为了证明本文的实体链接模型能为整个KBQA任务带来提升,我们进行了完整实验。我们采用与工作 [7] 相同的关系预测模型和检索答案的计分公式,只替换实体链接模型。关系预测模型给出候选关系得分ST,实体链接模型给出候选实体得分Se,通过加权和得到最终得分。我们复现的关系预测模型accuracy表现是Top 1 (94.75%),Top 2 (97.99%),Top 3 (98.82%),贴近公开数据(表8)。最终,联合我们提出的实体链接模型。在CKBQA任务 [5] 中F1值上为87.34%,比工作 [7] 提升了3%。
Table 8. Comparison of public results and our reproduced results (%)
表8. 公开数据和复现数据对比(%)
4.4. 消融实验
为了理解除BERT以外的其余组件给实体消歧带来的提升,我们在数据集 [5] 设置了消融实验。我们把除去实体边界信息的实体消歧模型标为EKBERT-ED-w/o etoken,把除去实体边界信息和知识库信息的实体消歧模型标为EKBERT-ED-w/o etoken + kg。消融实验结果如表9所示,从趋势发现,去掉更多组件,表现逐步变差。注入实体的知识库信息和实体边界信息的方法分别带来2.18%和2.08%的提升。
Table 9. Comparison of our model with different components (%)
表9. 不同组件的模型对比(%)
4.5. 案例分析
进一步分析实验结果,我们给出几个有代表性的案例分析,如表10所示。
Table 10. Representative examples in experiment results
表10. 具有代表性的实验案例分析
案例1至3展示指代识别模型的效果。案例1和案例2都涉及嵌套实体问题,“动物地鸠属”由命名实体“动物”“地鸠属”组成,“赵文卓甄子丹事件”由“赵文卓”,“甄子丹”,“事件”组成。而目标指代分别是“地鸠属”和“赵文卓甄子丹事件”。我们引入的特殊token“|”的方法让模型识别出正确的指代。方法 [5] 未识别出正确指代。案例4和5展示实体消歧模块的能力,案例4中,本文和方法 [5] 均接收正确指代“高等数学”,本文模型从18个都具有重叠词“高等数学”的候选实体中给出正确的实体“高等数学”,方法 [5] 预测的是“高等数学(北大版高等数学)”。其中15个候选实体都具有“出版时间”关系。说明本文模型能分辨出与问句有相同重叠词(高等数学、出版时间)的候选实体之间的差别。案例5,两个模型均接收正确指代“苹果”,问句涉及到背景知识“拉丁学名”,本文方法从22个候选实体中预测出话题实体“苹果”,方法 [5] 预测错误实体“苹果(蔷薇科苹果属果树)”。得益于问句和知识库信息,模型能识别出候选实体中4个包含关系“拉丁学名”的实体,同时得益于引入实体边界的池化和孪生网络,使模型能进一步区别这4个候选实体。
5. 结束语
本文提出了一个基于知识标记的预训练孪生神经网络实体链接模型,提出一种知识标记方法,在指代识别中融合实体边界信息。在实体消歧中融合了实体边界和知识库信息,通过孪生网络得到更好的匹配表示。实验证明,EKBERT是一个能有效解决未见实体指代和利用知识库区分相似候选实体的实体链接方法,并兼容流水线的知识库问答框架。在NLPCC 2016 CKBQA和CCKS 2019 EL数据集上达到并超过最好的方法。在未来,我们计划改进模型的规模和参数规模,并在更多中文数据集上评估,经一步提高模型的性能。
基金项目
广东省自然科学基金资助项目(2021A1515012556)。
参考文献