1. 研究背景
在城市地区,居民迁居是一种常见的现象。它反映了人们如何与社会或物理环境互动。因此,地理学家等学者希望通过探索住宅变迁的运动模式,更多地了解与住宅流动相关的原因和影响,更好地理解人与环境是如何相互作用的 [1]。
城市内部的人口迁移不仅是城市社会与经济发展活力的主要标志,而且与城市内部空间结构的形成与演化密切相关。因此,城市地理学一直十分重视城市内部人口迁移以及对城市空间结构的影响研究。西方国家理论界对此做了大量研究,总结出不少理论与学说,这既包括聚焦于城市人口迁移的入侵演替理论、过滤理论等古典理论、家庭生命周期理论和互补理论,也基于空间规律和数量模式的研究,以及行为为的研究,70年代后期,还出现了结构主义和马克思主义学派等 [1]。2000年以后,关于中国城市内部人口迁移的研究不断增加 [2] [3] [4] [5]。柴彦威、史中华和周侃通过调查问卷,从迁移性、迁移方向性、迁移距离和迁移空间类型等特征,初步分析了迁居机制及其变化。
本次研究以不动产数据,提取微观尺度(个人)的运动,以权利人的购房行为,建立不动产迁居轨迹,研究不同地区迁居运动所导致的局部分化。
因此,为了便于从微观尺度上研究大量个体迁居变化的运动模式,本文引入了一个基于聚类的轨迹聚合算法,探索迁居运动的空间自相关性,反映了该社会事件所涉及的局部影响。本次研究研究涉及整合成都市市域范围,包括一、二、三圈层,涉及1100多万权利人。
2. 不动产统一登记数据
2013年12月20日,中央编制委员会办公室下发了《中央编办关于整合不动产登记职责的通知》(中央编办发[2013] 134号),明确要求:整合房屋登记、林地登记、草原登记、土地登记职责,出台并实施不动产统一登记制度。
不动产统一登记数据是建立以公民身份证号码和组织机构代码为基础统一的权利人住房信息。其最主要的信息包括:权利人,登记时间,权属类型,不动产单元号,宗地编号等,是目前唯一人、房、地信息统一的数据。
不动产登记数据随着权利人的购房行为进行追加或变更。当某个权利人进行了房屋的购买、出让、抵押、查封等行为时,就会在不动产统一登记数据库留下一条记录。如果以权利人的上一次购房行为为起点(Original点),以权利人的下一次购房行为为终点(Destination点),就可以建立权利人的迁居轨迹。
当然,并不是说权利人购置了下一套房产之后就一定会产生迁居这个动作,但这种购房行为从多个侧面反映了权利人的迁居意愿。一个简单的住宅运动行为在人与环境的互动中起着因果双重作用。因此,通过探索住宅运动的原因和影响,有可能更好地理解人与环境如何在社会和物理层面上相互影响。
3. 研究方法
轨迹是移动对象时空模式挖掘中的重点内容,特别是移动通信和智能交通领域。在基于位置的服务成为主流的今天,使得持续跟踪大量移动物体的位置成为可能,轨迹的生成也是轻而易举的事情。但如何在错综复杂的轨迹中找出隐藏的规律,则是轨迹数据时空挖掘的重点。
