1. 引言
受疫情过后国际上各国经济持续复苏、全球石油和天然气供需紧张,石油和天然气价格大幅上涨。国内电力和煤炭供需矛盾持续紧张,国家“能耗双控”政策的实行,由于各种因素的叠加,“拉闸限电”现象在我国一些地方持续出现。实现“双碳”目标是一项十分复杂的系统工程,需要在产业结构、技术革新以及配套设施方面进行一系列的变革,不能仅仅依靠简单的拉闸限电。“拉闸限电”现象对我国的电力供应状况敲响了警钟,电力供应安全已经到了刻不容缓的地步,不能因为“低碳”目标而放弃基本经济的发展。在“双碳”目标下,预测社会总用电量,针对性的采取措施调整供电量是实现该目标的关键。
社会用电消费占据我国能源消费总量的80%。能够准确预测全社会用电量对实现能源安全和低碳经济具有重要意义。我国全社会的用电量受到多种因素的共同影响,能否合理选择预测模型是提高预测精度的关键。传统的全社会用电量的预测往往采用单一的ARIMA模型和指数平滑模型进行预测,部分预测方法忽略了季节性变动的影响,因此,本文将季节ARIMA模型和三参数指数平滑模型进行对比预测,将原始数据分为训练集和测试集,通过对比两种预测方法的预测值和测试集的误差,选择出最优的我国全社会用电量预测模型。
2. 文献综述
时间序列分析能够反映事物发展变化的数量和关系,揭示事物随时间演化的趋势和规律。这是统计理解事物动态发展的常用方法。该方法已广泛应用于经济、生物、工程、自然科学、环境卫生、商业等领域。该方法主要包括趋势外推法、指数平滑法、灰色预测法、box-Jenkins法和构建组合模型。
电力作为重要的能源资源,是保障全社会经济活动的重要支撑。然而,能源短缺问题日益突出,逐步突出了电力供应稳定的重要性。而科学合理地预测全社会中长期用电量是实现供电稳定的关键,通过梳理国内外相关文献发现,预测社会用电量的方法大致可以分为:传统预测方法和现代预测方法两大类。
国内外学术界在传统的电力预测方法的研究中,应用最广泛的方法是时间序列法,部分学者根据电力消费的影响采用回归分析法进行预测。时间序列分析主要依赖的是历史数据,采用合适的模型拟合原始历史数据具有的趋势性,季节性,波动性特征,进而根据历史数据对未来的趋势进行预测。回归分析法是统计学常用的一种分析方法,主要用于确定解释变量和被解释变量之间的关系,通过计算一个或多个自变量的因变量值来确定预测用电量。郭松亮、闫鹏君、鄂浩坤采用ARIMA模型,根据北京市1978~2018年的全社会用电量历史数据,进行了短期的用电量预测,其拟合效果较优 [1];贾朝勇、潘玉荣、夏福全以1990年~2016年广州市全社会总用电量数据为样本,采用enviews软件进行预测 [2];王彦博(2010)基于传统的时间序列分解和回归分析,采用STL分解模型对我国全社会的月用电量进行了综合的预测 [3];任芳玲、李文波、贺甜采用优化多元线性回归模型和灰色模型对陕西省年社会用电量进行了预测,预测效果较之传统的预测模型有了明显的改善 [4]。
现代预测方法是随着计算机的逐步发展而产生的,由于其强大的性能,对于非线性数据的处理具有明显的优势。其主要预测方法包括神经网络、灰色系统预测等。缪庆庆,林涛等(2020)以我国12个月的社会用电量为样本,提出了一种基于BP神经网络的家庭用电量预测模型,结果表明,其预测准确率达到了90.8%,模型的预测精度得到了显著的提高 [5];毛锦伟、梁甲、张修文(2020)针对全社会用电总量的预测,提出了一种基于SOM-RBF的神经网络的新方法。结果表明,平均相对误差在合理的误差范围之内,该预测精度要远高于传统的BP神经网络,极大地提高了模型的预测精度 [6]。
通过文献梳理可以发现国内外学者在对用电量的预测方法研究中,产生了众多的成果。传统预测和现代预测的方法在各自领域都有其适用条件和局限性,但目前应用最为普遍、发展相对成熟的是时间序列法。因此本文采用传统的季节ARIMA模型和Holt-Winters三参数指数平滑对我国全社会用电总量进行比较预测分析。
3. 理论方法介绍
3.1. 季节ARIMA模型
