1. 引言
机器学习中的分类算法属于有监督的学习算法。在理论上主要的区别是,支持向量机(Support Vector Machine, SVM [1] )采用hinge损失函数,学习分类决策边界;正则逻辑回归(Regularization Logistic Regression, RLR [2] )采用对数损失函数,学习某一类的条件概率。在应用方面的主要区别是SVM硬间隔分类器表现更佳,RLR软间隔分类器表现更佳。对于SVM和RLR两种分类算法,目前已有一些理论研究和应用实践。
对于SVM分类算法,在2007年Steinwart和Scovel给出带有hinge损失的SVM分类算法。2009年和2011年向道红相继在基于高斯和凸损失分类 [3] 研究中,给出hinge凸损失函数于再生核希尔伯特空间中SVM分类器的学习率,得出该学习率与空间维度和样本量有关 [4]。在2010年Jeongyounahn [5] 研究了SVM在高维小样本数据中产生的大量数据堆积问题,并在最大数据堆积方向、SVM、DWD、RLR上进行了平均误分率的应用研究。而在2011年,Yufeng Liu [6] 等人在硬或软分类器的应用探究中,给出SVM硬分类器倾向于运用靠近分界线的数据点产生分类决策边界而不产生概率估计。对于RLR分类算法,在2010年向道红对于无零点的logistic损失函数相关分类算法做出误差分析 [7],通过投影算子考虑无界情况,给出RLR分类器的学习速率,得到该学习率与空间维度和样本量有关。同年在数据堆积应用研究中,给出RLR分类算法的平均误分率随着维度变化的走势。而对于两者的直接对比,目前尚未有成熟的应用研究,本文将对两种分类算法进行比较研究,得到在不同情况下两种分类算法的表现能力。
本文分为三部分,第一部分介绍hinge损失函数和SVM分类算法原理。第二部分介绍logistic损失函数和RLR分类算法原理。第三部分进行仿真实验,通过PCA降维,首先在699个不含有离群值的2~9维样本数据中,得到预测准确率走势图,比较两种分类算法的分类效果;其次在1060个含有离群值的数据中进行同样的实验,比较两种算法的鲁棒性;然后在阿尔兹海默症高维小样本数据集中,对两种算法的稳定性和分类效果进行对比;最后通过实验运行时间和占有内存,就算法复杂度做比对。
2. SVM分类算法原理
2.1. SVM
早在1995年,Vapnik [8] 就提出了支持向量机,相比于其他的分类算法,它有着比较高的泛化能力。一组给定的样本集
,x可以取连续型数值也可以取离散型数值,对应的
取值为±1。SVM分类算法的目标在于基于训练样本集找到样本空间的划分超平面,把两种不同的类别分开。
定义超平面为:
, (1.1)
其中,上式(1.1)中
代表法向量,决定了超平面的方向,b代表截距,决定了超平面和原点之间的距离。这两项共同决定了超平面的位置,故可记为超平面
。任意一个样本点到超平面的距离为:
.
在样本空间中,若超平面
满足下列条件:
(1.2)
则表明超平面
可正确分类样本。
见图1中,画圈的三个样本满足(1.2)式,因此被称为支持向量(support vector)。分类之后,两个分属不同类别的支持向量到超平面的距离之和称为间隔:
.
最优超平面既要正确分类,又要保证两类样本间的间隔达到最大,为最大间隔的分类超平面,也称为为软间隔,不需要所有样本都划分正确。故寻找最优分类超平面可归结为求解如下优化算法:
(1.3)
线性可分支持向量机算法可转化为如下优化问题:
(1.4)
2.2. hinge损失函数
(1.5)
上式为hinge损失函数(hinge loss function [2] ),如图2所示,下标“+”表示取正值的函数,
这意味着当样本点被正确分类时,损失为0,否则损失为
。
见图2可以看到hinge 损失相对于logistic损失的特点是有零点,在1处不可导。
2.3. SVM分类算法
令
为通过训练数据学习出的线性分类器,且为了克服过拟合,加入正则项。假设所有函数均定义在再生核希尔伯特空间中,
,k代表核函数。
则带有hinge损失的SVM分类器为:
(1.6)
表示决策函数;
表示正则化参数。
3. RLR分类算法原理
3.1. 逻辑回归
逻辑回归虽然名为回归,其实是一种分类学习方法,主要用于二分类问题。该分类模型用条件概率分布
表示,
,
其中,
称为权值向量,b为偏置,
为输入的随机变量。当w和x的内积取值接近正无穷则概率值为1,反之为0,为线性函数模型。w是需要通过训练数据学习的参数。
因乳腺癌数据在低维空间线性不可分,则需要对原始数据进行多项式变换,加入高次项,来解决决策边界非常复杂的情形,使之非线性可分。
令
,
Logistic分布函数(同sigmoid函数)如图3,形式为:
通过函数
对
进行变换,将取值挤压到[0, 1]区间内:
.
