1. 引言
苹果是全球水果产品市场上被广泛选择的水果之一。因富含抗血酸及多酚类化合物等抗氧化成分,可对多种退化性疾病起到预防作用 [1]。消费者也同时需要口感和质量更好的水果以满足日益增加的需求。因此,对每个水果进行分类和分级,确保其内部质量很有必要性 [2]。苹果的可溶性固形物含量(Soluble Solids Content, SSC),又称可溶性糖类,涵盖单糖、双糖、多糖 [3],作为主要参数评价苹果的内部品质。传统的破坏性检测方法需要大量的时间和人力,可见–近红外光谱分析技术具备更简单、更快速、更准确的优势被广泛应用于无损评估产品的SSC含量,在水果内部质量分类和分级中展现出巨大的潜力 [4]。国外对SSC含量检测的研究起步时间较早。1998年,Lammertyn等人通过380 nm到1650 nm波长的红外射线完成了苹果的SSC含量检测,相干系数达到0.9 [5]。Salguero-Chaparro L等(2014)基于近红外光谱技术对橄揽果内部指标实现了在线捡测,表明将近红外光谱检测技术应用在橄揽油加工生产具备可行性 [6]。国内方面。2006年,刘燕德通过近红外光谱对水果糖度及酸度实现无损检测,测试了水果在不同的测试位置、测量距离等因素对模型效果的影响 [7]。郭志明(2015)釆用自建的苹果在线检测装置,获取苹果的漫反射光谱后通过算法对模型优化开发了准确性较高的短波近红外苹果糖度在线检测装置 [8]。
受到果实生长期土壤、天气、光效等不同条件的影响,光学传输特性由于物化特性的不同产生改变 [9] [10]。樊书祥等对4个不同产地的苹果建立了混合检测模型,得出不同产地通用模型对于提高总体预测模型稳定性方面具有较好的成效 [11]。Li X测定了三产地苹果SSC值,预测结果表明,通过原产地判别方法的多产地苹果SSC模型可减少原产地对结果的影响 [12]。现有研究中,多是探究不同产地或品种与单一产地的结果对比,对于如何提高不同产地的苹果SSC检测通用模型精度及效率报道较少。因此,本研究通过预处理方法减少光谱差异,基于随机森林算法建立非线性模型,提升多产地苹果糖度通用模型预测效果及模型稳定性。研究结果对苹果糖度检测在实际应用中具备生产价值和借鉴意义。
2. 理论部分
2.1. 可见–近红外光谱分析技术
可见–近红外光谱分析技术的研究进展迅速,以非破坏性检测方式为衡量待测品内在品质提供了方法 [13],其原理是具有近红外吸收的物质分子被近红外光通过时会吸收不同的能量,导致不同能级间产生跃迁,通过各谐振子间互相激发,致使近红外区域产生吸收光谱。在该研究中,水果组织内部O-H,C-H及N-H等化学键倍频与伸缩振动等和近红外光谱吸收特性紧密相关。水果随着自身生长期或贮存期的变化,其中糖含量会随之改变导致组织结构对光吸收或散射的变化。光照射于水果表面时,光被反射、吸收以及散射 [14],散射光随水果内部属性变化的规律被应用于水果的内部品质无损检测研究。
2.2. 漫反射原理
当一束漫反射光进入水果内部会发生吸收以及多次反射、折射等现象,返回而出的光承载了样品的光谱信息。相比其他采集方式,漫反射光更能反映水果的组织结构特点和内部成分特性。因此,漫反射采集方式被广泛应用在大部分水果内部品质无损检测研究中 [15]。
