1. 引言
随着传感器技术、芯片技术和无人机平台的飞速发展,以激光扫描和倾斜摄影为代表性的点云采集变得越来越便捷。点云(X, Y, Z, A)也已经成为继矢量地图和影像数据之后的第三种重要的时空数据源,同时点云也是三维地理信息获取的主要来源和对三维空间的精细化描述具有不可替代的重要作用 [1] [2]。点云智能处理的理论和方法也引起了工业界和学术界越来越多的关注,特别是配准 [3] [4]、补全 [5]、分割 [6]、目标检测 [7] [8] 和三维重建 [9] 等领域。三维物理世界中的物体是由不同的几何基元组合构成的 [10],三维直线段则是几何基元的一个重要组成部分。它在许多点云处理中都起着至关重要的基础作用,如SLAM中的校正 [11] 和定位 [12],点云配准 [13] [14],三维重建 [15] [16] 等。目前主要有两种方法来提取三维直线段。第一种是基于多视图融合来提取三维直线段结构,这种方法主要是融合了一系列的RGB序列和深度图 [17] [18],或者将点云投影到二维,形成一系列的图像,通过提取这些图像中的二维直线段并反投影到三维来提取三维直线段 [19] [20]。这些方法可以充分利用现有的成熟算法来提取图像的直线段。然而,在2D-3D的转换往往存在着边缘信息的损失。第二种是直接从点云中提取边缘或直线段结构,这种方法一般利用局部特征将点区分为边界点和非边界点,并直接将边界点进一步链接成三维直线段 [21] [22]。然而由于大规模室外点云场景复杂度高、遮挡多、点密度不均等问题 [6] 很难计算出鲁棒性和描述能力强的表征点云边缘的局部特征。最近,深度学习也被用于提取三维直线段 [23] [24] [25] [26]。然而,基于学习的方法需要大量的综合训练样本,而这些样本从点云中手工提取又是非常耗时耗力的。
为了从大规模点云中稳健地提取直线段,本文提出了一种基于投影方式的方法。我们的方法的主要贡献有两点:
1) 所提出的方法融合了多尺度卷积神经网络输出的边缘图,充分提取了图像的边缘特征,减少点云在3D-2D转换中的边缘损失从而实现高效的直线段提取。
2) 提出了一种用于三维直线段的定量评价标准。同时标注了Semantic-3D公共数据集的真值直线段并提供给公众进一步使用,丰富了Semantic-3D数据集。
2. 方法
本文将点云投影到二维图像再基于图像提取三维直线段,所以第一步从点云中提取三维投影平面的准确性对精准地提取三维直线段很关键。本文为了使点云在3D-2D转换过程中使损失降到最低,利用最新的多尺度卷积神经网络定位投影图像的边缘。为此,本文重点围绕提取三维直线段的完整性和准确性,从投影平面区域的提取,3D-2D投影两个方面出发,提出了一种从大规模点云中提取三维线段的方法。该方法的流程图如图1所示,主要分为两个步骤,第一步是投影平面区域的提取,第二步是基于投影的三维直线段的提取。
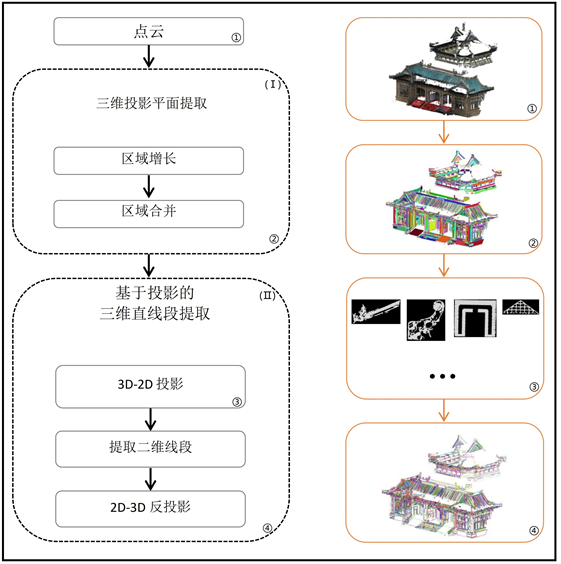
Figure 1. Pipeline of the proposed method
图1. 方法流程图
2.1. 三维投影平面区域的提取
本文首先是对输入点云提取三维投影平面区域,主要包括区域增长和区域合并。首先对输入点云建立kd-tree,计算每个点的曲率
和该点到第五近邻点的距离即scale。然后根据这两个性质对点云进行区域增长和区域合并。三维投影平面区域提取的流程见图2,区域增长的结果如图2(b)所示,算法如下所示:
1) 对于点云
中的每个点,按照
的大小进行升序排列。
2) 从排序后
中的未处理的第一个点
开始,我们令
存储与
共面的所有点,令
为
增长的种子点集合。将
