1. 引言
随着经济的快速发展,大气污染也日趋严重。PM2.5作为主要的污染物之一,因其粒径小,含有大量的有毒有害物质,不仅在大气中的停留时间长而且输送距离远,致使空气能见度降低,严重影响空气质量和大气环境,甚至危害人体健康 [1]。因此,PM2.5浓度预测工作对于严重污染事件的预警具有重要的价值和意义。
近几年来,随着机器学习和群智能优化算法的兴起和发展,机器学习被广泛应用于构建PM2.5浓度预测模型等智能识别领域,并且具有较高的准确率和实用性。现有研究采用历史气象数据或历史污染数据,利用支持向量回归模型 [2]、随机森林 [3] [4] 以及LSTM网络 [5] [6] 等单机器学习模型,预测实时PM2.5浓度。王勇等 [7] 利用FFT与LSTM神经网络方法构建PM2.5浓度预测模型,开展未来24 h的PM2.5浓度预测研究。张旭等 [8] 利用粒子群优化思想和遗传算法的交叉和变异操作相结合,对BP初始权值和阈值进行设定,并对PM2.5浓度预测,可以有效避免陷入局部极小,提高收敛速度。李建更等 [9] 提出了PLS-M5P (Partial Least Square-M5P)模型用于PM2.5浓度预测。马天成等 [10] 采用一种改进型PSO优化的模糊神经网络,预测PM2.5颗粒物浓度的变化规律。但是神经网络大多存在训练时间长、收敛速度慢的缺点。支持向量机在解决小样本、非线性以及高维模型中表现出许多特有的优势,并且具有良好的泛化能力 [11]。孟凡念等 [12] 融合集合经验模态分解和样本熵特征提取理论,提出基于粒子群优化最小二乘支持向量机的方法用于滚动轴承故障识别。最小二乘支持向量机(LSSVM)作为新一代机器学习算法,能够避免神经网络过拟合和支持向量机训练耗时长的问题 [13]。然而LSSVM的参数搜索是采用网格搜索法选择模型参数并进行交叉验证,搜索精度和效率低都是此算法的缺陷 [14]。LSSVM建模过程中,LSSVM模型中的参数一般是根据经验来设定的,盲目性大和效率低都是需要解决的问题。为了克服LSSVM算法存在的缺陷,需要采用其他算法优化模型参数,得到最优的参数组合。常用的优化算法一般操作步骤繁琐、耗时较长,可能存在一定的盲目性,并且其精度和收敛速度会因计算的问题维度过高而受到影响。
PM2.5作为主要的大气污染物,其来源和形成过程复杂,影响因素众多,具有高度复杂性和非线性的特征。目前大多数PM2.5浓度预测研究,只是基于PM2.5时间序列,很大程度上制约着预测精度。本文将基于空气质量指标数据(PM2.5、PM10、SO2、NO2、CO和O3)和气象数据(温度、相对湿度、降水量、风速和气压等)对下一日PM2.5浓度进行预测,但是数据当中存在着冗余数据,需要对上述多个特征进行特征筛选。因此,本文采用遗传算法对影响PM2.5浓度的特征变量进行优选,再使用麻雀搜索算法(SSA)来优化LSSVM模型参数,避免了一些传统的优化算法在选择参数时存在的问题,获取最佳的惩罚系数和核函数参数组合,提高了PM2.5浓度的预测精度。
2. 相关工作
2.1. 最小二乘支持向量机
最小二乘支持向量机(LSSVM)是在支持向量机(SVM)的基础上,由Suykens等提出的机器学习方法。此模型为一个等式约束优化问题,表示为
(1)
式(1)中:
为权值系数向量;