Kubelka-Munk函数为漫反射检测方法的光谱进行定量分析,其表达式为:
(1)
上述表达式中,漫反射体的内部化学组分通过漫反射体吸收系数K表示;散射系数表示为S,通过漫反射体的外部物理特征确定。K/S的函数用来表达待测物的绝对漫反射率,表示出射光与入射光的比值。
因此相对漫反射率为:
(2)
漫反射分析中,上式的
与样品的组分浓度并不构成线性关系,与其构成线性关系的函数为反射吸光度 [16]。
漫反射吸光度A表达式为:
(3)
通过可见–近红外漫反射光谱转化为吸光度可与物质的成份或内部性质建立关联,从而建立相应的关联模型。
2.3. 随机森林算法
随机森林算法(Random Forest)在机器学习中成为被广泛选择且应用的算法之一。其以简单、灵活的特点应用于分类和回归任务。它构建的“森林”是决策树的集合。决策树的形状为树状结构,其中内部的一个节点表达一个测试属性;一个分支表达一个测试输出;一个叶节点则表达一个类别。随机森林通过集成学习的思想,以决策树为基本单元,在构建过程中遵循样本抽样随机有放回和特征随机对预测结果进行投票,最后根据决策树模型的平均值来获取最终结果。判断随机森林模型结果优劣的指标主要受到训练样本个数、样本变量、决策树预测能力以及各决策树之间相关性的影响 [17]。相关系数(R2)、校正均方根误差(RMSEC)和预测均方根误差(RMSEP)作为模型的评价指标,决定了模型效果优劣。
决定系数:
(4)
校正均方根误差:
(5)
预测均方根误差:
(6)
校正集相关系数、均方根误差用来评价水果糖度和光谱数据之间的校正关系;预测集相关系数、均方根误差可以判断模型的预测效果。当模型的相关系数越接近1时,证明其自变量对因变量的解释程度越高,模型拟合效果越佳;校正均方根误差越小则证明模型回归性强,样本相关性紧密;预测均方根越小,则表明模型预测能力强,二者越相近,模型的泛化能力越稳固。
3. 实验部分
3.1. 实验样品
实验样品为同一日期购自相同超市的山东富士、陕西富士、新疆阿克苏各12个,共计36个样品。人工挑选体型相近、表面无明显伤痕瑕疵作为样品。使用毛巾对每个样品表面进行擦拭清洁。每个水果根据种类依次进行编号标记,在垂直于茎轴的赤道位置每间隔120˚标记取样点。实验前将所有样品在实验室静置24 H,使其接近实验室室温、湿度,做等温处理。
3.2. 实验系统搭建
基于漫反射采集原理搭建了试验检测系统,如图1所示为漫反射检测系统图。采用溴钨灯作为试验光源,光源出光口与光纤探头紧贴样品表面且相距3 cm。入射光通过样品表面,将光信息传递到实验水果样本的表面上,漫反射出射光将携载着实验对象样本的内部结构和信息传递回光纤探头;最终,漫反射光承载光谱信息,传递到光谱仪后的光谱数据保存在实验计算机中。
采集前,实验设备需要预热15 min,保证平稳运行。采用SpectraSuite光谱采集软件,积分时间设置1 s,平均次数为3,对每个采集点依次进行光谱采集,共采集108组光谱数据。
3.3. 理化值测定
光谱采集后,通过糖度折光仪实现样品的糖度值测定。糖度计根据光的折射原理可以准确地测出溶液中的含糖量。具体的操作方法是:穿戴一次性手套,在之前标记的光谱采集点,用刀取等量苹果果肉,并用手压捏出果汁,滴在折光仪的棱镜表面中央约2~3滴,迅速合上棱镜盖后静待10秒钟,调节目镜使刻度线清晰并读取实际糖分值。对每个样品的采集点重复采集读数三次,取平均值后作为对应测量样品的真实糖度值。
