1. 引言
混凝土抗压强度是衡量混凝土质量的关键指标之一,也是工程设计、施工及验收的重要依据。准确监测或评定出建筑物结构的混凝土抗压强度,对建筑物结构的安全性具有深远的意义。对混凝土抗压强度进行评定的主要方法是先对混凝土试件进行28天养护 [1] [2],然后再进行测试,或利用无损检测技术对混凝土强度进行评定 [3]。这类评定方法的局限性在于会影响施工进度和施工质量。对于普通混凝土强度,一般可以用水灰比为主要因素的线性函数来进行描述和预测,而对于高掺量的高炉矿渣–粉煤灰混凝土来说,由于组分的增加,水化反应的机理还不完全明确,影响因素复杂并具有交互作用,表现为特定的高维非线性规律 [4]。
人工神经网络和机器学习可以挖掘到数据的深层规律,是解决非线性问题的有效手段之一,并且具有容错、联想、推测、记忆、自适应、自学习和处理复杂模式的功能,已有许多学者将人工神经网络和机器学习应用于混凝土抗压强度的预测。马高等 [5] 建立了BP神经网络模型预测CFRP约束混凝土的抗压强度;胡毅等 [6] 提出了一种基于随机森林(RF)的混凝土抗压强度预测方法;曹斐等 [7] 以支持向量机(SVM)算法为理论基础,提出一种基于马氏距离的加权型SVR (MWSVR)的人工智能算法对混凝土强度进行预测;Zaher Mundher Yaseen等 [8] 将极限学习机(ELM)模型用于轻质泡沫混凝土抗压强度的预测;许开成等 [9] 利用SPSS软件的逐步回归分析法、多元非线性回归法(MnLR)建立锂渣混凝土的强度预测模型。
为更加准确地预测高炉矿渣–粉煤灰混凝土的抗压强度,本研究以UCI的Concrete Compressive Strength数据集为基础,借助MATLAB软件,采用遗传算法优化BP神经网络的初始权值及阈值,以水泥、高炉矿渣粉、粉煤灰、水、减少剂、粗集料、细集料、置放天数这8项指标作为输入参数,以立方体抗压强度作为输出参数,建立了基于GA-BP神经网络的高炉矿渣–粉煤灰抗压强度预测模型。最后与人工神经网络(BP)、随机森林(RF)、支持向量机(SVM)、极限学习机(ELM)和多元非线性回归(MnLR)的预测结果进行对比分析,验证所提出的GA-BP模型在高炉矿渣–粉煤灰混凝土强度预测中的可行性,为此类混凝土强度预测提供新思路。
2. 方法及原理
BP神经网络是一种多层前馈神经网络,该网络的特点是信号前向传递,误差反向传播。在前向传递中,输入信号从输入层经隐含层逐层处理,直至输出层。每一层的神经元状态只影响下一层神经元状态。如果输出层得不到期望输出,则转入反向传播,根据预测误差调整网络权值和阈值,从而使BP神经网络预测输出不断逼近期望输出。BP神经网络的拓扑结构如图1所示。
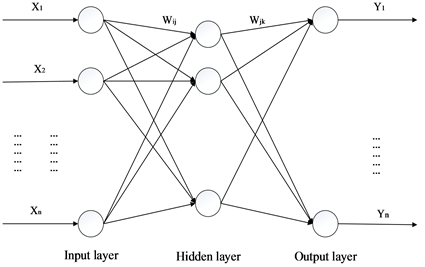
Figure 1. BP neural network topology
图1. BP神经网络拓扑结构图
图1中,
是BP神经网络的输入值,
是BP神经网络的预测值,
和
为BP神经网络权值。BP神经网络可以看成是一个非线性函数,网络输入值和预测值分别为该函数的自变量和因变量。
然而对于大数据量、高维数及多隐藏层节点等条件,各类神经网络训练过程很有可能会遇到大量的局部极值,不仅严重影响了收敛速度,而且有可能导致训练误差收敛于局部最优解而不是全局最优解,严重影响了神经网络的性能。遗传算法(Genetic Algorithm, GA)是一种模拟生物遗传及进化机制的自适应并行寻优算法,它具有全局搜索、并行性高、泛化能力强等优点。将遗传算法应用于BP神经网络,可以增强网络训练收敛的精确性,并且充分发挥遗传算法的全局寻优特性 [10] [11]。