ARIMA模型是在平稳ARMA模型的基础上演变而来,社会生活中的数据往往具有非平稳的特征,通过对该非平稳序列进行差分后,显示出平稳的特征,则称该序列为差分平稳序列,基于这种数据,可以使用ARIMA模型进行拟合,ARIMA模型也称为自回归移动平均模型,简记为ARIMA(p,d,q),该模型
具有以下基本结构:
式中,
,为平稳可逆ARMA(p,q)模型的自回归系数多项式;
,为平稳可逆ARMA(p,q)模型的移动平均系数多项式 [7]。
季节ARIMA模型的基本原理是在ARIMA模型基础上提取季节效应进行建模,本文主要用的是ARIMA加法模型,在本章主要对ARIMA模型进行介绍。
加法季节ARIMA模型因其建模方便、准确、快捷,是季节ARIMA模型较为常用的一种模型,加法季节ARIMA模型的原理是将该序列的总效应分解为季节效应、长期趋势效应、随机波动效应,三者之间以累加的形式共同反映总体模型的趋势,即
,式中,St为季节效应,Tt为长期趋势效应,It为随机波动效应。提取完季节效应和趋势效应的残差序列为平稳序列,可以通过ARMA模型进行拟合。模型基本结构如下所示:
其中,D称为周期步长,d就是传统的差分,大多数数据进行一阶、二阶差分即可平稳,
为白噪声序列,且
,
,
;
,为q阶移动平均系数多项式;
,为p阶自回归系数多项式 [7]。
3.2. Holt-Winters三参数指数平滑
指数平滑法的基本思想就是加权,其预测结果严重依赖于历史数据,通过对历史数据赋予不同的权重,由于时间序列数据具有时滞性,距离预测值距离越近的数据对其影响越大,因此对距离越近的历史数据赋予较大的权重,距离预测值数据较远的历史数据,对预测值的影响有限,因此对其赋予较小的权重,通过这种对不同的历史数据赋权的方法,对未来的预测值进行加权估计。
在时间序列的分析过程中,对未来的预测往往是采用现有的时间序列数据预测。三次指数平滑在预测时间序列时,因其简单、实用、精确度高受到了广泛应用。其基本形式为:
其中α是平滑参数,Si是之前i个数据的平滑值,取值为[0,1],α越接近0,平滑后的值越接近前i个数据的平滑值,数据越平滑。
一次指数平滑算法是指数平滑法的最简单应用,其基本公式为:
,其中i代表时间轴上的第i个数据,该算法不能反映时间序列的趋势和季节性。
二次指数平滑是在一次指数平滑算法的基础上增加了趋势的信息,其基本形式为:
二次指数平滑的预测公式为
二次指数平滑的预测结果带有明显的趋势信息,其图像往往是一条带有斜率的直线。
三次指数平滑是指数平滑方法的最终效果,该算法保留了趋势效应,季节效应,其加法模型的基本形式为。(本章主要使用的指数平滑加法模型)
其中k为周期累加三次指数平滑的预测公式为:
。
4. 实证分析
4.1. 数据来源及趋势分析
本文以我国社会总用电量作为研究对象,数据选用我国社会总用电量2010年1月~2019年12月的月度数据,用变量Xt表示,数据来源于中国煤炭数据库。
绘制我国社会总用电量2010年1月~2019年12月的月度数据的时序图(见图1),通过时序图可以看出我国社会总用电量数据序列具有明显向上增长的趋势以及季节的波动。从图1可以看出每年的一季度和三季度达到总用电量达到高峰,根据该序列的季节性特征,本文选取季节波动周期为一年。

Figure 1. Sequence diagram of total social electricity consumption in China
图1. 我国社会总用电量序列图
4.2. ARIMA模型的预测
4.2.1. 数据分析
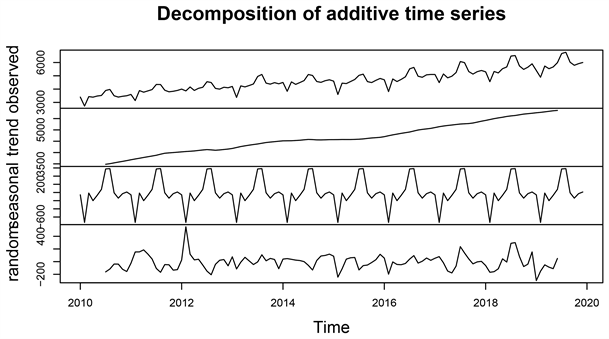
Figure 2. Decomposition diagram of power consumption factors of the whole society
图2. 全社会用电量因素分解图