时间、空间和由运动派生出的属性是轨迹本身固有的三个基本特征,是轨迹运动状态和演变过程的重要组成部分。对轨迹进行聚类研究的重点是如何把这三个方面的基本特征进行综合考虑,在保证反映其相互之间正确的空间关系、时态关系、运动关系的基础上,提出合理有效的相似性度量公式,来获取符合专业领域有意义的群体时空移动模式。
3.1. 个体迁居行为的定义
住宅的流动性是当今社会的一个显著特征。每一个住宅运动可以表现为一个简单的空间轨迹,从不动产数据的角度看,就是权利人两次购房行为所产生的空间轨迹。对个人来说,购房的原因可能看起来是一个简单的问题,答案很简单:找一份新工作,换一个学区,找到一个更好的环境,为结婚而搬迁,或者只是为了好玩而搬家。但如果问题变成了为什么会发生一系列住宅变化,问题就不再简单了。这些问题可能涉及到成百上千的运动,每个运动都有自己的特定原因,同时经历不同的过程。
传统的工作侧重于宏观层面上的住宅变化,或者关注总体层面上的移动数据,无法完全捕捉到当地的移动趋势和模式。如何有效、高效地分析集体住区变化,探究集体住区变动的原因和影响,已成为一个吸引了不同学术领域的问题,如何更好地解释这些数据,有着不同的视角 [2] [3] [6]。
从空间的角度看,购房运动可以表示为一个简单的几何形状,由几个基本的组成部分组成:一个有向线段,其原点固定,移动主体从该线段出发。换句话说,购房运动的空间轨迹可以几何表示为方向线段或箭头。然而,我们感兴趣的不是单个箭头,而是由这些箭头组成的空间模式。当这些简单的几何图形被叠加在地图上时,它们就构成了包含有价值信息和知识的极其复杂的结构。在过去的几十年里,人们进行了许多研究来探索这种复杂的运动轨迹结构 [7]。
主要解决的问题包括:
· 如何检测个体运动的模式?
· 如何检测检测到的模式的统计意义?
· 如何评估移动数据中的局部影响?
· 如何在模式检测中解释社会经济和/或环境信息?
3.2. 个体迁居行为的空间化
为更好地理解个体迁居流动性,研究从微观空间尺度的单个住宅移动集合中检测空间模式和局部效应。将一个权利人的购房行为作为一个向量,有一个起点和一个终点。对于个体迁居行为变化的空间轨迹,起点代表旧住宅的位置,终点代表新住宅位置。
将不动产数据按权利人的购房时间分为:一套次、二套次、三套次、四套次、五套次及以上。一套次包含二套次所有房屋的起点,二套次是所有一套次购房人的终点。依次类推,每一套次,都是上一套次的终点,也是下一套次的起点。形成迁居O点层和迁居D点层(见图1)。
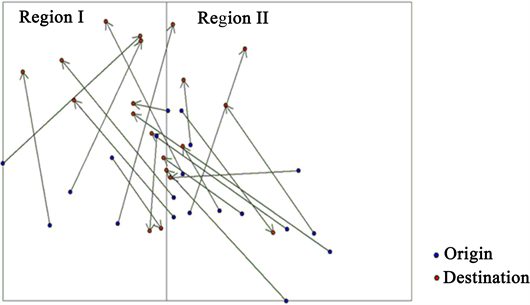
Figure 1. Cartographic visualization of motion vectors
