1. 引言
入库流量预测可为水电站水库防汛抗旱、优化调度、水位控制 [1] 提供必要依据,在水库安全经济运行和水资源开发利用 [2] 等方面发挥重要作用。入库流量预测方法主要分为过程驱动模型方法和数据驱动模型方法两大类。过程驱动模型主要是基于对产汇流过程模拟建立的物理模型,然而物理模型大多结构复杂,且模型所需已知信息较多,包括水文、气象以及流域下垫面等信息,对资料匮乏的地区,建立物理模型较为困难。数据驱动模型则不需要考虑径流形成机制,只需建立输入、输出之间最优数学关系,其中基于时间序列自身的建模及预测作为一种重要手段在学术界和实际应用领域极为普遍 [3]。传统的时间序列预测方法通常假设数据是由线性过程产生的,由此基于线性关系建立符合假设条件的统计模型 [4]。然而,入库流量由于受到内部和外部众多不确定性因素影响 [5],具有非线性、时变性、动态性 [6],难以满足传统时间序列模型的假设条件。
随着大数据和人工智能时代的到来,以人工神经网络为核心的人工智能大数据技术在各个领域得以应用 [7]。近年来,以BP神经网络为代表的数据驱动预测模型具有强大的非线性映射能力 [8],逐渐被应用到时间序列预测分析中。在众多神经网络中,长短期记忆(long-short-term memory, LSTM)神经网络对时间序列预测具有显著优势,在水文时间序列预测方面具有较好表现 [9]。Kratzert等 [10] 利用大量流量数据集训练LSTM模型,通过LSTM预测结果与实际流量进行对比,得出LSTM可以用于流域流量预测的结论。殷兆凯等 [11] 采用LSTM建立了流域降雨径流模型,将流域降雨、气象及水文数据作为输入,并与新安江模型对比,得出在预见期0~2 d时LSTM预报精度最高。秦鹏等 [12] 提出一种新的耦合模型GAN-LSTM,该模型在缺失数据条件下的预报性能显著优于其他同类型模型。石晴宜等 [13] 建立基于小波分析的LSTM水质单因子预测方法,将其用于淮河入洪泽湖的水质预测,大幅度提升了水质预测精度。
由于入库流量序列是含有多种频率和趋势成分的非线性非平稳序列 [14],加之单一神经网络模型在训练过程中易受噪声信号干扰 [15],在一定程度上增加了直接预测难度,很难达到预测精度要求。因此,本文采用经验模态分解(Empirical Mode Decomposition, EMD)对原时间序列进行分解,以降低其复杂程度,对分解后的各分量采用LSTM模型分别进行滑动预测,最终将各分量预测结果进行加和重构获得入库流量的预测结果,并与单一LSTM模型进行对比分析。
2. 研究流域及数据
2.1. 研究流域
右江水库,又名百色水利枢纽工程,位于珠江流域右江上游河段,地处云贵高原东麓,地势西高东低,南北高中部低,为典型的河谷型丘陵地貌。右江水库坝址以上集雨面积为19,600 km2,占右江流域面积的47.5%。流域年平均降雨量位于1000~1700 mm之间,降雨年内分配不均,汛期降雨量占全年的80%左右,暴雨天气系统主要受副热带高压、热带低压、台风、东风波及西南低涡等影响。右江水库是一座以防洪为主,兼有发电、灌溉、航运、供水等综合效益的大型水利枢纽,水库总库容56.6亿m3,防洪库容16.4亿m3,调节库容26.2亿m3,死库容21.8亿m3,多年平均径流量263 m3/s,年径流量82.9亿m3,为不完全多年调节水库。右江水库控制流域如图1所示。