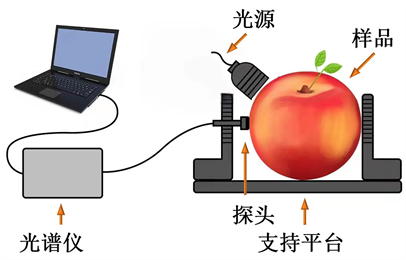
Figure 1. Diffuse reflection experimental system diagram
图1. 漫反射实验系统图
3.4. 光谱预处理方法
在对漫反射光谱的分析过程中,经常会受到样品、仪器或其它因素的影响,出现基线倾移之类的现象。研究分别采用一阶导数、多元散射校正、S-G卷积平滑、标准正态变换四种方法作为光谱数据的预处理方式,优选出最佳预处理方法应用于后续模型建立。
4. 结果与讨论
4.1. 样本理化值统计
样本集SSC结果统计见下表1,其中SSC的范围在10.2˚Brix~15.2˚Brix之间,标准差为1.01˚Brix。样本范围较大,有利于构建模型。

Table 1. System resulting data of standard experiment
表1. 标准试验系统结果数据
4.2. 样本漫反射光谱响应特征
由于光谱两端主要为无效信息且包含较大噪声。后续研究选择650~900 nm波段进行探究分析。样本光谱图如图2所示。三种苹果的光谱曲线有很明显的吸收特性且总体趋势相似性较高。其中造成波长675 nm处光谱吸光度强度变化的原因可能为果肉细胞中叶绿素和类胡萝卜素对光谱的吸收 [18],与样本的表皮颜色差异和不同成熟期样品内部的成分差异相关。740附近的吸收峰可能与O-H键的三级倍频和C-H键的四级倍频伸缩振动存在关联 [19]。近红外波长下的光谱吸收大多数与C-H和O-H化学键的吸收相关,而这些化学键又是组成水分、可溶性糖、纤维素和果胶等物质的基础形式。840 nm附近的较弱波峰与N-H三级倍频伸缩振动相关。它们作为基础化学键构成有机化学物。
4.3. 样品光谱预处理
试验选用了一阶导数(1st)、S-G卷积平滑、标准正态变换(SNV)及多元散射校正(MSC)四种方法分别对原始光谱数据进行预处理,从而消除光谱数据中基线和噪声等因素对光谱的扰乱,获取信噪比较高的光谱数据,对于提高预测模型的稳定性具有很大的帮助作用。苹果样本经过1st (a)、S-G卷积平滑(b)、SNV (c)和MSC (d)预处理后的平均光谱吸光度曲线如图3。
4.4. 模型建立
在建立检测模型前,采用随机法对实验样本按2:1的比例分成校正集和预测集。其中校正集用来建造校正模型,预测集评定校正模型的决定参数。
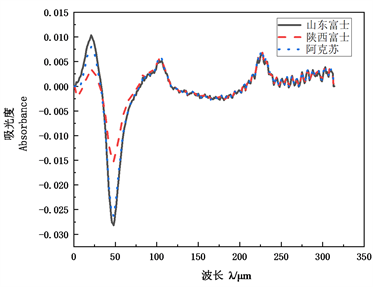 (a) 一阶导数平均光谱
(a) 一阶导数平均光谱  (b) S-G卷积平滑平均光谱
(b) S-G卷积平滑平均光谱  (c) 标准正态变换平均光谱
(c) 标准正态变换平均光谱 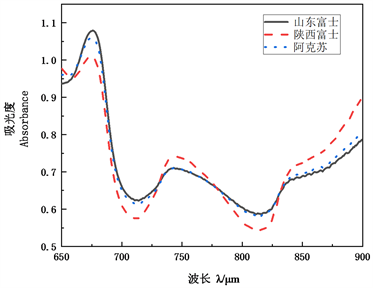 (d) 多元散射校正平均光谱
(d) 多元散射校正平均光谱
Figure 3. The average spectrum of the sample after pretreatment