图1. 运动矢量的制图可视化
3.3. 个体迁居行为的模式
迁居行为是住宅时间变化的空间轨迹,更确切地说,是一条定长方向线。探索运动行为的距离和方向趋势一直是地理分析领域的研究课题。
3.3.1. 空间几何算法
在空间几何中,迁居轨迹线是距离和方向的矢量。基于这一视角,迁居轨迹的空间格局可以指空间上向量的空间排列,或者更基本的是距离和方向双重成分的空间排列。对于移动数据,空间关系很难评估。原因是,比较是复杂的运动,给定的起点,目的和方向 [8] (见图2)。
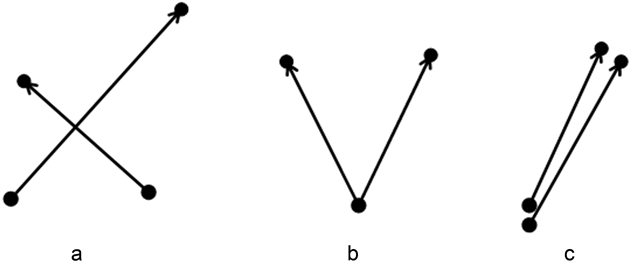
Figure 2. Schematic diagram of spatial “neighbor” relationship
图2. 空间“邻居”关系示意图
上图2(a)中成对的运动相交于一个中点,但它们不能被视为“邻居”,因为它们的起点和终点明显分离。虽然图2(b)成对运动有着相同的起点,但由于方向不同,它们并不是“邻居”。图2(c)中的一对没有共同点,但可以认为是邻居,因为它们的起点和终点都很近,而且距离和方向相似。在这里,无论是拓扑邻接还是距离都不适合评估运动数据中的空间邻域。然而,这种评估对于评估空间关联是必要的,因为正如前面所介绍的,这种影响是空间上接近的对象共享的属性。因此,对空间邻域的评估是研究空间关联的前提。
将邻近性度量初始化为运动之间的一个点。然后,距离和方向可以看作是与这个特定点相关的两个属性。对于向量,近源和相似的距离和方向有可能导致目标彼此接近,这表明整个向量必须在空间上接近,这就是运动的空间关联(见图3,图4)。
Figure 3. Schematic diagram of standardized vector division
图3. 标准化向量划分示意图
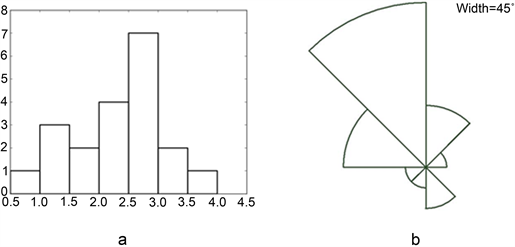
Figure 4. Histogram of distances and directions ((a) Histogram of distances; (b) Wind rose plot)
图4. 距离和方向直方图((a) 距离直方图;(b) 风向上升)
3.3.2. 空间聚类算法
时空轨迹聚类通过分析轨迹运动、几何、语义等特征信息,度量轨迹间的相似性,将时空轨迹数据集中相似性高的轨迹聚为一类。时空轨迹聚类算法主要包括基于空间的聚类、基于时空属性的聚类、轨迹分割–组合聚类(局部子轨迹聚类)、不确定性轨迹聚类、语义轨迹聚类、路网约束下的轨迹聚类、基于优化技术的轨迹聚类等方法。不同聚类算法所关注的轨迹特征信息及应用情形不尽相同,在实际应用中需要选取相应的聚类算法 [9]。