点加入到
和
成为第一个点。
3) 遍历
,对于
一个未处理的点
,遍历
所有的近邻点
。如果
满足公式(1)所列的两个条件,则将
加入到
中且将
从
剔除,其中公式(1)的两个条件是为了保证
和
共面。如果公式
还满足公式(2)所列的两个条件,则
加入种子点集合
。该公式第一个条件是保证的种子点的曲率小于某个阈值,第二个条件保证
与种子点的距离小于某个阈值。
(1)
其中
、
分别为
和
的法向量,
,
、
分别为
和
的scale。
为固定值即为
,
。
(2)
其中
为
点的曲率,
当前
中第30%个点的曲率。
为
点与
点的距离,
。
4) 重复第2)、3)步,直至
为空。
5) 对于每个区域
,如果该区域内点的个数小于20,则舍弃该区域。该区域的点则将属于另一个区域
,而
是包含该点的领域点最多的区域。
在区域增长后进行区域合并,结果如图2(c)所示,算法如下:
1) 首先将区域增长得到的区域集合
中的每个区域进行PCA拟合,得到每个区域的法向量、曲率(
)、scale。
2) 给每个区域编号,然后根据其以下规则,找出每个区域对应的相邻的区域,令这个相邻的区域集合为
。规则:对于区域
上的每个点
,遍历
的领域
中所有的点p,若p点所在的区域不是
,则p点所在的区域
就是
的相邻区域,将
加入
。
3) 对于
中第一个未处理的
,
标记为处理地。我们令
为准备和
合并的区域的集合,并将
加入
。遍历该
中所有的区域
,对于
的所有的相邻区域
。如果满足公式(3)中的两个条件则将该相邻区域
加入到
。遍历完
中所有的区域之后,如果
中的点的个数小于100,则舍弃这次合并,否则保留并且从
剔除
中的所有的区域。
4) 重复步骤3),直至
中所有的区域都被标记为处理地。
(3)
其中,
,
分别为区域
和
的质心,而
,
分别为区域
和
的法向量。
,
、
分别为区域
和
的scale,其中平面的scale为该平面区域内所有点的scale的平均值。
为固定值即为
,
。
 (a)
(a)  (b)
(b)  (c)
(c)
Figure 2. Extraction of 3D projection plane (a) Original point clouds; (b) Results of region growth; (c) Results of region merging
图2. 三维投影平面的提取(a) 原始点云;(b) 区域增长的结果;(c) 区域合并的结果
2.2. 基于投影的三维直线段的提取
如图3所示,对于一个三维投影平面区域,我们需要将其上的共面点投影到二维投影平面上,然后再将二维投影平面上的点的坐标转化为图像坐标系下的坐标,从而形成图像。图3展示了投影过程,其
中橙色点表示三维投影平面上的共面点,其中假设某点为
,则该点按公式(4)投影到二维平面中的点为
,然后按公式(5)转化为图像坐标系下像素坐标
。最后将此点的像素值赋
予255,同时将非投影点的像素值赋予0。
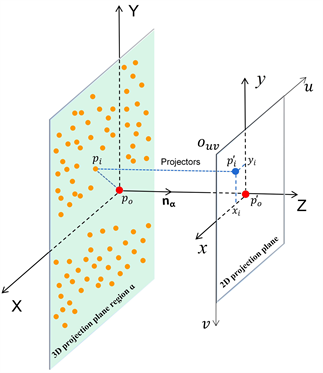
Figure 3. Schematic diagram of 3D-2D projection
图3. 3D-2D投影过程示意图
(4)
(5)
其中,公式(4)中的
为三维投影平面区域中所有质点在原始坐标系下的坐标。其中公式(5)
中的
、
分别为所有投影点在投影平面x轴、y轴的最大坐标值,其中
为所有三维投影点scale的平均值。