表示参数集。
,
当
时,
,则样本为正例,输出1;反之,输出为0。
3.2. logistic损失函数
如图4可以看到logistic损失相对于hinge损失的特点是没有零点,在1处可微。
3.3. RLR分类算法
由于LR分类算法存在过拟合,因此在逻辑回归中,引入正则化项。通常使用
正则化。加入
正则项容易得到稀疏解(The sparse solution [4] )。也可使用
正则项。引入正则化参数
,假设所有函数均定义在再生核希尔伯特空间中,
,k代表核函数。
则带有logistic损失的RLR分类器为:
4. 仿真实验
4.1. 数据统计描述
实验环境python3.0,sklearn。
采用南斯拉夫卢布尔雅那大学医疗中心肿瘤研究所提供的威斯康辛乳腺癌数据集,用python3中的strategy参数操作,将缺失值用该列的均值替换,得到可以完整可进行实验的数据。部分数据如表1所示:

Table 1. Partial data of breast cancer dataset
表1. 乳腺癌数据集部分数据
见图5数据中各属性的二分类数据特征用面积图展示,两两之间的相关性用散点图展示。可以看出,mean_radius和mean_perimeter之间有明显的线性相关关系。
数据集共有1060行数据,30个属性,分2大类。由于一部分属性具有相关性,运用PCA (主成分分析,principal component analysis)进行特征提取,最大程度保留原始信息。从原先的30个维度,分别降低到2~9个互不相关的维度。最后一列数据为输出类,出于与原数据区分的目的,将0更改为2类和1更改为4类。9维数据统计描述如表2。
部分数据统计后,画出箱式数据分布图,见图6,其中圆圈表示离群值。
4.2. 在乳腺癌数据集上的分类效果比较
图6中可观察得到,该数据集中含有离群值,为了比较在离群值的影响下,SVM和RLR两种分类算法的鲁棒性和分类效果,进行了如下实验。
1) 删除离群值数据集
将离群值删除后,得到699个样本数据,进行十折交叉验证,选取2组作为测试集,剩余8组作为训练集,代入两种分类算法,计算得到预测准确率。为消除选取测试集带来的偶然性,每次选取不同于上一次的2组,一共进行45次实验。
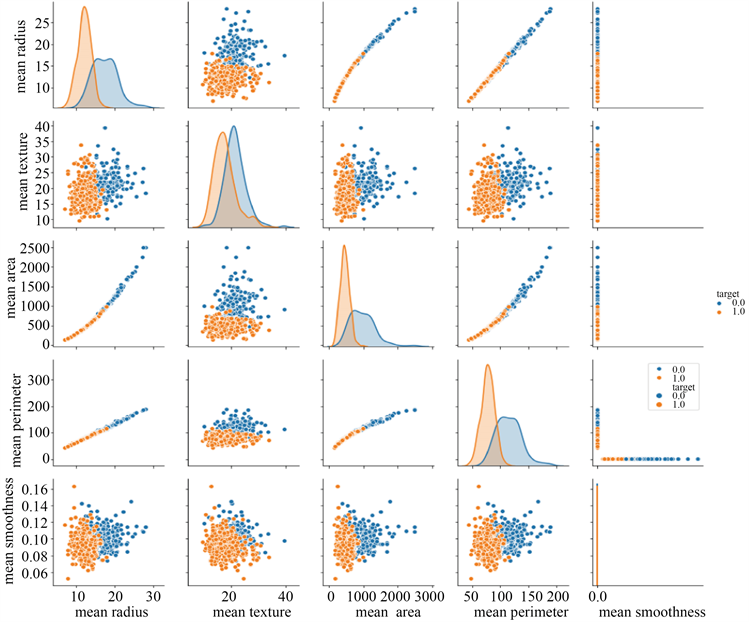
Figure 5. Scatter plot of partial attribute correlation
图5. 部分属性相关性散点图
(a) (b)
Table 2. Statistical description of PCA dimensionality reduction to 9-dimensional data
表2. PCA降维到9维数据统计描述
Figure 6. Nine-dimensional data distribution diagram
图6. 九维部分数据分布图
在2~9维数据集中,分别训练数据。可以得到各分类算法预测准确率的箱型图。仅展示6维各分类算法预测准确率箱型图。
见图7,可看出带有
正则项的RLR分类算法准确率平均值为0.955,带有
正则项的RLR分类算法准确率平均值为0.961,SVM分类算法准确率平均值为0.97。
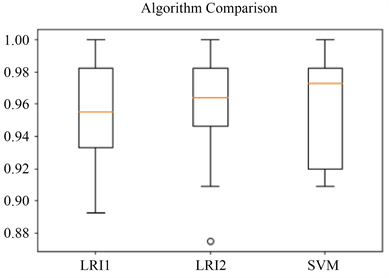
Figure 7. Box plot of the test accuracy of each six-dimensional classification algorithm
图7. 六维各分类算法测试准确率箱线图
将8次训练得到的准确率平均值,以折线图展示如图8:
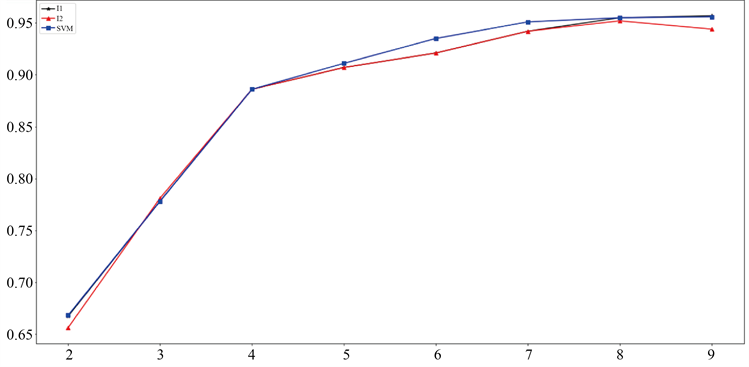