研究主要关注轨迹频繁模式(见图5)。指从海量数据中发现移动对象的频繁重复时序规律,应用于旅游路线推荐、地点预测等。主要包括基于Apriori算法及其改进算法、基于树结构、基于聚类兴趣区域、基于轨迹分段、基于路网匹配(针对路网约束下的时空轨迹)等方法的轨迹频繁模式挖掘 [10] [11] [12] [13] [14]。
3.4. 个体迁居行为模式算法
基于聚类兴趣区算法的关键在于找出核心点。在这个核心点的周围区域里有着较为密集的其它数据点。用数学方法来表示,在以核心点P圆心,以ε为半径的区域里,存在等于或大于规定数目MinPts的数据点。
本次研究采用改进的OPTICS聚类法进行成都市个体迁居行为模式的研究,要求具有投影坐标的空间点数据。适用于非平坦几何形状,不均匀的聚类大小,可变的聚类密度。
3.4.1. OPTICS聚类法
OPTICS (Ordering Points To Identify the Clustering Structure)不是直接生成聚类结果的一种基于密度的聚类算法,它的运行结果是生成可达图(Reachability Plots)。OPTICS需要先人为设定参数邻域半径ε和最小邻域MinPts数目,以得到了整个数据集的聚类结构 [10] 。
OPTICS算法使用两个队列来记录相关信息,一个队列记录已处理点的顺序,另一个队列记录按可达距离从小到大排序的核心点。算法先找到一个核心对象,放入结果队列中,然后找出其直接密度可达的点,再把这些直接密度可达的点,按可达距离从小到大排列,取第一个点进行判断,如果是核心对象,则放入结果队列,并找出这个核心、对象的所有直接密度可达的点,并把这些点按照可达距离从小到大再次排序,直至所有的点都处理完毕。
3.4.2. 个体迁居行为模式算法
将不动产数据按权利人的购房时间分为:一套次、二套次、三套次、四套次、五套次及以上。一套次包含二套次所有房屋的起点,二套次是所有一套次购房人的终点。依次类推,每一套次,都是上一套次的终点,也是下一套次的起点。形成迁居O点层和迁居D点层。形成如下所示的运动矢量(见图6)。
这里面临的问题是如果设定参数邻域半径ε和最小邻域MinPts数目。我们将此问题转换为迁居热点区及其中心。算法步骤如下(见图7):
第一步:寻找迁居热点区。对每套次数据计算其核密度,提取核密度的高值区。这样一套次的核密度高值区就是迁出高值区域,二套次的核密度高值区就是迁入高值区域。对每个热点区进行赋值。
第二点:相似性度量。以这两个区域分别求取落入区域中O点和D点。建立每个O点和D点的轨迹,进行轨迹构建,计算相同热点区域的OD线总数,即相似性度量。
第三步:轨迹聚类。求取迁居热点区的中心点,连接中心点,将相似性度量赋与中心点连线,按相似性度量进行可视化。
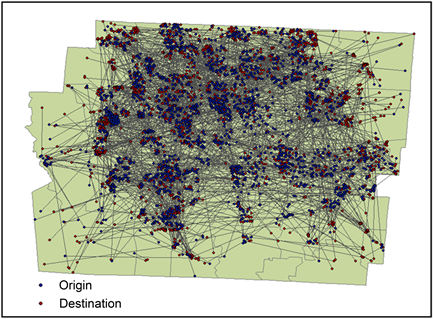