GA-BP神经网络,即采用遗传算法对BP神经网络的初始权值和阈值进行改进,得到全局最优区域,接着用最优权值和阈值进行BP神经网络训练直到训练结束,并搜索最优适应度对应的参数。图2是GA-BP神经网络建立的过程。
2.1. GA优化过程
遗传算法优化BP神经网络的要素包括种群初始化、适应度函数、选择操作、交叉操作和变异操作。
1) 种群初始化
个体编码方法为实数编码,每个个体均为一个实数串,由输入层与隐含层连接权值、隐含层阈值、隐含层与输出层连接权值以及输出层阈值4部分组成。个体包含了神经网络全部权值和阈值,在网络结构已知的情况下,就可以构成一个结构、权值、阈值确定的神经网络。
2) 适应度函数
根据个体得到BP神经网络的初始权值和阈值,用训练数据训练BP神经网络预测系统输出,把预测输出和期望输出之间的误差绝对值和E作为个体适应度值F,计算公式为
(1)
式中,n为网络输出节点;
为BP神经网络第i个节点的预测输出;k为系数。

Figure 2. The establishment process of GA-BP neural network
图2. GA-BP神经网络的建立过程
3) 选择操作
基于适应度比例的选择策略,每个个体i的选择概率
为
(2)
(3)
式中,
为个体i的适应度值,由于适应度值越小越好,所以在个体选择前对适应度值求导数;k为系数;N为种群个体数目。
4) 交叉操作
由于个体采用实数编码,所以交叉操作方法采用实数交叉法,第k个染色体
和第l个染色体
在j位的交叉操作方法如下:
(4)
(5)
式中,b是[0,1]间的随机数。
5) 变异操作
选取第i个个体的第j个基因
进行变异,变异操作方法如下:
(6)
式中,
为基因
的上界;
为基因
的下界;
;
为一个随机数;g为当前迭代次数;
是最大进化次数;r为[0,1]间的随机数。
2.2. 模型数据库描述与分析
记前8个输入参数分别为自变量X1、X2、X3、X4、X5、X6、X7、X8,输出自变量抗压强度为Y1。为了对数据库进行详细的描述,统计分析了所有变量的最小值、平均值、中值、最大值、标准差、偏度和峰度,如表1所示。

Table 1. Statistical parameters of input and output variables
表1. 输入和输出变量的统计参数
-代表无实际意义;Std-代表偏度;Kur-代表峰度。
皮尔逊相关系数可以分析自变量之间以及自变量与因变量之间的相关性,利用Rstudio软件进行计算绘图,其结果如图3所示。由图3可以看出,各输入变量之间相关性不高,不存在多重共线性问题。
在1030组粉煤灰–矿渣混凝土数据中,随机抽取70%的数据作为训练样本,30%的数据作为测试样本。GA-BP模型与其他对照组模型均以此标准设置训练样本和测试样本。
2.3. 模型的性能指标
本文选取五个统计量值用于评估MARS模型和对照模型的预测精度,即决定系数(R2)、均方误差(RMSE)、平均值误差(MAE)、平均绝对偏差百分比误差(RMAE)和效益系数(E),计算公式见表2。

Figure 3. Heat map of correlation among variables
图3. 各变量的相关性热图