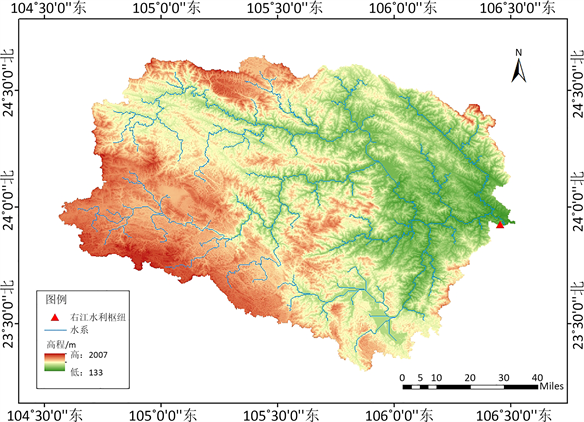
Figure 1. The map of Youjiang Reservoir basin
图1. 右江水库流域图
2.2. 数据
本文数据采用右江水库2017年1月1日至2019年12月31日入库流量日尺度数据,其过程线如图2所示,从图中可以看出,右江水库2017~2019年入库流量序列波动性较大,复杂程度较高,呈现出较强的非线性和非平稳性,且整体呈现出减少趋势。
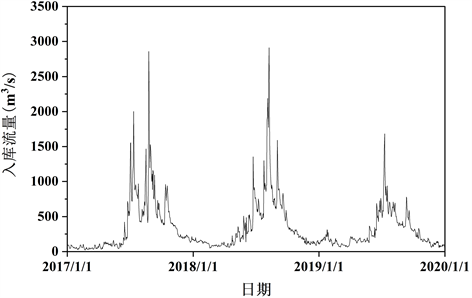
Figure 2. The daily inflow process of Youjiang Reservoir from 2017 to 2019
图2. 右江水库2017~2019年逐日入库流量过程线
3. 研究方法
3.1. EMD
EMD [16] 是一种基于数据本身时间尺度特征的自适应时频信号分解算法,该算法不需要任何先验假设 [17] 和预先设置任何基函数 [18],在非线性、非平稳时间序列的处理中具有良好效果。EMD算法可以将复杂时间序列分解为有限个本征模函数(intrinsic mode function, IMF)和一个趋势项(trend),分解得到的各IMF分量包含了原数据在不同时间尺度上的波动信息 [19]。EMD分解过程如下:
1) 首先计算出时间序列
的局部极大值、极小值,采用三次样条插值函数拟合所有极值点得到上包络线
和下包络线
;
2) 计算上包络线和下包络线的均值
:
(1)
3) 将
从
中剔除后,得到中间信号
:
(2)
4) 判断
是否满足IMF分量的两个条件:①信号中零点数和极值点数相等或至多相差1;②极大值和极小值包络线的均值相等且为0。若满足,则
作为一个IMF分量,否则将
作为一个新的输入序列,重复Step 1~4直到为止
满足IMF分量条件为止;
5) 将每次得到的IMF分量从原时间序列中剔除,重复上述步骤,直到最后余量信号
为单调序列或者足够小时,EMD分解结束。通过以上步骤,原时间序列分解成一系列
(
)和
。
(3)
3.2. LSTM
为了解决循环神经网络(RNN)存在长期依赖记忆丢失、梯度消失等问题,Hochreiter等 [20] 在RNN的基础上提出了带有记忆单元的LSTM模型。LSTM模型同样由输入层、隐藏层和输出层组成,不同的是LSTM模型在隐藏层中引入了记忆细胞单元代替了传统RNN中的细胞单元,每个记忆细胞单元组成包括一个状态单元和3个门结构(遗忘门、输入门、输出门),其中状态单元用于记录当前时刻状态,门结构可以控制对输入数据信息有选择的记忆或忘记。LSTM模型相关计算公式如式(4)所示。
(4)
式中:
、
、
、
分别为t时刻的遗忘门、输入门、输出门和记忆细胞单元状态;
、
分别表示相应的权重矩阵和偏移向量;
、
分别为前一时刻和当前时刻隐藏层状态;
为sigmod激活函数;
为记忆更新变量;
为双曲正切激活函数。
3.3. EMD-LSTM模型及评价指标