Figure 6. Schematic diagram of vector diagram of individual migration movements
图6. 个体迁居运动矢量示意图
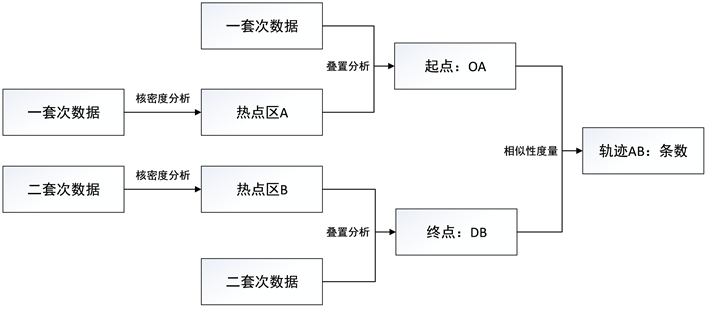
Figure 7. Framework of the similarity of individual migration trajectories
图7. 个体迁居轨迹相似性算法框图
4. 成都市个体迁居行为
4.1. 成都市不动产数据预处理
成都市不动产统一登记数据库现有数据21,881,309条,数据从1990~2020年,数据预处理主要分为两个方面:
4.1.1. 问题数据清理
经过对不规范数据的统计发现存在问题的不动产信息为11,482,875条。其主要问题在于:
1) 未区分个人权利人与公司权利人,此情况会导致同一权利人ID名下有数百套房屋。
2) 数据不完整,身份信息和时间信息格式不规范等。
对于问题进行清理后,最后得到有用的不动产信息为10,398,434条,从数量和覆盖范围上看都满足分析要求。
4.1.2. 脱密处理
1) 权利人的身份证信息,将其转换为性别、年龄、户籍。
2) 房屋坐落信息,对数据进行空间化处理,将坐落信息与宗地信息关联,形成空间点位。
3) 购房时间信息,按权利人购买次数,将购房时间转换为套数,按照购房时间将其分为一套次、二套次、三套次、四套次,五套次及以上。
数据经规范化和脱密处理后,形成了人、房、地统一的时空数据(见图8)。
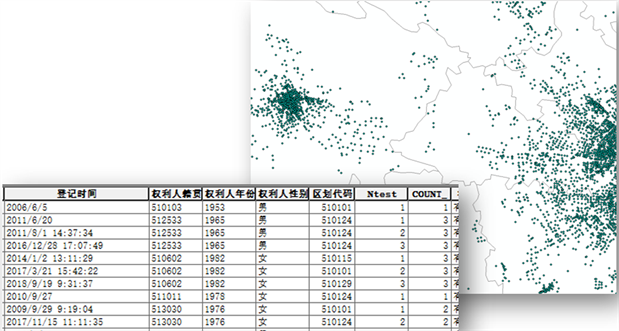
Figure 8. Schematic diagram of Spatio-temporal points of real estate data in Chengdu
图8. 成都不动产数据时空点位示意图
4.2. 迁居热点区
基于密度表面生成的连续数字场模型能够从汇总层面空间密度分布特征,但难以获得确切的热点区域和热点峰值。而热点的定量化表达、描述及格局分析,采用热点区域或热点峰值则更加有效 [15]。
1) 对每一套次数据进行点核密度生成(见图9)。
2) 对核密度图层进行栅格重分类,提取出不动产每个套次中的高值区域,并进行编号。
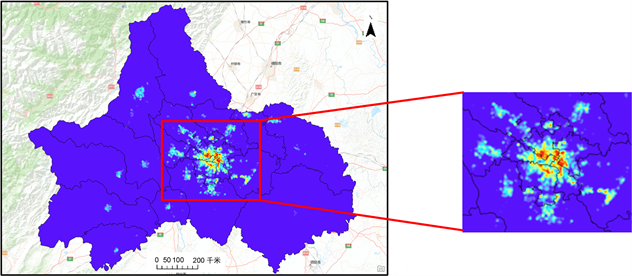
Figure 9. Spatial density maps of one purchase data in Chengdu
图9. 成都市一套次购房数据空间密度图
4.3. 迁居轨迹