得到投影图像后,我们按图4的流程去获取三维直线段。我们利用带有预训练模型的卷积神经网络DexiNed [27] 来定位前面得到的投影图像中的边缘,得到所有的边缘图如图5所示。从图5可以看出,Fused边缘图的效果最好,基本上提出了人眼可以识别的薄边缘。下一步,我们将利用MCMLSD算法 [28] 从Fused边缘图中提取直线段。最后,根据公式(5)和(4)将二维直线段进行2D-3D反投影,从而获得三维直线段。
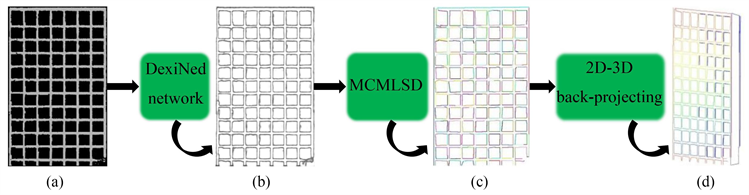
Figure 4. Pipeline and results of 3D line segments extraction based on the projection image (a) Projection image; (b) Fused edge-map; (c) 2D line segments; (d) 3D line segments
图4. 基于投影图像三维直线段的提取流程 (a) 投影图像;(b) 边缘图;(c) 二维直线段;(d) 三维直线段


Figure 5. Edge-maps of the projection image
图5. 投影图像的边缘图
3. 实验结果与分析
3.1. 实验数据集和评价指标
如图6所示,为了评估我们的算法,本文选取了公开数据集Semantic3D1几个有代表意义的点云场景作为实验数据。实验数据描述见表1,表1前五列描述了实验数据来源、实验数据名称、实验数据包含的点数、平均点密度和从这些场景中手动勾选的直线段Ground-truth数。考虑到人工标注的工作量大和难度大,我们选择了Semantic3D的bildstein1的主要结构用于手动直线段标注。

Table 1. Experiment data and results description
表1. 实验数据和结果描述
 (a) StSulpice
(a) StSulpice  (b) Bildstein1
(b) Bildstein1  (c) Bildstein3
(c) Bildstein3
Figure 6. Experimental data
图6. 实验数据
我们设计了两个准则来对真值直线段和算法提取的直线段进行相似性的度量。这两个准则分别是有效长度比(
)和平均最短距离(
),计算示意如图7所示,计算公式分别为公式(6)和公式(7)。
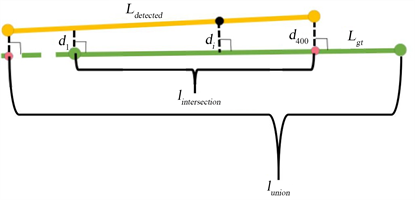
Figure 7. The schematic diagram of calculating two similarity criteria
图7. 计算两个相似性度量的示意图
1)
定义为提取的直线段在相对应的真值直线段上的有效长度比,即提取的直线段投影到真值直线段上与真值直线段的交集长度除以并集长度。
(6)
2)
定义为平均最短距离,即提取的直线段投影到相对应的真值直线段上时,提取的直线段对应的投影相交区域上的采样点到真值直线段的最短距离的平均值。
(7)
图7中的黄线
和绿线
分别代表提取的直线段和相对应的真值直线段。我们在计算
时在
上均匀地选取点。N是
投影到相对应的
上时,
上对应的投影相交区域上的采样点的个数,本文设置为400。如图7所示,
是提取的直线段上的点到对应的真值直线段的最短距离。如果
大于3 m,则这个采样点不参与计算。
如果提取到的直线段的
大于特定阈值而
小于特定阈值,则认为该直线段为真值直线段。然后我们使用完成率(Completeness)和准确率(Correctness)来评估我们算法的性能。Completeness (Comp)表明真值直线段有多少直线段被检测到了,Correctness (Corr)表示提取到的直线段有多少是正确的。计算公式见公式(8),