本文通过构建EMD-LSTM预测模型,即先将右江水库日入库流量序列进行EMD分解,对分解后的各IMFi和趋势项分别采用LSTM模型进行预测,将预测结果加和重构得到右江水库日入库流量的预测结果,EMD-LSTM预测流程图如图3所示,并与单一LSTM模型预测结果对比分析。

Figure 3. The flow chart of EMD-LSTM
图3. EMD-LSTM预测流程图
为了评价模型预测结果的可靠性和准确性,参考《水文预报规范》,采用平均绝对误差(MAE)、平均相对误差(MAPE)、确定性系数(DC)分别对单一LSTM和EMD-LSTM预测结果进行评价。
(5)
(6)
(7)
式中:
为实测入库流量,m3/s;
为模型预测的入库流量,m3/s;
为实测入库流量平均值,m3/s;T为时段数。
4. 研究结果
4.1. 数据预处理
为了避免入库流量数据差异过大导致模型收敛速度过慢甚至不收敛的情况、提高神经网络训练的精度和速度,首先将入库流量数据进行归一化处理,计算公式如式(8)所示。
(8)
式中:
为归一化之后的入库流量,其大小位于[0, 1]区间;
为时段t实测入库流量,m3/s;
、
分别为入库流量系列中的最大值和最小值,m3/s。
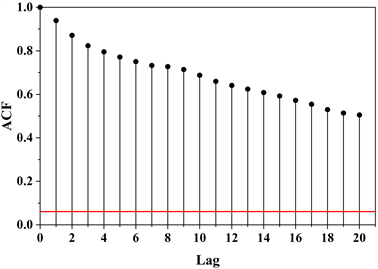
Figure 4. Autocorrelation coefficient graph of inflow series at Youjiang Reservoir
图4. 右江水库入库流量系列自相关图

Figure 5. Partial autocorrelation coefficient graph of inflow series at Youjiang Reservoir
图5. 右江水库入库流量系列偏相关图
在时间序列分析时,常采用自相关系数(autocorrelation coefficient, AC)和偏自相关系数(partial autocorrelation coefficient, PAC)找寻变量之间的相关程度。自相关系数用以描述数据系列自身不同时期的相关关系,即反映历史数据对现在影响的大小,而偏相关系数仅考虑滞后第k期对现在的影响。对右江水库日入库流量系列进行自相关和偏相关分析,并绘制自相关图、偏相关图分别如图4、图5所示,可以看出,ACF呈现出拖尾现象,PACF在滞时大于8时基本落在95%的置信带内,所以可以认为右江水库入库流量与滞后8天内的入库流量相关性较大。因此确定滑动窗口长度为8天,即采用前8天的数据作为模型输入预测当前入库流量。
4.2. EMD-LSTM模型构建及预测
对右江水库日入库流量系列进行EMD分解,得到7个IMF分量和1个趋势项,如图6所示,图中横坐标表示时间序列数(距资料系列开始日期的天数),纵坐标表示分解的各本征模函数值。可以看出,分解之后入库流量各分量的非线性、非平稳性和复杂程度明显降低,分量IMF1~IMF7的频率依次降低,所包含原始序列的信息依次减少,趋势项表明右江水库入库流量呈现下降趋势。
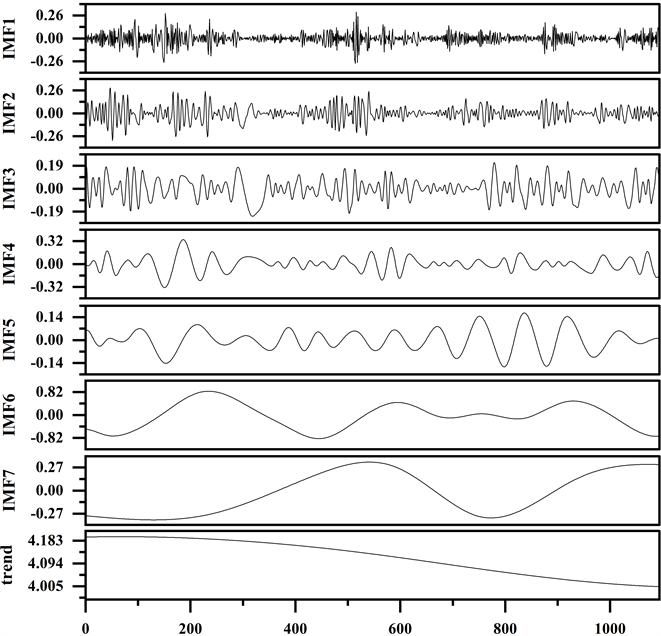
Figure 6. The decomposition result of inflow series by EMD at Youjiang Reservoir