为惩罚系数;
为误差向量;
。根据Mercer
条件来定义核函数
(2)
式(2)中:
为非线性映射函数;
。最终得到LSSVM的非线性模型
(3)
式(3)中:
为拉格朗日乘子,
;b为偏差向量。
2.2. 基于遗传算法的特征优选
2.2.1. 染色体编码
由于二进制编码的编码、解码操作简单,交叉、变异等遗传操作便于实现,因此采用二进制编码的方式生成GA染色体,见图1所示。每条染色体由三个基因组成,前两个基因分别由长度为10的二进制编码组成,分别表示LSSVM惩罚因子C和核参数g;第三个基因表示特征变量的选取情况,长度为14,代表14个特征量,1表示对应的特征变量已被选取,0表示对应的特征变量未被选取。
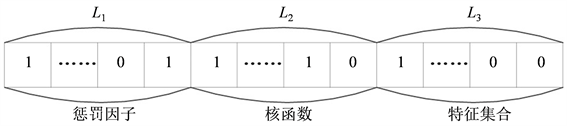
Figure 1. Binary encoding of chromosomes
图1. 染色体的二进制编码
2.2.2. 适应度计算
对染色体进行编码后,采用训练样本的均方根误差(RMSE)的倒数作为个体适应度f:
(4)
式中
、
和
分别表示最小二乘支持向量机的C、g和特征变量的组合编码;n为训练样本数据的数量,
为预测结果,
为真实值。
若要得到该染色体的适应度,需要对
段、
段和
段进行分段解码。
段和
段解码后得到的十进制数为LSSVM的C、g;根据
段中每一位的编码值挑选出被选择的特征变量,从而组成新的训练样本。
2.2.3. 遗传操作
遗传操作包括选择操作、交叉操作和变异操作:
1) 选择操作能提高了群体的平均适应度值。文中采用“稳态选择”,从而保留父代中适应度较高的个体;
2) 交叉操作用于产生新的个体。文中采用“单点交叉”;
3) 变异操作用于辅助新个体的产生,其决定了遗传算法的局部搜索能力。文中采用“基本位变异”。
2.2.4. 算法流程
基于GA与LSSVM的特征变量筛选流程见图2所示。
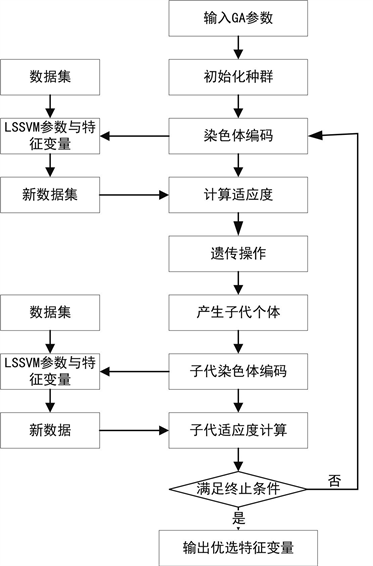
Figure 2. Flow chart of feature selection
图2. 特征选择的流程图
2.3. 麻雀搜索优化算法
在SSA算法中,每只麻雀代表一个极值优化问题的潜在最优解,并通过不断更新麻雀种群中发现者、加入者和侦察者的位置,对目标函数进行优化。SSA算法中发现者、加入者和侦察者的位置更新公式如下:
(5)
式中:t为当前迭代次数,
表示在第
次迭代时第i只麻雀的适应值,
是最大迭代数,
上的一个随机数,R2表示警戒值,ST表示安全阈值,q是一个服从正态分布的随机数,L是一个一行多维的全一矩阵。
(6)
式中:
表示发现者的最佳位置,
表示当前麻雀种群中的最差位置,
,A是一个各元素为1或−1的一行多维矩阵。
(7)
式中:
表示当前全局最佳位置,
是步长控制参数,
是一个随机数,
是当前的种群适应度,
和
分别为当前的最优适应度和最差适应度,
表示一个常数,主要用于避免分母为零,在本文中
取值为10E−8。
2.4. 评价指标
本文中采用常见的评价指标均方误差(MSE)、均方根误差(RMSE)和平均绝对误差(MAE)进行模型精度比较,预测方法效果更好,模型预测精度更高。指标的计算公式如下所示:
(8)
(9)
3. 基于特征选择和SSA-LSSVM的PM2.5浓度预测
