1. 引言
在改革开放的背景下,我国市场经济正在飞速发展,零售业的竞争也愈加激烈。各企业若想在众多企业中脱颖而出,需要做出相对准确的预测。好的预测不仅可以为企业解决存货堆积的麻烦,还可以为企业提供以后的需求走向,这样以便于进行物流准备以及人员排期等一些前期准备工作 [1]。以及为后期的生产和采购计划的制定提供可靠依据。
市场各销售行业销量的预测有着重要的研究价值和意义,近年来国内外学者对这些问题进行了深入的研究,目前常用的方法有时间序列分析 [2] [3] [4]、支持向量机 [5] [6]、神经网络等方法 [7] [8],以及将不同方法结合建立混合模型 [9]。但是不同模型针对不同的数据的特点各有优缺点,因此如何找到最适合零售行业销售数据的预测模型才是最令我们关心的问题。
欧洲的零售行业相对于我国的零售行业较为发达,其中最为发达的国家是德国。本文针对德国一大型超市的销售额数据,提出将聚类分析与XGBoost模型相结合的混合预测模型,通过与多元线性回归模型、随机森林回归模型、XGBoost回归模型对比,进一步得到对销售额预测最精准,泛化能力最好的模型,并可将其推广于中国零售业销售额数据的预测中,为零售企业提供辅助性的决策。
2. XGBoost算法
XGBoost (eXtreme Gradieni Boosting),是改进的梯度提升学习算法,是Boosting中的一种方法。XGBoost通过对损失函数进行二阶Taylor展开,在损失函数里增加正则项,用于控制模型的复杂度。GBDT (梯度决策树)算法是Boosting方法中的重要组成部分,其算法步骤为:
输入:训练数据集
;损失函数为:
。
1) 初始化弱学习器:
(1)
2) 对迭代轮数
有:
a) 对样本
计算负梯度:
(2)
b) 利用
,可以拟合一棵CART回归树,从而得到第t棵回归树,其对应的叶子节点区域为
,其中J为回归树t的叶子节点的个数。
c) 对上述叶子区域,计算最佳拟合值:
(3)
这样就得到了本轮的最优决策树拟合函数
。
d) 更新强学习器并得到其表达式:
(4)
XGBoost算法是在GBDT的基础上对算法进行以下优化。
在XGBoost模型进行对应t次迭代之后,得到:
(5)
此时,XGBoost的目标函数为:
(6)
其中
。将目标函数在
处进行二阶泰勒展开,
(7)
其中
(8)
去掉公式中的常数项后,可以得到:
(9)
加入正则项:
(10)
进一步可以转化为:
(11)
解出使目标函数最小的ω,从而可以得到目标函数的最优解。XGBoost算法学习出的模型更加简单,可以防止过拟合。
3. 数据分析
在对数据进行建模分析之前,都要对原始数据进行预处理,这一步是整体工作流程当中非常重要的一个环节。模型的预测是否准确很大程度上取决于训练预测模型时输入数据的质量,因此需要对原始数据进行探索性数据分析。对那些有价值的数据搭建特征工程,将数据转换为训练模型能够接受的数据形式,进一步地去训练预测模型。
3.1. 数据描述
本文所使用的数据来自Kaggle网站关于德国Rossmann零售超市销售额数据。数据包含1115家Rossmann连锁商店在2013年1月1日到2015年7月31日的销售数据。影响销售额的因素有很多,如商店是否促销,是否国家法定节假日,是否学校放假,最近竞争商店的距离,最近竞争商店开业的月份和年份,是否连续促销等因素。下面对数据集进行特征描述,见表1和表2。

Table 1. Characteristics of training set and test set
表1. 训练集、测试集特征