Table 2. Statistical index calculation formula
表2. 统计指标计算公式
是实际目标值,
是
的平均值;
是预测值,
是
的平均值;N是模型数据数目。
3. 模型验证
3.1. 训练MARS模型及结果分析
本文从模型数据库中随机选取721组数据构建MARS模型的训练样本,剩余的309组数据则为测试样本,基于水泥含量、高炉矿渣粉含量、粉煤灰含量、水含量、减少剂含量、粗集料含量、细集料含量、龄期共8个特征,利用MATLAB软件建立粉煤灰–矿渣混凝土预测的GA-BP模型,参考相关文献 [12],输入节点个数设为8,输出节点个数为1,基因的上下界为±1,变量个数为16,最大遗传19代。因为训练样本和测试样本数据较多,为了展示拟合的效果,两组分别选取25组数据进行可视化绘图,如图4、图5所示。
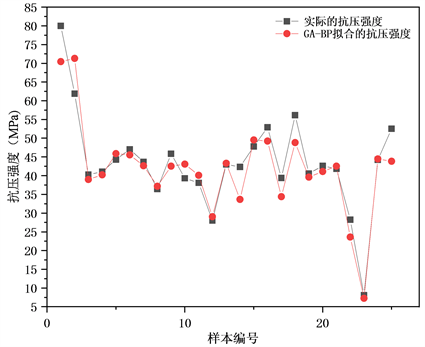
Figure 4. GA-BP model training sample fitting effect
图4. GA-BP模型训练样本拟合效果图
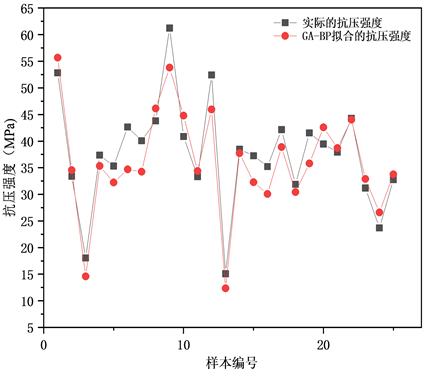
Figure 5. GA-BP model test sample fitting effect
图5. GA-BP模型测试样本拟合效果图
由图4、图5可知,预测值和实际值接近,即GA-BP模型预测结果准确,误差较小,拟合精度高。
3.2. 模型性能比较
将GA-BP模型与各种模型的预测性能进行比较,包括BP、RF、SVM、ELM和MnLR等非线性模型,其拟合结果如下所示。
由图6可得,GA-BP预测模型的大部分散点数据集中在100%回归线及其周围,而BP、RF、SVM、ELM和MnLR散点数据离散性很大。将图6中的数据根据
的形式进行拟合,与对照组的五个模型相比,MARS模型的
值更接近于1,
值更接近于0。验证了GA-BP模型的预测精度更高,误差更小。
3.3. 模型的统计指标
根据前文所述的评价指标公式,计算结果见表3。
Table 3. Results of R2, RMSE, MAE, RMAE and E (%) for different models
表3. 不同模型的R2、RMSE、MAE、RMAE和E (%)结果
由表3可得,GA-BP预测模型比其他模型的R2、E (%)值高,RMSE、MAE、和RMAE值小,即MARS和RF在该数据库上预测性能优越。
由图7可得,GA-BP模型的相对误差大部分集中在0线周围,其余模型的相对误差波动很大。GA-BP的预测性能稳定,明显优于其余模型。
4. 结论
准确预测或评定高炉矿渣–粉煤灰混凝土抗压强度具有重要的工程意义。由于影响混凝土抗压强度的因素有很多,而且这些影响间往往相互不独立,影响了对抗压强度预测或评定的精确度。因此,在评定或预测模型建立之前,有必要对各因素指标进行相关性验证,选择最能表征抗压强度的因素指标参与评定和建模,这样有助于提高评定结果的准确性和所建模型的预测精度。本文利用GA-BP算法建立高炉矿渣–粉煤灰混凝土的抗压强度预测模型,与人工神经网络(BP)、随机森林(RF)、支持向量机(SVM)、极限学习机(ELM)和多元非线性回归(MnLR)的预测结果进行对比分析,GA-BP模型在R2、RMSE、MAE、RMAE和E值上都优于其他模型,进一步说明该模型的可靠性和准确性,可很好地应用于工程实际之中。