为了解决影响PM2.5浓度的特征变量之间存在的相关性或者冗余性问题,以及最小二乘支持向量机的核参数、惩罚因子难选取等问题。采用遗传算法对特征数据集进行特征选择,获取最优特征子集。然后,融合SSA算法的快速搜索能力寻找最优的LSSVM参数,构建新的LSSVM模型。本文模型的具体操作步骤如下:
1) 特征选择。采用遗传算法进行特征选择,筛选出最优特征子集。
2) 数据预处理。为避免实验数据的取值范围差异和量纲的影响。采用采用最大–最小规范化方法对所选特征子集进行归一化处理,公式如下:
(10)
式中:x表示原始数据的真实值,
表示变换后的数据值,
表示原始数据中的最大值,
表示原始数据中的最小值。
3) 参数初始化。输入最优特征子集、SSA算法参数。算法参数包括麻雀种群规模
,最大迭代次数
,搜索空间维数D,参数搜索范围以及安全阈值ST等。
4) 初始化麻雀位置。基于惩罚因子C和核参数g等相关参数所设定的搜索范围,采用随机数法初始化麻雀位置
。
5) 计算初始种群中每只麻雀对应的适应度值,并确定当前最优适应度
和最差适应度值
所对应的位置
和
。其中,适应度函数定义为训练样本集的均方误差。
6) 更新位置。根据式(5)~式(7),依次更新发现者、加入者和侦察者的位置信息。
7) 判断算法是否达到最大迭代次数
,若是,则循环结束,输出寻优结果;否则返回步骤6)。
构建融合特征选择和麻雀搜索算法优化最小二乘支持向量机,其具体实现流程见图3所示。
4. 实验验证
4.1. 数据来源及其预处理
本文中以贵州省贵阳市为例,实验数据包含贵阳市空气质量数据和气象数据,其中空气质量数据来源于空气质量在线监测分析平台,气象数据来源于全国温室数据系统。实验数据选取2019年1月1日~2020年12月31日的空气质量数据和气象数据的日均值,共有730例样本,并将2019年1月1日~2020年10月31日的日均值数据划分为训练集,2020年11月1日~2020年12月31日的日均值数据划分为测试集。实验数据中收集贵阳市2019~2020年的六个空气质量指标(PM2.5、PM10、SO2、NO2、CO、O3)和八个气象指标(蒸发量、气压、日照时数、降水量、气温、风速、地表气温、相对湿度)作为PM2.5浓度的影响因素,并以下一日的PM2.5浓度数据作为因变量。为了方便进行特征选择,将变量进行编码见表1。
由于PM2.5浓度影响因素的量级有所不同,使用前还需归一化处理数据样本,以消除实用数据的取值范围差异和量纲的影响,所以本文中对实验数据进行归一化处理,以获得更好的预测效果。采用最大–最小规范化,即对原始数据进行线性变换,使得原始数据转换到[0, 1]范围,其中线性变换公式如公式(11)。
在使用GA同时优化LSSVM参数和筛选特征变量时,交叉概率为0.9,变异概率为0.01,种群大小为50、最大迭代次数200。LSSVM 参数设置如下:惩罚因子C和核参数g的范围分别设为[0, 200]和[0, 100],特征变量的个数为14。在本文中,为验证SSA-LSSVM模型的有效性,在PM2.5浓度数据集中进行测试。实验环境:存4 GB,64位的Windows10操作系统,实验工具为Python。在实验中,麻雀搜索算法的参数设置为:种群数量,即每次迭代过程中优化问题的潜在最优解的个数为20;最大迭代次数为50;维度,即优化问题中的寻找的相关参数个数为2,文中指径向基核函数参数C和惩罚因子g;搜索范围为分别设为[0, 200]和[0, 100];安全阈值ST为0.6。