Figure 8. The prediction accuracy of each classification algorithm increases with the dimensionality line chart
图8. 各分类算法预测准确率随维度增加折线图
从图8中可以看出,在低维空间中两种分类算法的预测准确率几乎一致。随着维度的增加,分类算法的预测准确率均逐渐升高,且SVM算法呈现比较好的分类效果。
1) 含有离群值数据集
运用带有离群值的1060个样本进行同样的实验,可以得到两种分类算法预测准确率随维度增加的折线图。
通过对比图8和图9,可以得到SVM算法在离群值的影响下,依旧保持很好的分类效果,而RLR则受到一定程度的影响,因此,在乳腺癌数据集中,SVM分类算法更具有鲁棒性。

Figure 9. The prediction accuracy of each classification algorithm increases with the dimensionality line chart
图9. 各分类算法预测准确率随维度增加折线图
4.3. 高维小样本数据集上的分类效果比较
由于乳腺癌数据集不属于高维小样本数据,因此采用来自天津大学医学部发布的阿尔兹海默症数据集,有111个样本数据,其中每个数据有11,340个特征变量,部分数据展示如表3:
Table 3. Partial data of Alzheimer’s disease data set
表3. 阿尔兹海默症数据集部分数据
由于维度过大,只展示部分维度数据统计描述,见表4:
Table 4. Statistical description of some data of Alzheimer’s disease
表4. 阿尔兹海默症部分数据统计描述
对这一数据集进行训练,同样采用十折交叉验证,选择2组作为测试集,得到分类准确率,以箱线图展示:
图10中可以看出,带l1惩罚的RLR分类算法的预测准确率浮动最大,最低为0.8,最高为0.93,平均值为0.901;带l2惩罚的RLR分类算法的预测准确率浮动较大,最低为0.865,最高为0.962,平均值为0.903;SVM分类算法的预测准确率一直在0.89附近。出现该结果的原因是,SVM中采用hinge损失,会出现样本堆积,使得在样本量非常少的情况下,参与学习分类边界的数据点更加少,因此,在高维小样本数据中,SVM表现会很差,而RLR呈现更加优秀的预测效果。
4.4. 分类算法复杂性比较
采用威斯康辛乳腺癌数据集,可以得到测试运行时间和占用内存,如表5中所示。
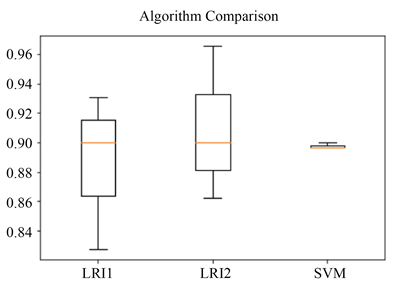
Figure 10. Box plot of prediction accuracy of each classification algorithm
图10. 各分类算法预测准确率箱线图
表5中可以看出,在同等情况下,SVM的运行时间长但占用内存较小,RLR的运行时间短,但占有内存高。在低维大样本情况下,SVM的表现更好,在高维小样本情况下,RLR的表现更好。这与文献 [9] 中所呈现的结果有相似的表现。
5. 结论
在机器学习领域中,支持向量机和逻辑回归作为两种有监督的分类算法,各有千秋,其本质区别是损失函数的不同,SVM采用hinge损失函数,RLR采用对数损失函数,使得两者在不同的场合下有着不同的分类效果。以探究两者的区别和应用场景为出发点,进行仿真实验。在2~9维、699个不含有离群值乳腺癌样本数据中,得到结论为随着维度的升高SVM的预测准确率逐渐高于RLR;加入离群值数据,得到1060个样本,在有离群值的影响下,SVM呈现稳定的性能,因此SVM分类算法更具鲁棒性;在11,340维、111个样本的高维小样本阿尔兹海默症数据集中,进行交叉验证,发现RLR的稳定性更高,分类效果更好;在威斯康辛乳腺癌数据实践中,SVM算法计算复杂度比较高,运行时间更长,占有内存较小,而RLR运行时间更短,占有内存较大。