由图2全社会用电量因素分解图可得出,该序列为非平稳序列,社会总用电量具有逐步递增的趋势,具有周期为12的季节性趋势。自改革开放以来,我国经济获得了突飞猛进的发展,电力作为整个经济系统中最为重要的部门,用电量也逐步增加,从时序图可以看出,我国用电量在第三季度的用电量最高,符合我国现实情况,第三季度的九月、十月份是我国各行业的销售旺季,进而对电力的消耗也逐步增加,根据原始序列具有的逐步递增的趋势效应和12期为周期的季节效应的特征,因此对该序列进行1阶12步差分,差分后的序列时序图(见图3),显示差分后的序列已经不再有明显的趋势和季节性特征,因此认定该序列具有平稳的特征ADF结果显示(见表1)无截距无趋势、有截距无趋势、有截距有趋势三种情况的ADF的P值均小于显著性水平0.05,证明该序列经过差分后变的平稳,白噪声检验显示(见表2),滞后6阶,12阶的P值均小于显著性水平0.05,证明差分后的序列为非纯随机序列,即我国全社会用电量差分后的序列为平稳非白噪声序列,有必要对其进行进一步的拟合分析。

Figure 3. Sequence diagram after power consumption difference of the whole society
图3. 我国全社会用电量差分后序列时序图

Table 1. ADF value of whole society’s power consumption after differential sequence
表1. 我国全社会用电量差分后序列的ADF值
Table 2. Pure randomness test results of power consumption difference series in China
表2. 我国全社会用电量差分后序列的纯随机性检验结果
4.2.2. 拟合模型
差分后序列的自相关图和偏自相关图(见图4)显示,自相关图2阶截尾,而偏自相关图3阶截尾,可以拟合模型ARIMA(3,1,0)、ARIMA(0,1,2)、ARIMA(3,1,2)。
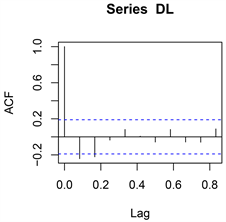
Figure 4. Sequence autocorrelation diagram and partial autocorrelation diagram after power consumption difference in China
图4. 我国全社会用电量差分后序列自相关图和偏自相关图
根据AIC最小原则,选择拟合ARIMA(3,1,2)模型,使用条件最小二乘估计和极大似然混合估计方法,得到该模型为:
(式1)
接着对ARIMA(3,1,2)模型进行显著性检验,检验结果显示(如图5所示),该残差序列为白噪声序列,说明该序列拟合效果良好,对序列的信息提取充分,ARIMA(3,1,2)模型显著成立。

Figure 5. Significance test of sequence fitting model after difference of power consumption in China
图5. 我国全社会用电量差分后序列拟合模型显著性检验
4.2.3. 模型的预测
以2010年1月~2018年12月数据为训练集,以2019年1月~12月的数据作为测试集,根据上述得到的拟合模型(式1),对2019年后的数据进行预测,之后用实际值与预测得到的拟合值进行比较,并且
设定误差公式为:
,其中test代表真实值,fore代表预测值。
Table 3. Prediction results of power consumption of the whole society from January to December 2019
表3. 2019年1月~12月全社会用电量预测结果
从表3中可以看出,只有一月和五月的误差超过了0.05,拟合效果欠佳,其余月份的预测效果在0.05以下,2019的平均误差为0.0315013,拟合效果比较准确,因此可以说明该模型用于拟合我国全社会用电量数据的合理性。图6展示的是我国全社会用电量预测效果图,预测效果图显示,预测值基本延续了原序列的发展趋势,季节ARIMA模型拟合效果较优。
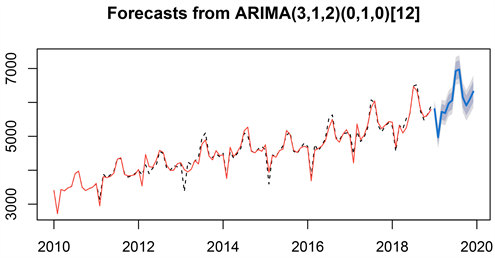