将不动产数据按权利人的购房时间分为:一套次、二套次、三套次、四套次、五套次及以上。一套次包含二套次所有房屋的起点,二套次是所有一套次购房人的终点。依次类推,每一套次,都是上一套次的终点,也是下一套次的起点。形成迁居O点层和迁居D点层。形成如下所示的运动矢量(见图10)。
前一套次的高值区域逐区域编号,即为起点(O点)编号。后一套次高值的区逐区域编号,即为终点(D点)编号。连接所有OD点后,对每一条轨迹进行编号。如果O点的区域编号为1,D点的编号为5即这条OD线的编号为1~5。
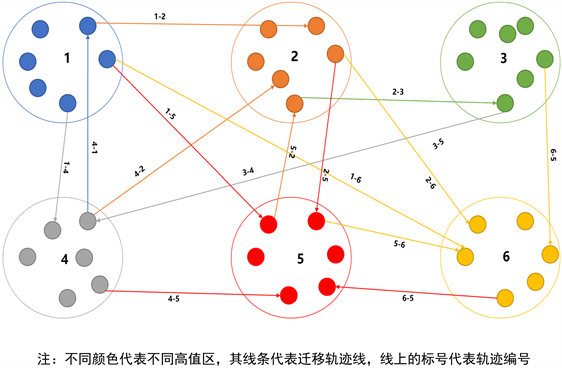
Figure 10. Schematic diagram of migration trajectory
图10. 迁居轨迹示意图
4.4. 轨迹相似性度量
根据迁居轨迹编号原则,具有相同编号的轨迹就是由同一起点向同一终点迁居的权利人。汇总具有相同编号的轨迹,即为轨迹相似性度量,形成了轨迹聚类(见表1)。

Table 1. Schematic table of trajectory similarity measures
表1. 轨迹相似性度量值示意表
5. 研究成果
按4的方法对成都市不动数据的各套次数据进行了个体迁居行为分析。可以看出各套次之间迁居行的差异。
5.1. 一、二套次迁居行为
由图11中可以看出,迁居的主要轨迹是从成都二圈层向成都一圈层移动。迁居入点较为密集的点出现在了武侯区和金牛区。由于成都市一圈层开发、建设时间较久,区域内部基础设施建设以及医院、学校等因素较第二圈层更为完善,为满足生活便利、孩子升学及投资等需求,在资金充裕后将第二套不动产购置在成都市一圈层。
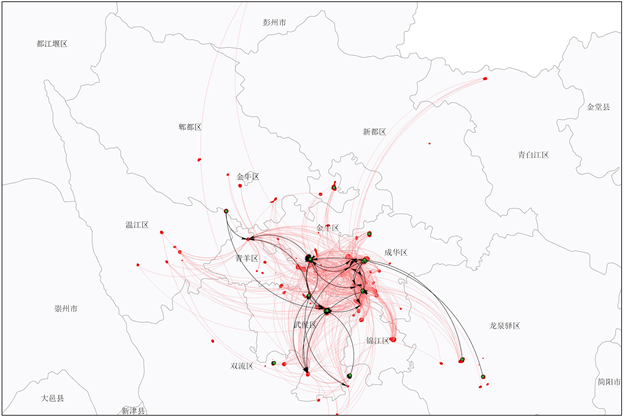
Figure 11. Migration trajectory of one to two sets data in Chengdu
图11. 成都市一二套次迁居轨迹图
5.2. 二、三套次迁居行为
从图12中可以看出,迁居轨迹分为两类:成都市五个主城区内部的迁移和从成都主城区迁往成都市二圈层,且出现了较为明显的向南迁移的趋势。
这两种迁居行为的投资、改善属性表现得比较明显。一方面房屋本身自带金融属性,购房者认为市区内部的房屋更具保值价值,所以将自己的下一套不动产依旧是购置在成都市一圈层内部区域。另一方面,成都市南部天府新区的建设,产生了房屋面积较大、居住环境较优的区域,诱导部分购房者南偏。
5.3. 三、四套次迁居行为
从图13中可以看出,迁居轨迹分为两类:
一是从成都市三圈层迁往成都市一圈层内。例如崇州市和青白江区,这是由于其本身长期居住于远郊地区,出于生活便捷以及投资的需要将自己的四套次房屋购置在成都市的一圈层中。
二是成都市一圈层内部。一圈层内部的迁居行为仍然偏多的原因,还是因为该区域的生活便捷以及权利人的投资需要。