图6. 右江水库入库流量系列EMD分解结果
以右江水库2017年~2018年共760天的实测日入库流量数据作为训练集,2019年共365天的数据作为测试集。数据预处理之后,将经过EMD分解得到的各IMF分量和趋势项分别建立LSTM。采用滑动窗口方法进行预测,将前8天的入库流量数据作为输入,预测未来1天的入库流量,通过不断更新当天的实测入库流量数据实现向前滑动预测。LSTM采用Adam算法训练内部参数,经调试,在隐含层神经元数为20、训练次数为500、学习速率为0.005时,LSTM具有较好的预测性能。最终将各IMF分量和趋势项的预测结果相加重构,得到右江水库日入库流量的预测结果。同时采用单一LSTM在同样条件下对右江水库日入库流量进行预测,用于与EMD-LSTM对比分析,两者预测结果如图6所示,并对各模型预测精度进行评价,评价结果如表1所示。
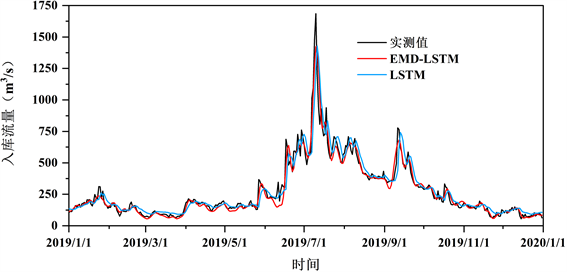
Figure 7. Comparison between prediction values of each model and original daily inflow of Youjiang Reservoir in 2019
图7. 右江水库2019年日入库流量实测值与各模型预测值对比

Table 1. Calculation results of each model evaluation standard
表1. 各模型评价标准计算结果
根据图7可以看出,EMD-LSTM模型和单一LSTM模型预测的入库流量与实测值变化趋势基本一致,均能较好追踪入库流量的动态变化,但在入库流量序列极值点处预测效果欠佳。由于右江水库日入库流量序列具有较强的非线性和非稳定性,单一LSTM模型预测性能劣于EMD-LSTM模型,同时受入库流量序列高一阶相关性的影响,单一LSTM模型预测结果明显滞后一个时段。相比单一LSTM模型,EMD-LSTM模型预测结果的MAE降低34%,MAPE降低35%,DC从0.88提高到0.95,说明EMD方法能有效滤除入库流量序列的噪声、降低原始序列的复杂程度,进而充分发挥LSTM模型的非线性处理能力,从而有效提高了右江水库日入库流量预测的精度和可靠性。
5. 结论
本文在对右江水库日入库流量预测过程中,首先采用EMD方法将原始日入库流量序列分解为有限个IMF分量和趋势项,降低原始序列的复杂程度,然后对这些分量分别采用LSTM进行预测,最后将每个分量的预测结果进行加和重构得到入库流量预测值。研究结果表明,相较于单一LSTM,将EMD同LSTM相结合可以充分发挥两者优势,能够深入挖掘入库流量序列固有特性,有效避免单一LSTM在训练过程中受序列高一阶相关性导致滞后现象,进而提高入库流量预测的准确性。同时,与直接将原始数据序列输入模型进行预测相比,“分解–预测–重构”模式更适合处理非线性非平稳的时间序列,表明在模型预测之前对时间序列进行预处理是十分必要的。
致谢
感谢广西电网有限责任公司为本研究提供基础数据与支持。
基金项目
国家自然科学基金资助项目(51779177);广西电网公司科技项目资助(0400002020030103DD00134)。
参考文献