1. 引言
随着计算机技术的快速发展,电商行业的发展也十分迅速。据报道,在2021年的双十一活动中,京东电商平台的总交易额达到3491亿元,淘宝及天猫平台更是达到了5403亿元的总交易额,每天都有数以百万笔订单生成。因此,在大数据时代,如果可以合理预测用户的购买行为,将有效降低各大商家的备货等损耗,极大提升商家收益率。
用户购买行为受众多因素影响,如用户偏好因素,商品价格及品牌等因素。这些因素都将在很大程度上增加用户购买行为的不确定性,从而对预测效果的准确性提出挑战。用户的购买预测可以归纳为典型的二分类问题,即购买与不购买。目前有关用户购买预测的研究主要聚焦在两个方面:① 特征工程的构建;② 相关模型的选择。在特征工程的构建方面:刘潇蔓将 [1] 影响用户购买的数据分为基础特征、组合特征和衍生特征,从这三个方面构建数据的特征工程;卞天宇 [2] 则根据数据集构建了包含基础统计指标特征、排序特征、标签特征和用户平均加权选择倾向特征四个特征的特征工程;吴非 [3] 则主要从时间序列的角度完成对用户行为及基本特征的特征构建。在相关模型选择方面的研究大致可以分为两类,一类是单一算法模型的应用,如盛钟松 [4] 提出用CatBoost模型对用户购买行为进行预测;葛绍林 [5] 则用深度森林模型进行预测研究;Anindita A. Khade [6] 则基于统计分类器C4.5决策树算法构建客户数据可视化平台对用户行为进行研究;X. Liu [7] 使用支持向量机(SVM)的方法对用户购买进行预测;另一类则是组合算法模型的应用,吴非 [3] 在构建特征工程后,通过对GBDT模型与lightGBM模型的融合模型中的单模型进行网格调参实现对用户线上购买行为的预测;C. Okan Sakar [8] 等人则提出融合具有权重回溯的弹性反向传播特性的多层感知器(MLP)和长短期记忆网络(LSTM)两种算法的组合模型,构建一个实时在线购物者行为分析系统,并根据预测结果来提高网站的购买转化率。Bruno J. D. Jacobs [9] 等人采用将潜在狄利克雷分配(LDA)和狄利克雷多项式(MDM)混合的新方法应用在大型产品分类中,从而进行用户购买行为的预测,实验表明,其预测准确性优于协同过滤法和离散选择模型。曾宪宇 [10] 等人则提出用基于潜在因子的方式建立对用户购买商品和最佳替代商品的一种选择模型,称之为LF-CM (latent factor based choice model),随后为了提升预测的精度,又提出了一种针对购买周期中所有商品的排序学习模型LFS-CM (latent factor and sequence based choice model)。
通过对他人研究的学习,本文一方面将某在线商城的大量数据处理为150维的用户特征数据和120维的商品特征数据;另一方面由于随机森林较稳定,即数据集中出现了一个新的数据点,整个算法不会受到过多影响,它只会影响到一颗决策树,很难对所有决策树产生影响,所以基于随机森林的稳定性和残差网络更好地拟合分类函数及层数较深时训练的优化性,提出一种融合ResNet和DF的用户购买预测算法。
2. 理论基础
2.1. 残差网络
随着神经网络的发展,更多层的神经网络被用在各种研究中。然而,神经网络的梯度在反向传播的过程中要不断地被传播,这也就导致了当神经网络的层数在加深时,梯度在传播过程中可能会出现逐渐消失的现象,梯度消失可能会导致无法对前面网络层的权重进行有效的调整。ResNet的提出有效地解决了在加深网络层数时导致的梯度消失的问题。如图1,该图是残差网络的基本结构:

Figure 1. The basic structure of the residual network
图1. 残差网络的基本结构
残差网络借鉴了高速网络(Highway Network)的跨层连接思想,在此思想的基础上加以改进,原先的残差项是带有权值的,在ResNet中,将残差项用恒等映射的方式进行替代。
若某段神经网络的输入为x,期望输出是F(x),则在残差网络中,直接将输入x作为输出的初始结果,则输出结果为
,若
,则
,即此时为恒等映射。所以,在ResNet中,不再是通过训练及学习得到一个完整的输出,而是
,即残差。这也使得当网路层数很深时,当残差结果接近于0时,梯度不会消失,模型的准确率也不会下降。
2.2. 随机森林(Random Forest)
随机森林是Leo Breiman在20世纪90年代提出的一种方案,它利用一组生长在随机选择的数据在空间中的决策树来构建预测器集合 [11]。Breiman在 [12] [13] [14] 证明了通过树的系综,可以在分类和回归精度方面获得实质性的提高,其中系综中的每棵树是根据随机参数生长的,最终的预测是通过集合的聚合得到的。由于系综的基本成分是树结构的预测因子,并且由于这些树中的每一个都是使用随机性注入构建的,因此这些过程被称之为“随机森林”。
信息、熵和信息增益是决策树的根本,对于决策树而言,如果带分类的事物集合可以划分为多个类别当中,则某个类(
)的信息可以定义为:
(1)
其中,
用来表示随机变量的信息,
指的是当
发生时的概率。
在随机森林中,熵是用来衡量不确定性的,当熵越大,
的不确定性越大,反之越小,可以计作:
(2)
在决策树算法中,大家通常会选择信息增益作为用来选择特征的指标,其中,如果信息增益越大,通常代表这个特征的选择性好,在概率中定义为:待分类的集合的熵和选定某个特征的条件熵(X在给定条件下Y的条件干率分布的熵对于X的数学期望)之差,计作:
(3)
其中,
表示条件熵,且
。
在随机森林模型中,最后的分类结果通常依靠于决策树的投票结果来确定。
3. 基于ResNet和DF融合的用户购买预测模型
用户购买预测模型是用来预测某个用户是否会购买某个商品的一类模型,用户和商品会通过特征提取表示为能被计算的向量形式。本文中使用U表示用户特征向量,I表示商品特征向量,
表示预测模型,其输出表示该用户购买该商品的概率,如果预测的概率超过预设的购买阈值
,则认为该用户会购买该商品。预测模型可由多种预测模型线性叠加
,本文通过基于ResNet的深度神经网络模型和深度森林模型的线性叠加,提升了预测的精准度。
3.1. 基于RestNet的用户购买预测
图2所示的是基于ResNet的神经网络的购买预测模型结构,首先将用户特征U输入一个全连接的神经网络Net1,将用户特征U映射为维数为
的一维向量,然后将该一维向量变形为
维的二维向量并输入ResNet1中,输出和商品特征I维数相同的权重向量
,该向量表示该用户特征所代表的一类用户对商品不同特征的重视程度。商品集合
包含n个商品的所有特征向量,然后将权重向量
依次和商品集合中的每一个商品的特征
做点乘运算,得到一个长度为n的一维向量S,再将该向量S输入全连接的神经网络Net2,输出维数为
的一维向量,然后将该一维向量变形为
维的二维向量并输入ResNet2中,输出长度为n的一维向量y,向量y中的每一位数代表每个商品会被该用户购买的预测概率。购买的标签
由用户的历史购买行为生成,
是长度为n的一维向量,如果商品
被该用户购买过,则
中对应位置上为1,否则为0。损失函数使用的是二分类交叉熵(Binary Cross Entropy),如式(4)所示,通过最小化该损失函数更新模型参数。
(4)

Figure 2. Purchase prediction model based on ResNet
图2. 基于ResNet的购买预测模型
本文模型采用的残差块细节如图3所示:
3.2. 基于深度森林的购买预测
深度森林是周志华 [15] 提出的一种新的决策树集成方法:即生成一个具有级联结构的深度森林集成。由于本文数据集较大,深度神经网络训练起来又需要调大量参数,DeepForest训练起来过程效率高且可扩展且前人 [16] 的实验效果教好,所以本文采取该方法进行训练预测。
其主要包括两个阶段,如图4所示,一是借助卷积神经网络思想,采用滑动窗口进行特征提取,称之为多粒度扫描阶段。该模型将用户特征向量U和商品特征向量I拼接作为输入,设置滑动窗口维度为100,步长为1,生成扫描子样本,子样本经过随机森林A和随机森林B进行训练,生成概率特征向量;二是级联森林阶段,级联森林由多级随机森林组成,级联级别的数量可以根据模型的复杂性进行自适应确定。在本文中,将多粒度扫描阶段获得的概率特征向量作为输入,经4个不同的随机森林分类生成4个2维增强特征向量,随后将增强特征向量与原始概率向量组合生成新的特征向量作为下一级森林的输入向量。重复此过程,最后将最终输出的平均值中的最大值作为最终预测结果。

Figure 4. Part of the model of the deep forest
图4. 深度森林部分模型图
3.3. 组合预测模型
最后基于ResNet的神经网络购买预测模型
和基于深度森林的购买预测模型
通过线性叠加构成最终的用户购买预测模型
,其中
。
4. 实验
本实验数据来源于某电商平台提供的公开数据源,该数据主要包括两部分:第一部分为该电商平台的用户相关数据,经过特征提取,表示为长度为150的用户特征向量,用户的特征主要有年龄、性别、所属地区等;第二部分为该电商平台上有关商品数据,经过特征提取,表示长度为120的商品特征向量,商品特征主要有商品品牌、颜色、价格、产地等。表1为基于ResNet的神经网络购买预测模型中超参数的设定。