5.4. 成都市四五套次迁居行为
从图14中可以看出,其图幅由之前的横版变成了竖版,体现出明显的南向迁移趋势。购房热点除了成都市一圈层内部区域处,南向天府大道沿线出现了大范围的购房热点区。同时东向一条远离主城区的迁居轨迹也应该引起重视。随着购房套的增加,高净值客户群体成为购房主力,他们对政策的敏感性更强,金融投资欲望更重。

Figure 12. Migration trajectory of two to three sets data in Chengdu
图12. 成都市二三套次迁居轨迹图
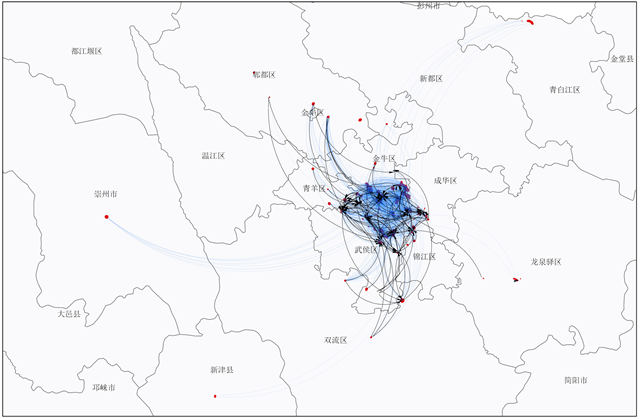
Figure 13. Migration trajectory of three to four sets data in Chengdu
图13. 成都市三四套次迁居轨迹图
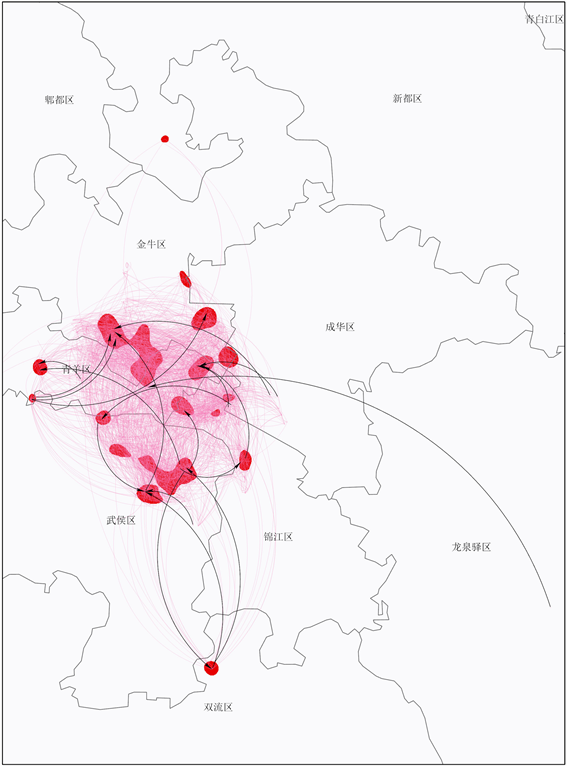
Figure 14. Migration trajectory of four to five sets data in Chengdu
图14. 成都市四五套次迁居轨迹图
6. 结论与建议
在本次研究中,通过提取不动产数据的时空特征,为迁居算法的构建提供了很好的数据基础。算法通过对聚类算法的改进,在空间密度算法的基础上,对迁居轨迹进行了相似性度量,较好地解决了轨迹聚类问题。本文的主要结论为:
1) 基于不动产统一登记数据,提取其时空数据结构,为个体迁居行为的定量分析提供了一种有效的分析数据。
2) 将空间密度算法与OD算法相结合,能够全面有效地识别和表达OD点的规模等级,极大地增强了轨迹聚类的分析和可视表达能力。
3) 方法应用于成都市个体迁居行为研究中,较好地挖掘出迁居行为的时空特征,为房地产市场监管提供了新的思路。
对成都市未来房地产市场监管,我们认为:
1) 主城区始终是首次购房热区域,其基础设施与配套可进一步加强;
2) 购房者再次选择的购置区域大概率会出现在自己所居住区域附近。迁居行为大多出现于购房热点区域内部,并没有出现大规模的跨区域迁移。
3) 购房者在多次购房后,对房屋的保值要求上升,主城区和政策导向性区域将是未来的购房热点。
在本次研究中,但也存在诸多问题。空间密度分析严重依赖于带宽阈值的影响,选择不同的带宽,结果也会有所差异,其本质是受地理学尺度效应的影响。权利人的购房选择受哪些因素影响也是本次研究中未涉及的问题。今后的研究中,将聚焦于解决以上两个方面的问题,为房地产市场监管提供了更好的方法与路径。
基金项目
国家社科基金项目“乡村振兴战略视阈下川滇藏交界地带特色藏族村寨建设研究”(18BMZ073);四川省自然资源厅科技项目“基于不动产大数据的成都市房地产市场运行动态监管关键技术研究”(2020KJ002)。