图3. 经过预处理后的样品平均光谱
4.4.1
. 偏最小二乘法建模
采用原始光谱数据与分别经过4种预处理方法后的光谱数据分别结合偏最小二乘法(PLS)建模。最终结果如表2所示。
Table 2. PLS model evaluation index
表2. PLS模型评价指标
由表2可知采用PLS结合不同预处理方法对苹果通用糖度检测模型的评价指标。观察得出采用一阶求导法与未经预处理光谱的模型评价指标较为接近;经S-G卷积平滑的光谱模型指标略优于未处理光谱检测模型;采用多元散射法建立的光谱模型相比下效果不佳。比较可知,采用标准正态变换结合PLS检测模型效果最好。因此,本次试验经比较后采用标准正态变换(SNV)用于PLS建模分析及后续的随机森林算法建模分析。图4为SNV-PLS预测模型中苹果SSC值的预测散点图,可以看出,预测值集中在目标线附近,预测效果较好。
4.4.2. 随机森林法建模
通过标准正态变换(SNV)处理后的光谱结合随机森林算法建立苹果糖度检测通用模型。与PLS模型采用相同的样本数据。表3为采用SNV预处理结合随机森林算法苹果通用模型的评价指标。图5中,预测模型的SSC预测值散点集中于目标线附近,偏差很小。
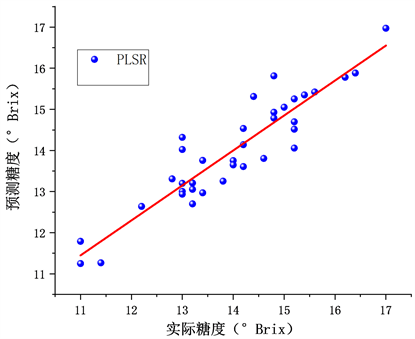
Figure 4. PLS model prediction set sample results
图4. PLS模型预测集样本结果
Table 3. RF model evaluation index
表3. RF模型评价指标
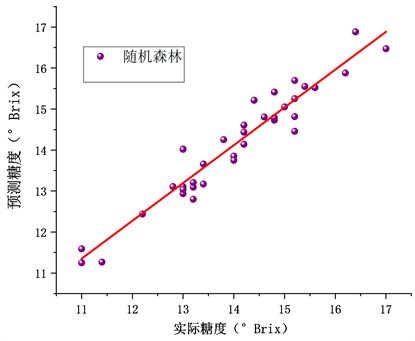
Figure 5. RF model prediction set sample results
图5. RF模型预测集样本结果
5. 结论
本研究基于可见–近红外光谱分析技术,利用随机森林算法,通过漫反射采集方式采集了三种不同产地苹果的光谱数据,经过四种光谱预处理方法分别结合PLS建立糖度检测模型比较后,采用效果最佳的标准正态变换(SNV)结合随机森林回归算法建立了不同产地苹果的糖度检测通用模型,并与利用偏最小二乘算法的糖度通用模型做出比较。实验结果表示,采用随机森林算法构建的通用模型校正集的相关系数与校正均方根误差分别为0.91和0.41,预测集相关系数和预测均方根误差分别为0.89和0.44;结合偏最小二乘法建立的通用模型其校正集相关系数与校正均方根误差为0.87和0.42,预测集相关系数、预测均方根误差分别为0.85、0.47。结论表明,采用SNV预处理方法结合随机森林算法建立的通用检测模型在预测不同产地苹果糖度时,预测精度相对偏最小二乘法有较大提升,有效减小了由产地不同引起的光谱差异。同时表明预测精度在受到生物多样性变化时有较好的适应性及准确性,使得预测模型面对未知变化更加稳定。实验结果表明随机森林算法通用模型对3种产地苹果糖度具有出色的预测能力,试验结论与研究方法对今后的水果糖度检测通用模型研究具有参考价值,可缩减不同产地苹果糖度检测模型建造过程中的模型维护成本,为水果采摘后的分选等商品化处理具有参考价值。
基金项目
吉林省自然科学基金项目(20200201257JC, 2020)。
NOTES
*通讯作者。