Table 2. Data characteristics of store information
表2. 商店信息数据特征
3.2. 特征工程
原始数据的所有属性都用于统计建模是不切实际的,必须根据模型要求和属性特征值进行特征工程构建。
具体的实现过程为:将Date日期单独分开,转换为Year、Month、Day、Week of Year;去掉没有价值的数据:去掉商店关闭时的数据和商店营业时销售额是0的数据;因为Sales的数额都太大,在数据拟合的过程中会造成很多不良的影响,所以对Sales进行取对数处理,即新增一个Saleslog特征;Store商店信息数据集里面的Competition Distance竞争者距离的空值用中位数填充;Store商店信息数据集里的空值用0来填充;合并商店信息数据集和训练集;State Holiday特征的取值有0、a、b、c,因为a、b、c在建立模型的时候不可以识别,所以将a、b、c做独热编码,同时Store Type特征的取值a、b、c、d和Assortment特征的取值a、b、c做一样的处理;Promo Interval特征的取值有三种,定义promo (函数),判断促销是否再进行。如果月份的英文简写在促销月份之内,意味着促销正在进行。
4. 模型建立
模型的建立包含以下基本流程,见图1:

Figure 1. Basic process of model building
图1. 模型构建的基本流程
1) 数据预处理:对原始数据进行一系列探索性分析,用探索性分析得出的结果对数据集进行预处理,其中包括异常值处理,空值填充,给特征工程提供数据。
2) 划分数据集:完成预处理后,把数据划分成训练集、测试集和验证集。
3) 特征工程:对训练集、测试集、验证集分别进行特征构建,生成相应的特征集,为接下来的构建模型做好准备。
4) 构建基本模型:分别选择线性回归模型、随机森林模型和XGBoost构建基本的销售额预测模型,同时对参数进行调优,通过调节一些关键参数的大小观察预测精度评价指标的变化,得到各模型的最优参数,建立基本的模型。
5) 模型优化及选择:对XGBoost进行改进及优化,对比各模型的预测结果,选出最佳预测效果的模型。
4.1. XGBoost模型
本文利用1115家Rossmann连锁商店在2013年1月1日到2015年7月31日的销售数据进行建模预测。其中将1,017,209个数据作为训练集,50个数据作为测试集。在实验中经过多次调试与测试,在权衡计算量与模型的综合得分后将XGBoost模型参数树的深度max_depth设置为5,树的棵树n_estimators 设置为20,其余参数都设置为默认参数。探索XGBoost模型对销售额的预测性能,其实验结果如图2所示。
XGBoost模型在预测中的RMSPE (均方根百分比误差)为0.0152,MAE (平均绝对误差)为0.1042。该模型的预测效果较好。图2中可以清楚地看到预测效果虽然在趋势上有所接近实际销售额趋势,但是总体上销售额的预测值和真实值还存在较大偏差,因此该模型还需要改进。
对每个特征的重要程度评价打分,如图3所示,从打分情况可以看出“Customers”和“Competition Distance”的特征得分比较高,排名靠前,即这两个特征对模型非常重要。
4.2. 建立混合模型
从图3特征重要度得分图中得出“Assortment”和“Store Type”这两特征的重要程度得分都很低,对预测销售额的贡献不大,在影响销售额的众多特征中不重要。而根据探索性数据分析可以知道,“Store Type”与“Customers”、“Sales”和人均消费数都有较直接的关联,这就说明单一的XGBoost回归模型在构建模型的时候会损失“Assortment”和“Store Type”这两个维度的信息,从而导致预测模型没有达到最优。