4.2. 特征变量筛选结果分析
采用GA优选特征子集时,具体的特征量选取情况见表2所示。本文将所选最优特征子集作为最小二乘支持向量机的输入变量,并利用遗传算法和麻雀搜索算法LSSVM模型的参数进行优化处理,得到新的LSSVM预测模型,应用于PM2.5浓度预测中。
4.3. 预测方法对比
为了验证本文算法的有效性,基于相同的最优特征组合,采用基于遗传算法(GA)、粒子群优化算法(PSO)和麻雀搜索算法(SSA)构建的GA-LSSVM模型、PSO-LSSVM模型和SSA-LSSVM模型与标准LSSVM分别进行PM2.5浓度的预测分析,其中,在测试集中,三个模型的预测结果具体见图4所示,不同模型的评价指标结果见表3所示。
利用以上种方法对PM2.5浓度建立定量预测模型。由表3的分析结果可以看出,在LSSVM模型中,RMSE和MAE分别为16.06和13.04,说明预测曲线的精确度可以进一步提高。应用遗传算法、粒子群优化算法和麻雀搜索算法对LSSVM进行优化后,获得了最佳惩罚系数C和核函数参数g组合,并将其用于预测模型中。用GA-LSSVM、PSO-LSSVM和SSA-LSSVM预测PM2.5浓度变化曲线,拟合效果明显提升,相比于标准LSSVM模型而言,在GA-LSSVM和PSO-LSSVM模型中RMSE和MSE分别降低到了15.63和12.46、12.75和9.85,而在SSA-LSSVM模型中RMSE和MAE分别降低到10.53和8.01,精确度得到了一定程度的提高。另外,将GA-LSSVM模型和PSO-LSSVM模型与SSA-LSSVM模型进行对比发现,后者的预测效果更为显著,相比于前三个模型的RMSE和MAE都有所下降。通过实例验证表明,采用遗传算法对影响PM2.5浓度的特征变量进行特征选择,并结合SSA-LSSVM方法来提高PM2.5浓度的预测精度是可行的。
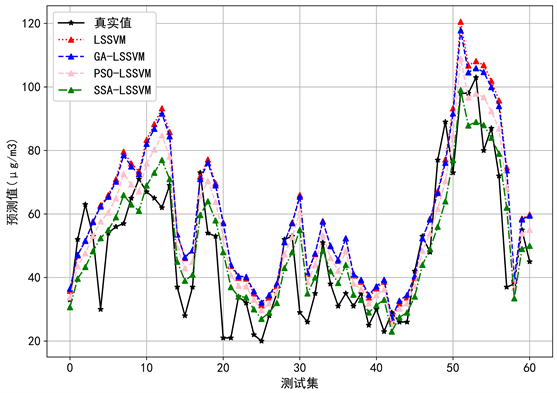
Figure 4. Comparison chart of predicted value and true value
图4. 预测值与真实值对比图

Table 3. Comparison of evaluation indicators
表3. 评价指标对比
5. 结束语
利用遗传算法对影响PM2.5浓度的特征变量进行特征筛选,获取最优特征子集,用来定量描述PM2.5浓度,将最优特征子集输入LSSVM、GA-LSSVM、PSO-LSSVM和SSA-LSSVM中进行PM2.5浓度的预测。并对结果进行分析,得出如下结论:
1) 特征变量的选取与LSSVM中的惩罚因子和核函数参数对PM2.5浓度预测影响都比较大,对其进行优化能够明显提高预测精度;
2) LSSVM算法的预测精度依赖于惩罚因子和核函数参数的合理选择,运用SSA算法获取LSSVM的最优惩罚因子和核函数参数,避免了参数选取的随机性,明显提高预测精度;
3) 提出的方法对PM2.5浓度预测的效果比较好,其中,本文模型的RMSE和MSE分别达到10.53和8.01。