是提取到的为真值直线段的直线段数,
是真值直线段总数,
是提取到的直线段总数。
(8)
3.2. 实验结果与精度评价
三份点云场景提取的点云直线段数和所需时间分别如表1第六、七列所示,提取的直线段如图8、图9(c)。图8(a)、图8(b)可以直观地看到,本文方法可以提取建筑物中的绝大多数重要的直线段。如图8(c)、图8(d)中的黄色框中所示,对于曲线或者曲面,本文尽可能地用短直线段去拟合它们。
 (a)
(a) 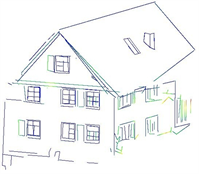 (b)
(b)  (c)
(c)  (d)
(d)
Figure 8. Point clouds and extracted line segments (a) (b) bildstein3; (c) (d) StSulpice
图8. 点云和提取的直线段(a) (b) bildstein3;(c) (d) StSulpice
本文选取了bildstein1与Lu等 [20] 中的方法进行定量对比分析。通过Lu等和本文中的方法提取的直线段分别如图9中的(b)和(c)所示。如图9(d)所示,我们对该场景进行了人工勾线,一共大概勾出了1903条直线段,将这些直线段作为定量评价的真值。
 (a)
(a)  (b)
(b)  (c)
(c)  (d)
(d)
Figure 9. (a) Bildstein1 (b) Line segments by methods of Lu et al. [20] (c) Line segments by methods in the proposed method (d) Line segments manually extracted
图9. (a) Bildstein1 (b) Lu等 [20] 的方法提取的直线段 (c) 本文方法提取的直线段 (d) 手动提取的真值直线段
按照3.1节的定义,当
以步频为−0.2%从100%逐渐变为0和
以步频为0.002 m从0.0 m逐渐变为1.0米时,我们画出了bildstein1中的评价指标Comp和Corr的变化曲线。对于Lu等 [20] 中的方法和本文提出的方法,Comp和Corr的变化曲线分别如图10中的实线和虚线所示。如表2所示,当
和
选择五个特定的和阈值时,我们计算了Lu等中的方法和我们的方法提取直线段时的Comp和Corr。当
且
时,我们方法提取的直线段的Comp和Corr分别可以达到0.85和0.80。而在同样的条件下,Lu等中的方法提取的直线段的Comp和Corr分别只能达到0.57和0.51。而且,当
减少和
增加时,我们的方法提取直线段的Comp和Corr比Lu等中的方法更快地接近1。

Figure 10.
curves
图10.
曲线
4. 结论
由于室外大场景点云存在遮挡多、点密度差异大、场景复杂等问题,从此类点云中提取直线段是一项具有挑战性的工作。本文充分利用目前在二维图像中提取直线段的成熟算法,提出了一种稳健高效地基于投影方式的提取大场景点云中直线段的方法。我们从Semantic 3D公共数据集中选取三个大型户外场景的点云进行实验。与人工标注的真值直线段相比,提取结果完成率和准确率平均达到83% (
: 0.5, 0.5),且平均处理速度为每秒27,000点。与最新的直线段提取算法(Lu等 [20] )相比,本方法过滤掉了主要的杂断线,提取了更完整的直线段。
基金项目
1) 国家自然科学基金面上基金资助,基金编号:42071451;2) 武汉大学知卓时空智能研究基金资助。
NOTES
*通讯作者。
1 http://www.semantic3d.net。