Table 1. Improved model structure parameters
表1. 改进模型结构参数
4.1. 数据
该数据源自某在线商城2016年2月1日至2016年4月15日的历史数据,该数据经过脱敏处理。该数据源可将数据分为三类:某类商品的基本信息,如表2所示,用户基本信息,如表3所示,用户和商品的交互数据,如表4所示。经过特征工程处理,将用户特征和商品特征处理成one-hot形式的向量。
Table 2. Product basic information data sheet
表2. 商品基本信息数据表
Table 3. Basic table of user interaction data
表3. 用户交互数据基本表
Table 4. User basic information data sheet
表4. 用户基本信息数据表
4.2. 评价指标
预测用户的购买与否行为是典型的二分类问题,所以在本文中我们采用二分类问题中常用的评价指标,即本文实验结果采用预测精度(Precision)和召回率(Recall)和F1综合评价三个指标,计算公式如下:
(5)
(6)
(7)
其中,TP为预测正确的购买正样本数,FP则表示预测错误的负样本数,即预测购买但实际没有购买的样本数,FN表示预测错误的正样本数,即用户实际购买了但是在预测中没有购买的样本数。
4.3. 实验结果
图5所示式基于ResNet的购买预测模型训练过程中损失的变化曲线,可以观察到,在前10,000步左右的时候,损失降低的比较快,从0.9左右快速降到0.5左右,随后loss降低的速度开始放缓,最终训练到70,000步左右时,损失降低到0.3左右。

Figure 5. ResNet-based purchase prediction model training process
图5. 基于ResNet的购买预测模型训练过程
图6所示是深度森林中随机森林的最大深度对最终结果F1指标的影响,可以看到在最大深度为40的时候,F1的指标会达到最高,所以最终采用的随机森林的最大深度为40。
为了对比基于深度残差网络和随机森林的组合模型对于用户购买行为的预测效果。在相同的训练集上,本文采用了其他三种预测方法训练了模型。在集成学习算法模型中,基于相同的用户特征、商品特征和用户行为数据训练了XGBoost模型和LightGBM模型;在线性分类模型中,训练了SVM模型;在机器学习算法中,训练了随机森林算法模型。最后,将在5个训练模型中训练的预测效果进行对比比较。如图7所示,展示了多种模型在该任务下的表现,本文提出的ResNet + DF的融合模型方法在F1和Precision指标的比较中均高于其他方法,仅在Recall指标中略低于XGBoost模型,表5中展示各指标的具体数值。
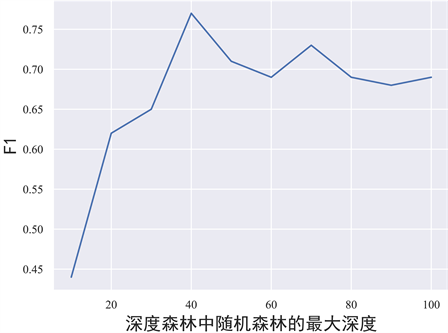
Figure 6. The impact of the maximum depth of different random forests in the deep forest on the final F1
图6. 深度森林中不同随机森林的最大深度对最终F1的影响

Figure 7. Comparison of results of multiple models
图7. 多种模型结果比较
Table 5. Comparison of the performance of various algorithm models on the test set
表5. 各种算法模型在测试集上的表现比较
5. 总结
本文主要介绍了应用深度残差网络和随机森林两种模型的组合模型解决电商用户购买行为预测的问题。首先提出了基于深度残差网络和随机森林两种模型的组合模型来预测用户购买与不购买这一典型的二分类问题,后使用真实的电商数据来验证评估模型。根据实验结果可以看出,该组合模型比其他单一模型具有更高的F1值,其F1值为0.7758。但本文的模型未对用户购买时间进行预测,即用户在浏览或收藏某一产品后产生购买行为的时间进行预测,基于时间的预测将是未来研究的重要方向。预测用户的购买行为及购买时间这种方法可以为企业的库存决策和精准营销提供有力的支持。
基金项目
课题编号:2020C01157;
课题名称:全流程供应链协同企业服务平台开发及应用——全流程供应链协同企业服务平台开发及应用;
计划类别:浙江省省级重点研发计划;
构建快消品及装备两个制造行业的全流程供应链协同模式,开发一个全流程供应链协同企业服务平台,实现市场感知、预警、响应与主动服务,具有市场预测、计划投放、补货决策、物流服务等功能,快速响应市场业务需求。