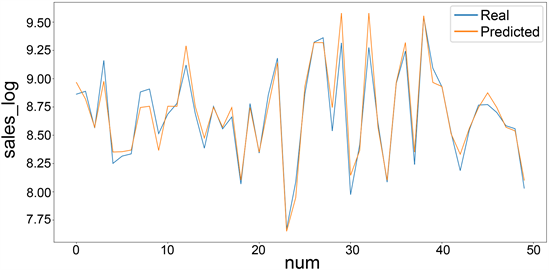
Figure 2. Sales forecast results of XGBoost model
图2. XGBoost模型销售额预测结果
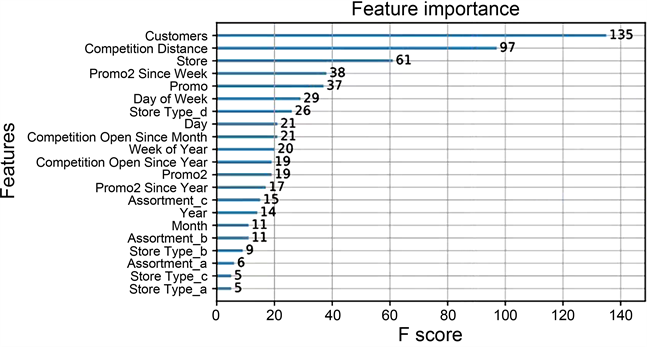
Figure 3. Significance score of features
图3. 特征重要度得分
大型的商店具有地理位置各异、商店规模各异、消费群体各异等特点,若构建单一的模型不可以满足所有商店的销售额预测需求,因此本节尝试构建一个基于聚类方法的混合回归模型,通过这个来解决单一模型造成信息损失的问题。
混合模型利用主成分分析(PCA)的方法进行降维,按照贡献率来选取比较合适的降维维数。使用K均值聚类方法对数据进行聚类处理。对每一类数据分别建立XGBoost回归模型,最后将通过加权求和得到预测结果。
首先利用主成分分析对数据集的特征进行降维,如表3所示。可以发现当主成分个数是3的时候,累计贡献率达到了0.99968912,因此提取3维特征矩阵来代替原来的特征矩阵。接下来进分别选择K = 2, 3, 4, 5, 6, 7的情况进行聚类,我们发现当K = 5时最合适。我们对聚类之后各类别的数据分别建立XGBoost模型,最终的预测结果见图4。从图中可以看到,大部分真实值和预测值之间的差距变小了,基于XGBoost算法的混合模型在预测中的RMSPE = 0.0682,MAE = 0.009,说明混合模型的拟合程度很高,模型的预测准确度也高,基本达到了对销售额预测的要求。
Table 3. Principal component contribution rate and cumulative contribution rate of all principal components
表3. 主成分贡献率及所有主成分累计贡献率
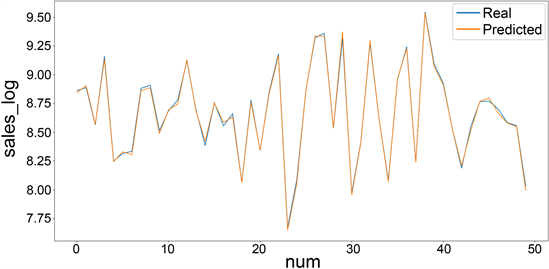
Figure 4. Prediction effect of mixed model
图4. 混合模型预测效果
表4分别给出三种基本模型和混合模型在预测精度上的比较。在三种单一的模型中,XGBoost模型在预测精度指标MAE、RMSPE中都是最小的,这说明XGBoost的拟合效果是最好的,预测是最精准的,因此选择XGBoost模型进一步建立混合模型。综合四种模型预测结果的对比,混合模型在两个精度评价指标上都是最小,表明混合模型的性能最好,精确度最高。
Table 4. Evaluation indexes of accuracy of different models
表4. 不同模型精度的评价指标
5. 结论
本文通过对德国Rossmann连锁商店的零售数据进行探索性分析,搭建特征工程,建立了XGBoost模型。为了优化模型,进一步建立了基于聚类分析和XGBoost算法的混合模型。通过将混合模型与三种单一模型在数据预测中的结果进行比较,我们发现混合模型进一步提高了预测的精度。本文所提出的模型不仅能应用在德国的零售企业中,也对我国的实体零售业以及线上电商平台的商品定价、运营方式都具有重要意义。
基金项目
国家级大学生创新创业训练计划项目(202111058036),宁波市自然科学基金(2021J144)。
参考文献