Figure 6. Effect chart of differential sequence prediction of power consumption in China (seasonal ARIMA)
图6. 我国全社会用电量差分后序列预测效果图(季节ARIMA)
4.3. Holt-Winters三参数指数平滑模型
在上述分析过程中,判断出该序列有趋势效应和季节效应,本章节使用Holt-Winters三参数指数平滑模型对该序列进行拟合与预测。应用Rstudio计算出该模型的平滑系数为:
通过Holt-Winters三参数指数平滑加法迭代公式,得到三参数的最后迭代值为:
参数
的12个估计值对应的是12个月度的季节指数,见表4所示:
Table 4. Three parameter exponential smoothing seasonal index
表4. 三参数指数平滑季节指数
所以,该序列向前任意K期的预测值等于:
(式2)
式中,j为t + k其对应的月份。
以2010年1月~2018年12月数据为训练集,以2019年1月~12月的数据作为测试集,根据上述得到的拟合模型(式2),对2019年后的数据进行预测,之后用实际值与预测得到的拟合值进行比较,结果如表5所示。
Table 5. Prediction results of power consumption of the whole society from January to December 2019
表5. 2019年1月~12月全社会用电量预测结果
从表5中可以看出,只有一月的误差超过了0.05,拟合效果欠佳,其余月份的预测效果在0.05以下,拟合效果准确,因此该模型用于拟合我国全社会用电量数据的比较合理,2019的平均误差为0.0232087,因此可以说明该模型用于拟合我国全社会用电量数据的合理性。图7展示的是我国全社会用电量预测效果图,预测值基本延续了原序列的发展趋势,模型拟合效果较优。
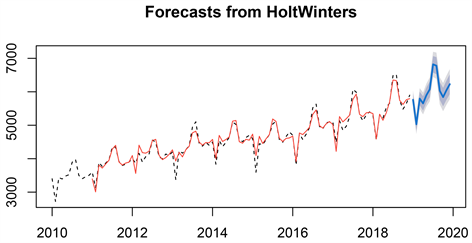
Figure 7. Smooth prediction chart of China’s total social power consumption series index
图7. 我国社会总用电序列指数平滑预测图
4.4. 季节ARIMA模型和指数平滑模型的比较
基于上述分析,季节ARIMA模型和三参数指数平滑模型的预测效果都取得了不错的拟合效果,但是三参数指数平滑的预测平均误差值0.0232087,远小于季节ARIMA模型的0.0315013,因此选择拟合优度较高的Holt-Winters三参数指数平滑作为我国全社会用电量的预测模型较为合理。
5. 结论与展望
本文以我国2010年~2019年我国全社会总用电量序列作为分析,通过时序图显示该序列具有逐步上升的趋势,具有明显的周期性,通过对该序列进行1阶差分12步季节差分后,数据变的平稳。本文首先使用季节ARIMA模型对该序列进行拟合预测,将2010年~2019年我国全社会总用电量序列分为两阶段,2010年1月~2018年12月为训练集,2019年1月~2019年12月为测试集,通过测试集和预测数值进行比较,计算得出平均误差;根据该序列的趋势效应、季节效应,对该序列采用Holt-Winters三参数指数平滑模型进行拟合预测,将原始数据分为训练集和测试集,将预测值与测试值进行比较,计算出最终的平均误差,根据平均误差的值,三参数指数平滑的预测平均误差值0.0232087,远小于季节ARIMA模型的0.0315013,选择Holt-Winters三参数指数平滑作为我国全社会用电量的预测模型更为合适。
本文在对社会用电量的预测中,采用的我国是2010年1月~2019年12月的月度数据年的年度数据,采用国家层面的数据是一个比较宏观和笼统的角度,下一步更为深入的研究可以将研究范围深入到省域、市域甚至是县域,针对各个具体的地域数据采用合适的模型进行预测,解决各个地区目前面临的电力供应紧张局面。